Large Language Models (LLMs) have evolved into multimodal systems, expanding their reach beyond text to understand and generate images, music and speech. However, the challenge is condensing the complexity and emotional nuances of human speech into a streamlined format that remains fast to process without losing the subtle details.
This blog post introduces FocalCodec, our new method for compressing speech without sacrificing quality for more efficient multimodal LLMs.
Audio Tokens: How Do We Feed Audio Into an LLM?
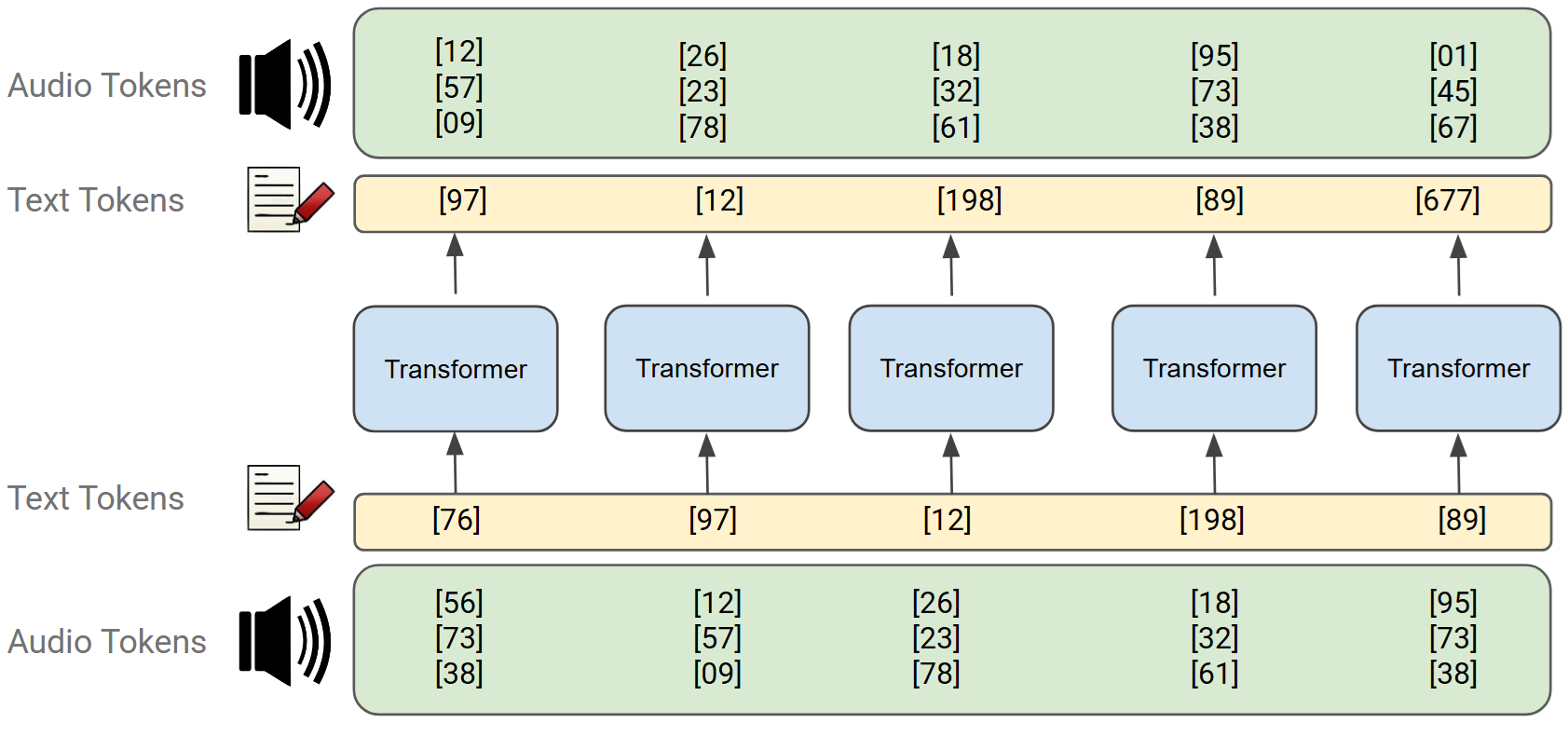
To give multimodal LLMs the ability to hear and speak, raw audio is converted into small “building blocks” known as audio tokens. Much like individual words are used to build a complete sentence, tokens break complex speech into discrete pieces that a model can process.
