Le Fellowship Mila en politiques de l'IA transforme l'expertise approfondie en IA en politiques rigoureuses d'intérêt public. Découvrez la dernière publication Combler la disparité en matière d’expertise : mécanismes de transfert des connaissances pour la réglementation de l’IA par Moritz von Knebel.
Ce programme soutient les startups spécialisées en IA à tout moment de l'année. Bénéficiez de ressources de pointe et d'un accompagnement sur mesure pour accélérer le développement de votre technologie.
Offert par Mila et le Forum des politiques publiques, ce programme est conçu pour outiller les décideur·euse·s et les responsables des politiques publiques à naviguer efficacement à travers les opportunités et les risques liés à l'IA. La prochaine cohorte se tiendra en français les 1er et 2 septembre 2026 à Mila.
Nous utilisons des témoins pour analyser le trafic et l’utilisation de notre site web, afin de personnaliser votre expérience. Vous pouvez désactiver ces technologies à tout moment, mais cela peut restreindre certaines fonctionnalités du site. Consultez notre Politique de protection de la vie privée pour en savoir plus.
Paramètre des cookies
Vous pouvez activer et désactiver les types de cookies que vous souhaitez accepter. Cependant certains choix que vous ferez pourraient affecter les services proposés sur nos sites (ex : suggestions, annonces personnalisées, etc.).
Cookies essentiels
Ces cookies sont nécessaires au fonctionnement du site et ne peuvent être désactivés. (Toujours actif)
Cookies analyse
Acceptez-vous l'utilisation de cookies pour mesurer l'audience de nos sites ?
Lecteur Multimédia
Acceptez-vous l'utilisation de cookies pour afficher et vous permettre de regarder les contenus vidéo hébergés par nos partenaires (YouTube, etc.) ?
Neural audio codecs provide compact discrete representations for speech generation and manipulation. However, most codecs organize tokens as… (voir plus) frame-level sequences, making it difficult to study or intervene on global factors of variation. In this work, we propose the Latent Audio Tokenizer for Token-space Editing (LATTE) that appends a fixed set of learnable latent tokens to the audio feature sequence and retains only these tokens for quantization and decoding. This design produces a compact, non-temporally aligned bottleneck in which each token can aggregate global information across the full utterance. We show that the resulting tokenizer preserves competitive reconstruction quality in low-bitrate speech coding settings while enabling simple token-space interventions. In particular, we find that swapping selected latent token positions between utterances can modify global attributes, such as speaker identity and background noise, and we evaluate these interventions on voice conversion and denoising tasks. Our results suggest that compact latent audio tokenizers can support controllable audio manipulation without supervision in task-specific editing models.
Free-form, text-based audio editing remains a persistent challenge, despite progress in inversion-based neural methods. Current approaches r… (voir plus)ely on slow inversion procedures, limiting their practicality. We present a virtual-consistency based audio editing system that bypasses inversion by adapting the sampling process of diffusion models. Our pipeline is model-agnostic, requiring no fine-tuning or architectural changes, and achieves substantial speed-ups over recent neural editing baselines. Crucially, it achieves this efficiency without compromising quality, as demonstrated by quantitative benchmarks and a user study involving 16 participants.
