Les grands modèles de langage (LLM) ont évolué pour devenir des systèmes multimodaux, étendant leur portée au-delà du texte pour comprendre et générer des images, de la musique et de la parole. Cependant, le défi consiste à condenser la complexité et les nuances émotionnelles de la parole humaine dans un format rapide à traiter sans perdre les détails subtils.
Ce billet de blog présente FocalCodec, notre nouvelle méthode pour compresser la parole sans sacrifier la qualité, en vue d'obtenir des LLM multimodaux plus efficaces.
Tokens audio : comment intégrer de l'audio dans un LLM?
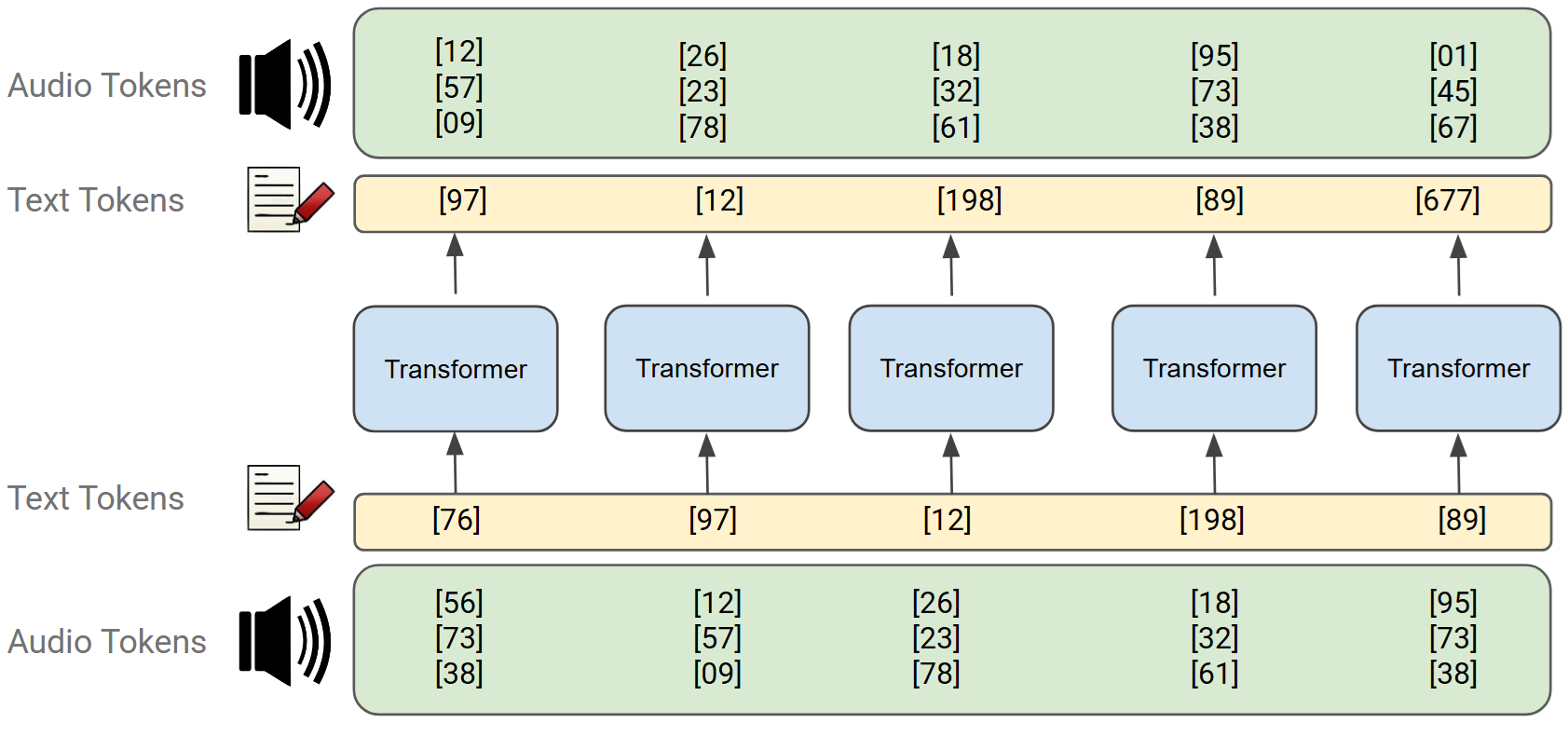
Pour doter les LLM multimodaux de la capacité d'entendre et de parler, l'audio brut est converti en petits « blocs de construction » appelés tokens audio. De la même manière que l'on assemble des mots pour former une phrase, les tokens décomposent la parole en segments discrets qu'un modèle peut traiter.