These tokens are then fed directly into a standard LLM, as shown in the figure below.
Limits of Current Audio Tokens
Several research groups have worked on improving audio tokenization, but current approaches still face two major limitations:
Limited Universality
Audio models are specialists, not generalists. A model trained for recognizing words may not capture the details needed to synthesize natural-sounding speech, while another suited for speech generation might not capture emotional cues, making the model less expressive or empathetic.
This “limited universality” means we haven’t yet found a single audio tokenizer that captures everything.
High Bitrates
Because speech carries a huge amount of information, current audio tokenizers produce many tokens for every second of audio, which is what we call a high bitrate.
High bitrate is like overpacking a suitcase with many small items for a 1-day trip, including things you probably won’t use. Conversely, low bitrate means packing only the essentials, making the suitcase lighter and easier to carry.
Because LLMs read and generate tokens one by one, high bitrates makes training and inference harder and more computationally expensive. To capture different aspects of speech, some models use multiple audio token streams, each with its own vocabulary. This increases the total number of tokens and makes the model architecture more complex compared to text-only LLMs.
To address these challenges, we developed FocalCodec, a new audio tokenization method that improves how speech is compressed and represented for multimodal LLMs.
Our Contribution
FocalCodec represents a step toward more universal audio tokenizers. Our main results, summarized in a NeurIPS 2025 paper, show that the model captures multiple aspects of speech information, such as words, phonemes, speaker identity, and emotion, and even language. This allows it to perform strongly on both discriminative tasks (like speech recognition or emotion detection) and generative tasks (such as high-quality speech synthesis).
What makes this particularly remarkable is that FocalCodec achieves all of this at an ultra-low bitrate. It produces fewer tokens than most previous approaches while preserving the richness of the original speech.
Interestingly, FocalCodec operates using a single audio-token stream, rather than stacking multiple streams as many previous methods do. This drastically simplifies how audio tokens are integrated into standard LLMs, reducing architectural complexity, computational overhead, and bit rates.
How Does FocalCodec Work?
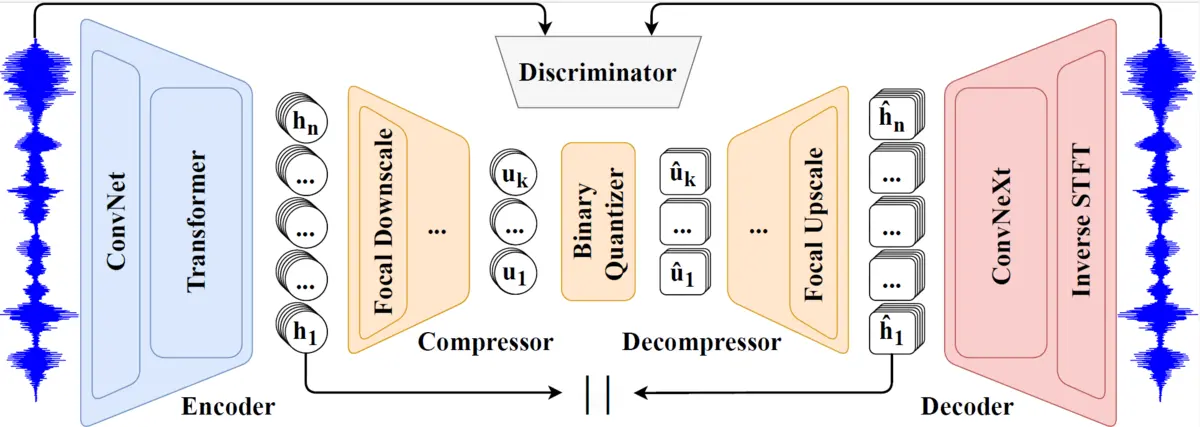
Like most modern audio tokenizers, FocalCodec follows a three-stage architecture:
- An Encoder that converts the raw speech waveform into a compact continuous representation.
- A Quantizer that turns this continuous representation into discrete units (the audio tokens).
- A Decoder that attempts to reconstruct the original waveform from the quantized tokens.
What makes FocalCodec interesting is how these components are designed and combined to achieve robustness, computational efficiency, and an ultra-low bitrate.