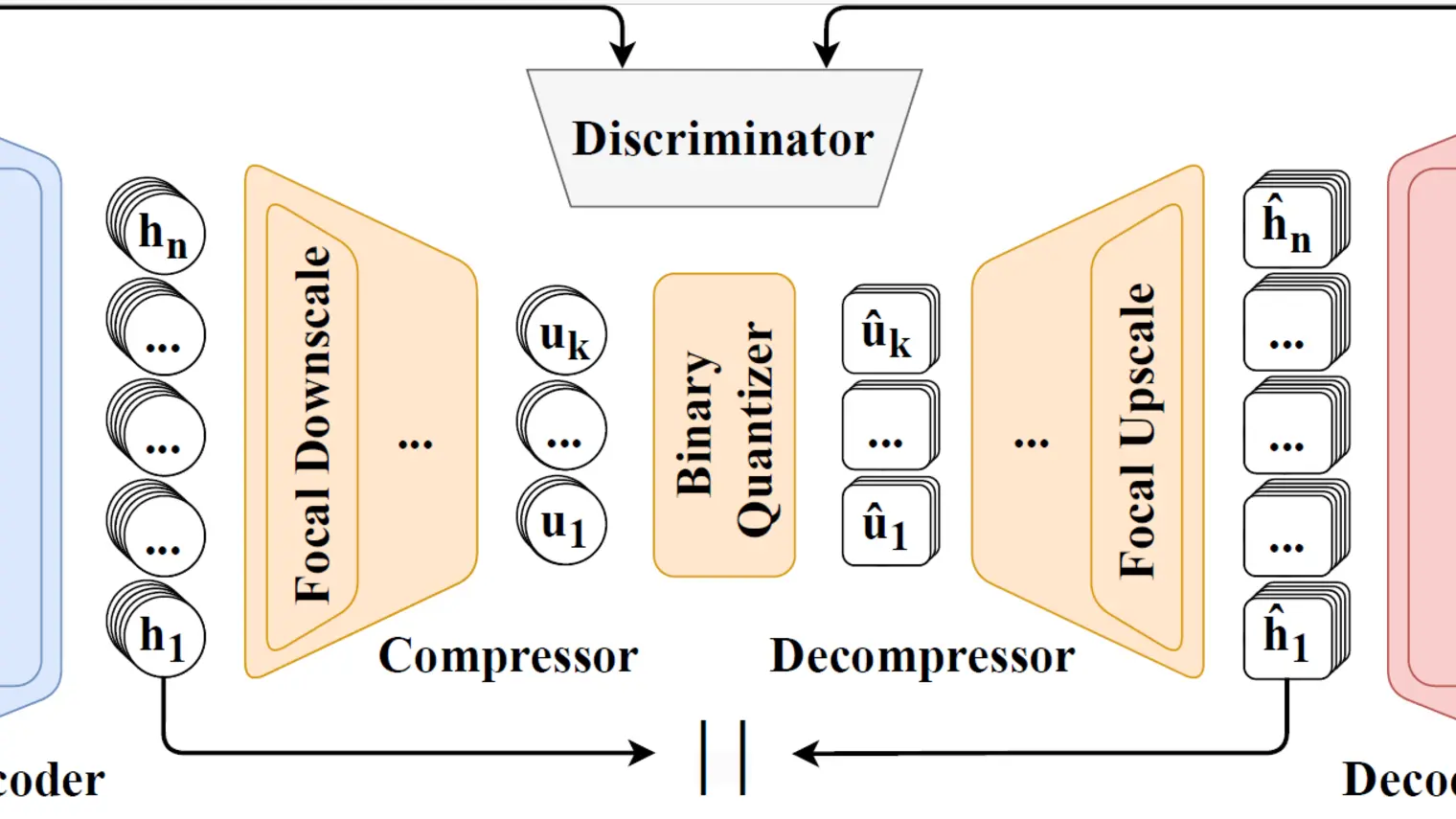
Large language models have revolutionized natural language processing through self-supervised pretraining on massive datasets. Inspired by t… (voir plus)his success, researchers have explored adapting these methods to speech by discretizing continuous audio into tokens using neural audio codecs. However, existing approaches face limitations, including high bitrates, the loss of either semantic or acoustic information, and the reliance on multi-codebook designs when trying to capture both, which increases architectural complexity for downstream tasks. To address these challenges, we introduce FocalCodec, an efficient low-bitrate codec based on focal modulation that utilizes a single binary codebook to compress speech between 0.16 and 0.65 kbps. FocalCodec delivers competitive performance in speech resynthesis and voice conversion at lower bitrates than the current state-of-the-art, while effectively handling multilingual speech and noisy environments. Evaluation on downstream tasks shows that FocalCodec successfully preserves sufficient semantic and acoustic information, while also being well-suited for generative modeling. Demo samples and code are available at https://lucadellalib.github.io/focalcodec-web/.
Speech impairments in Parkinson's disease (PD) provide significant early indicators for diagnosis. While models for speech-based PD detectio… (voir plus)n have shown strong performance, their interpretability remains underexplored. This study systematically evaluates several explainability methods to identify PD-specific speech features, aiming to support the development of accurate, interpretable models for clinical decision-making in PD diagnosis and monitoring. Our methodology involves (i) obtaining attributions and saliency maps using mainstream interpretability techniques, (ii) quantitatively evaluating the faithfulness of these maps and their combinations obtained via union and intersection through a range of established metrics, and (iii) assessing the information conveyed by the saliency maps for PD detection from an auxiliary classifier. Our results reveal that, while explanations are aligned with the classifier, they often fail to provide valuable information for domain experts.