Ces tokens sont ensuite directement fournis à un LLM standard, comme le montre la figure ci-dessous.
Les limites des tokens audio actuels
Bien que de nombreux chercheurs travaillent sur la tokenisation audio, les approches actuelles se heurtent encore à deux obstacles majeurs :
Une universalité limitée
Les modèles audio sont des spécialistes, pas des généralistes. Un modèle entraîné pour la reconnaissance de mots pourrait ne pas saisir les détails nécessaires pour synthétiser une voix naturelle, tandis qu'un autre, adapté à la génération de parole, pourrait ne pas capturer les indices émotionnels, rendant le modèle moins expressif ou empathique.
Cette « universalité limitée » signifie que nous n'avons pas encore trouvé de tokenizer audio qui capture l'intégralité des informations.
Des débits binaires élevés
Parce que la parole transporte une énorme quantité d'informations, les méthodes actuelles génèrent un grand nombre de tokens pour chaque seconde d'audio, ce que l'on appelle un débit binaire (bitrate) élevé.
Un débit élevé, c'est comme surcharger une valise de nombreux petits objets pour un voyage d'une journée, y compris des choses que vous n'utiliserez probablement pas. Inversement, un faible débit signifie n'emporter que l'essentiel, ce qui rend la valise plus légère et plus facile à transporter.
Étant donné que les LLM lisent et génèrent les tokens un par un, les débits élevés rendent l'entraînement et l'utilisation plus difficiles et plus coûteux en calcul. Pour compenser, certains modèles utilisent plusieurs flux de tokens simultanés, chacun avec son propre vocabulaire. Cela augmente le nombre total de tokens et complexifie l'architecture du modèle par rapport aux LLM purement textuels.
Pour relever ces défis, nous avons développé FocalCodec, une nouvelle méthode de tokenisation qui améliore la manière dont la parole est compressée et représentée pour les LLM multimodaux.
Notre contribution
FocalCodec représente une avancée vers des tokenizers audio plus universels. Nos principaux résultats, résumés dans un article pour la conférence NeurIPS 2025, montrent que le modèle capture de multiples aspects de l'information vocale, tels que les mots, les phonèmes, l'identité du locuteur, l'émotion et même la langue. Cela lui permet d'être très performant à la fois sur des tâches discriminatives (comme la reconnaissance de la parole ou la détection d'émotions) et des tâches génératives (comme la synthèse vocale de haute qualité).
Ce qui rend cette performance particulièrement remarquable, c'est que FocalCodec y parvient avec un débit ultra-faible. Il produit moins de tokens que la plupart des approches précédentes tout en préservant la richesse de la parole originale.
Fait intéressant, FocalCodec un flux unique de tokens audio, plutôt que d'empiler plusieurs flux comme le font de nombreuses méthodes antérieures. Cela simplifie considérablement l'intégration de l’audio dans les LLM standards, réduisant la complexité architecturale, la charge de calcul et les débits.
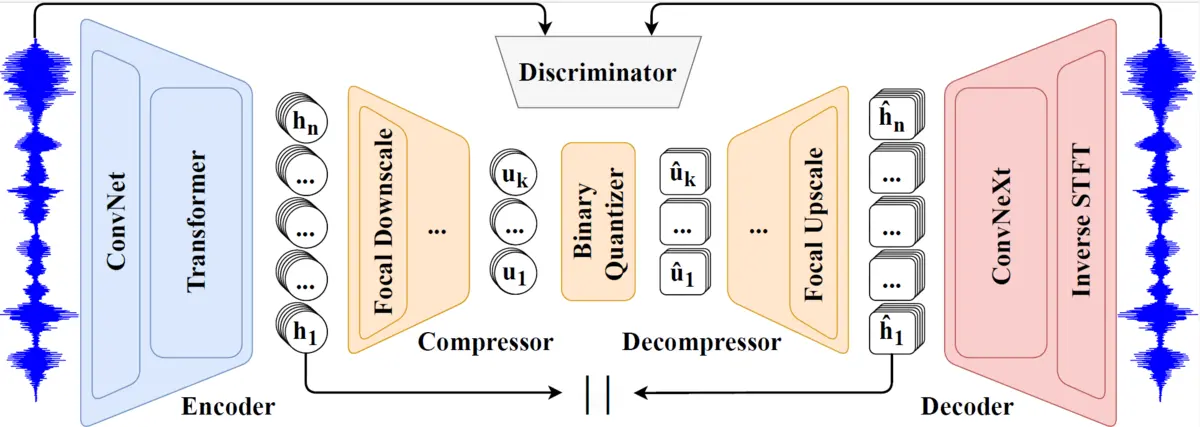
Comment fonctionne FocalCodec?