Binary Spherical Quantization
A key innovation in FocalCodec is a technique called binary spherical quantization2, applied to speech for the first time. After projecting the continuous representation provided by the encoder onto a D-dimensional unit sphere, each dimension is quantized independently in a remarkably simple way:
If the value is positive → assign +1 / √D
If the value is negative → assign -1 / √D
At first, this may seem like an extremely rough way to quantize audio. But surprisingly, it works very well. Because it does not rely on learning a vocabulary (unlike typical vector quantizers), it keeps the bitrate extremely low while still preserving essential speech information.
Focal Modulation
To further improve efficiency, we use Focal Modulation layers3,4 in both the encoder and decoder. These layers act as a lightweight alternative to self-attention, significantly reducing computational cost while maintaining strong modelling capacity.
Exploiting Self-Supervised Speech Features
For even better performance, we initialize the early encoder layers using the first six layers of WavLM5, a state-of-the-art self-supervised speech model known for its excellent performance on a wide range of tasks. This gives FocalCodec a strong foundation for representing phonetic, prosodic, and speaker-related information.
Performance
We evaluated FocalCodec across a broad set of downstream tasks, including speech recognition (ASR), speaker identification (SI) , speech emotion recognition (SER), speech enhancement (SE), speech separation (SS), and text-to-speech (TTS). Across all these tasks, FocalCodec provides competitive performance at ultra-low bitrates, while maintaining robustness to different downstream tasks, as shown in the table below:
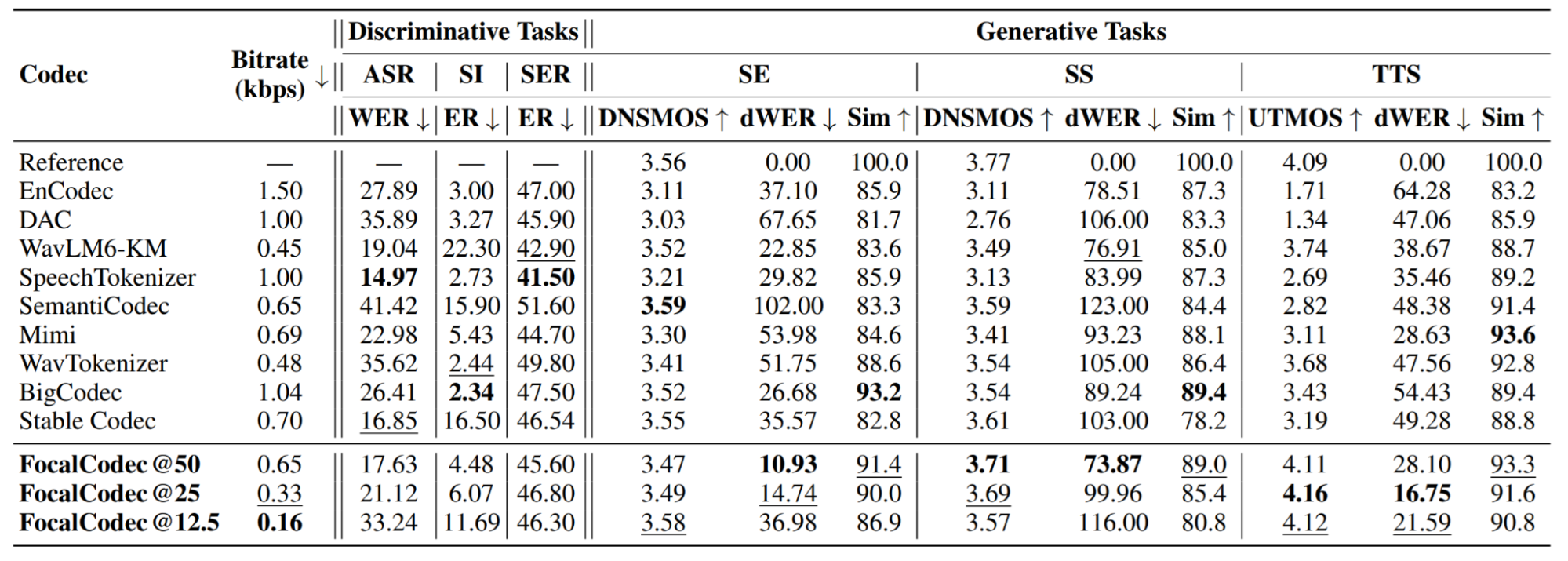
The table compares FocalCodec with other popular audio tokenizers that operate at relatively low bitrates. Across a range of tasks and performance metrics, FocalCodec excels in generative tasks, while maintaining high competitiveness in discriminative tasks. Overall, it offers an excellent balance between performance and efficiency, providing strong performance without requiring a high bitrate.