2025-04-05
2025 IEEE International Conference on Acoustics, Speech, and Signal Processing Workshops (ICASSPW) (publié)
Neural networks are typically black-boxes that remain opaque with regards to their decision mechanisms. Several works in the literature have… (voir plus) proposed post-hoc explanation methods to alleviate this issue. This paper proposes LMAC-TD, a post-hoc explanation method that trains a decoder to produce explanations directly in the time domain. This methodology builds upon the foundation of L-MAC, Listenable Maps for Audio Classifiers, a method that produces faithful and listenable explanations. We incorporate SepFormer, a popular transformer-based time-domain source separation architecture. We show through a user study that LMAC-TD significantly improves the audio quality of the produced explanations while not sacrificing from faithfulness.
2025-04-05
ICASSP 2025 - 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (publié)
Interpreting the decisions of deep learning models, including audio classifiers, is crucial for ensuring the transparency and trustworthines… (voir plus)s of this technology. In this paper, we introduce LMAC-ZS (Listenable Maps for Audio Classifiers in the Zero-Shot context), which, to the best of our knowledge, is the first decoder-based post-hoc interpretation method for explaining the decisions of zero-shot audio classifiers. The proposed method utilizes a novel loss function that maximizes the faithfulness to the original similarity between a given text-and-audio pair. We provide an extensive evaluation using the Contrastive Language-Audio Pretraining (CLAP) model to showcase that our interpreter remains faithful to the decisions in a zero-shot classification context. Moreover, we qualitatively show that our method produces meaningful explanations that correlate well with different text prompts.
In this paper, we explore audio-editing with non-rigid text edits. We show that the proposed editing pipeline is able to create audio edits … (voir plus)that remain faithful to the input audio. We explore text prompts that perform addition, style transfer, and in-painting. We quantitatively and qualitatively show that the edits are able to obtain results which outperform Audio-LDM, a recently released text-prompted audio generation model. Qualitative inspection of the results points out that the edits given by our approach remain more faithful to the input audio in terms of keeping the original onsets and offsets of the audio events.
Despite the impressive performance of deep learning models across diverse tasks, their complexity poses challenges for interpretation. This … (voir plus)challenge is particularly evident for audio signals, where conveying interpretations becomes inherently difficult. To address this issue, we introduce Listenable Maps for Audio Classifiers (L-MAC), a posthoc interpretation method that generates faithful and listenable interpretations. L-MAC utilizes a decoder on top of a pretrained classifier to generate binary masks that highlight relevant portions of the input audio. We train the decoder with a loss function that maximizes the confidence of the classifier decision on the masked-in portion of the audio while minimizing the probability of model output for the masked-out portion. Quantitative evaluations on both in-domain and out-of-domain data demonstrate that L-MAC consistently produces more faithful interpretations than several gradient and masking-based methodologies. Furthermore, a user study confirms that, on average, users prefer the interpretations generated by the proposed technique.
2024-07-07
Proceedings of the 41st International Conference on Machine Learning (publié)
SpeechBrain is an open-source Conversational AI toolkit based on PyTorch, focused particularly on speech processing tasks such as speech rec… (voir plus)ognition, speech enhancement, speaker recognition, text-to-speech, and much more. It promotes transparency and replicability by releasing both the pre-trained models and the complete "recipes" of code and algorithms required for training them. This paper presents SpeechBrain 1.0, a significant milestone in the evolution of the toolkit, which now has over 200 recipes for speech, audio, and language processing tasks, and more than 100 models available on Hugging Face. SpeechBrain 1.0 introduces new technologies to support diverse learning modalities, Large Language Model (LLM) integration, and advanced decoding strategies, along with novel models, tasks, and modalities. It also includes a new benchmark repository, offering researchers a unified platform for evaluating models across diverse tasks.
In this paper, we introduce a new approach, called Posthoc Interpretation via Quantization (PIQ), for interpreting decisions made by trained… (voir plus) classifiers. Our method utilizes vector quantization to transform the representations of a classifier into a discrete, class-specific latent space. The class-specific codebooks act as a bottleneck that forces the interpreter to focus on the parts of the input data deemed relevant by the classifier for making a prediction. Our model formulation also enables learning concepts by incorporating the supervision of pretrained annotation models such as state-of-the-art image segmentation models. We evaluated our method through quantitative and qualitative studies involving black-and-white images, color images, and audio. As a result of these studies we found that PIQ generates interpretations that are more easily understood by participants to our user studies when compared to several other interpretation methods in the literature.