Comme la plupart des tokenizers audio modernes, FocalCodec suit une architecture en trois étapes :
- Un encodeur qui convertit la forme d'onde brute de la parole en une représentation continue et compacte.
- Un quantificateur qui transforme cette représentation continue en unités discrètes (les jetons audio).
- Un décodeur qui tente de reconstruire la forme d'onde originale à partir des jetons quantifiés.
Ce qui rend FocalCodec intéressant, c'est la manière dont ces composants sont conçus et combinés pour atteindre la robustesse, l'efficacité de calcul et un débit ultra-faible.
Quantification sphérique binaire
Une innovation clé de FocalCodec est une technique appelée quantification sphérique binaire2, appliquée pour la première fois à la parole. Après avoir projeté la représentation continue fournie par l'encodeur sur une sphère d’unité à D dimensions, chaque dimension est quantifiée indépendamment de manière simple :
- Si la valeur est positive → assigner +1 / √D
- Si la valeur est négative → assigner -1 / √D
À première vue, cela peut sembler une manière grossière de quantifier l'audio. Mais étonnamment, cela fonctionne très bien. Parce qu'elle ne repose pas sur l'apprentissage d'un vocabulaire (contrairement aux quantificateurs vectoriels classiques), cette méthode maintient le débit extrêmement bas tout en préservant les informations essentielles de la parole.
Modulation focale
Pour améliorer encore l'efficacité, nous utilisons des couches de modulation focale (Focal Modulation)3,4 dans l'encodeur et le décodeur. Ces couches agissent comme une alternative légère aux mécanismes d'auto-attention (self-attention), réduisant considérablement le coût de calcul tout en maintenant une forte capacité de modélisation.
Exploitation des caractéristiques de la parole auto-supervisées
Pour des performances encore meilleures, nous initialisons les premières couches de l'encodeur en utilisant les six premières couches de WavLM5, un modèle de parole auto-supervisé de pointe, reconnu pour ses excellentes performances sur un large éventail de tâches. Cela donne à FocalCodec une base solide pour représenter les informations phonétiques et liées au locuteur.
Performances
Nous avons évalué FocalCodec sur un large éventail de tâches, notamment la reconnaissance de la parole (ASR), l'identification du locuteur (SI), la reconnaissance des émotions dans la parole (SER), l'amélioration de la parole (SE), la séparation de la parole (SS) et la synthèse vocale (TTS). Sur toutes ces tâches, FocalCodec offre des performances compétitives à des débits ultra-faibles, tout en maintenant sa robustesse face à différentes tâches, comme le montre le tableau ci-dessous :
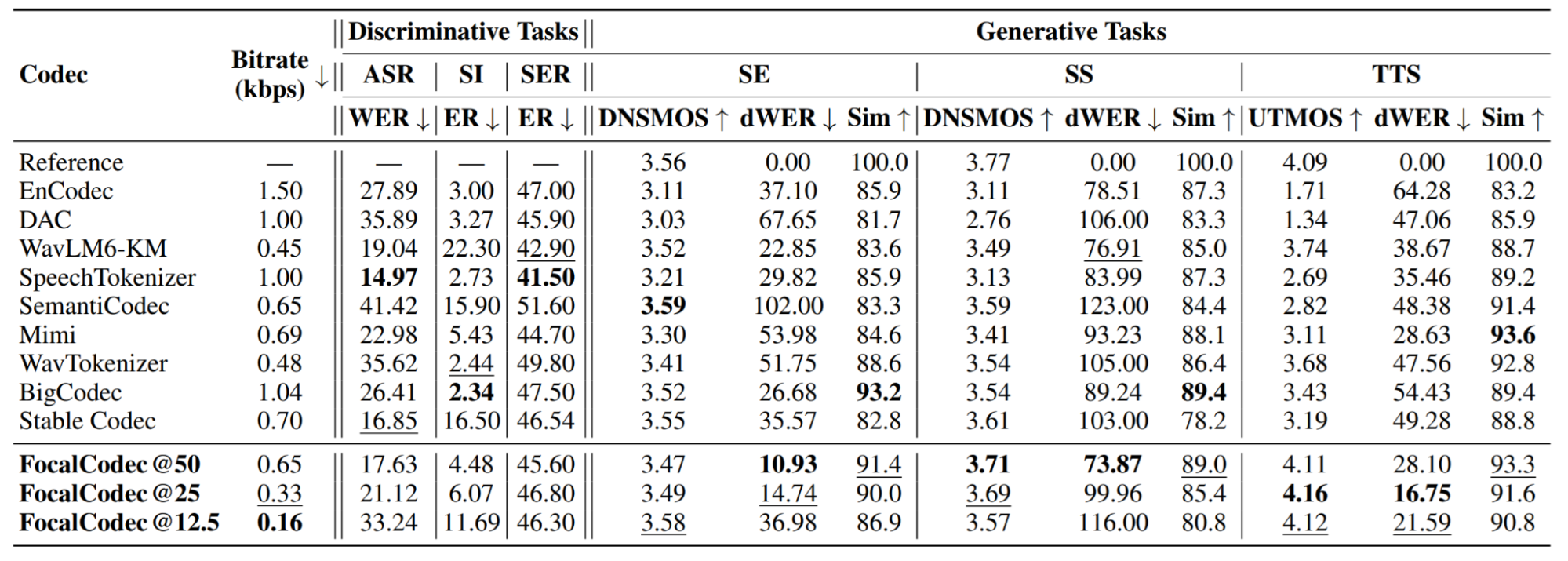
Le tableau compare FocalCodec à d'autres tokenizers audio populaires fonctionnant à des débits relativement bas. Sur un ensemble de tâches et de métriques de performance, FocalCodec excelle dans les tâches génératives, tout en restant très compétitif dans les tâches discriminatives. Globalement, il offre un excellent équilibre entre performance et efficacité, fournissant de solides résultats sans nécessiter un débit élevé.
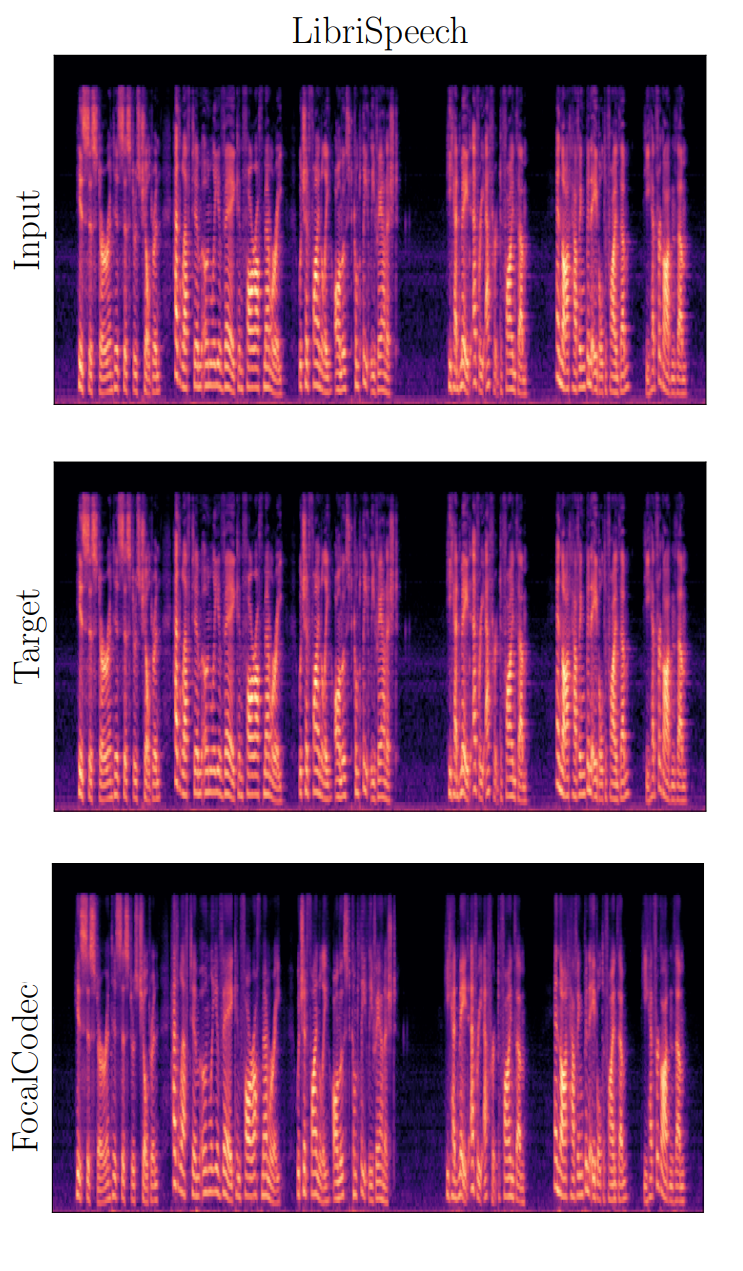
Sur cette figure, nous présentons un résultat qualitatif montrant que FocalCodec peut compresser et reconstruire la parole avec une perte de qualité minimale. Comme vous pouvez le voir, les spectrogrammes du signal d'entrée, de la cible et du signal reconstruit par FocalCodec sont presque indiscernables.
Notre article inclut de nombreux résultats supplémentaires, tels que des analyses quantitatives de la reconstruction de la parole, des performances multilingues et des tests d'écoute. À travers toutes les évaluations, FocalCodec démontre constamment son efficacité.
Conclusion
FocalCodec montre qu'il est possible de compresser la parole à des débits extrêmement bas sans perdre la richesse de la communication humaine. En simplifiant la manière dont les tokens audio sont appris, notre travail ouvre la voie à des LLM multimodaux plus efficaces, évolutifs et robustes.
Notre équipe explore déjà des moyens d'améliorer FocalCodec, notamment en le rendant utilisable en flux continu (streamable), c'est-à-dire en calculant les tokens audio en temps réel à mesure que la parole est produite. Cela permettrait de créer des LLM multimodaux avec une latence plus faible et des interactions beaucoup plus naturelles et fluides.
Publication en Open Source
Nous avons rendu FocalCodec entièrement accessible à la communauté :
- Paper: https://arxiv.org/abs/2502.04465
- Training Code: https://github.com/speechbrain/speechbrain/tree/develop/recipes/LibriTTS/focalcodec
- Inference Code: https://github.com/lucadellalib/focalcodec
- Pretrained Model: https://huggingface.co/collections/lucadellalib/focalcodec
- Demo Samples: https://lucadellalib.github.io/focalcodec-web/
Référence
1 Luca Della Libera, Francesco Paissan, Cem Subakan, Mirco Ravanelli, "FocalCodec: Low-Bitrate Speech Coding via Focal Modulation Networks", Accepted at NeurIPS 2025, ArXiv.
2 Yue Zhao, Yuanjun Xiong, Philipp Krähenbühl, “Image and video tokenization with binary spherical quantization”, In Proceedings of the International Conference on Learning Representations (ICLR), 2025, ArXiv.
3 Jianwei Yang, Chunyuan Li, Xiyang Dai, Lu Yuan, Jianfeng Gao, "Focal modulation networks", In Proceedings of the International Conference on Neural Information Processing Systems (NeurIPS), 2022, ArXiv
4 Luca Della Libera, Cem Subakan, Mirco Ravanelli, “Focal modulation networks for interpretable sound classification”, In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing Workshops (ICASSPW), 2024, ArXiv.
5 Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Xiangzhan Yu, Furu Wei, "WavLM: Large-scale self-supervised pre-training for full stack speech processing", IEEE Journal of Selected Topics in Signal Processing, pages 1505–1518, 2022, ArXiv.