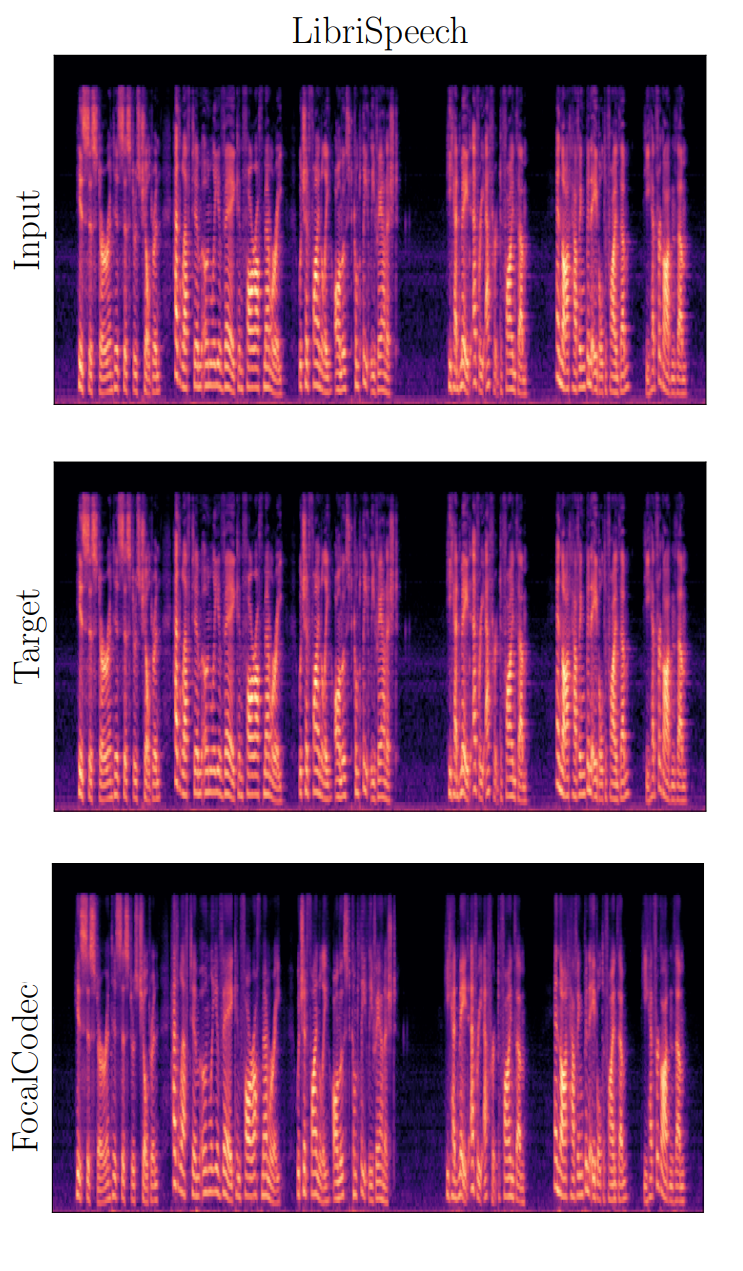
In the figure, we present a qualitative result showing that FocalCodec can compress and reconstruct speech with minimal loss in quality. As you can see, the spectrograms of the input, target, and FocalCodec-reconstructed signals are nearly indistinguishable.
Our paper includes many additional results, such as quantitative analyses of speech reconstruction, multilingual performance, and listening tests. Across all evaluations, FocalCodec consistently demonstrates its effectiveness.
Conclusion
FocalCodec shows that it is possible to compress speech to extremely low bitrates without losing the richness that makes human communication so expressive. By simplifying how audio tokens are learned, our work opens the door to more efficient, scalable, and robust Multimodal Large Language Models.
Our team is already exploring ways to further improve FocalCodec, including making it streamable (i.e., computing audio tokens in real-time as speech is being produced). This would enable multimodal LLMs with lower latency and far more natural, fluid interactions.
Open Source Release
We made FocalCodec fully available to the community:
- Paper: https://arxiv.org/abs/2502.04465
- Training Code: https://github.com/speechbrain/speechbrain/tree/develop/recipes/LibriTTS/focalcodec
- Inference Code: https://github.com/lucadellalib/focalcodec
- Pretrained Model: https://huggingface.co/collections/lucadellalib/focalcodec
- Demo Samples: https://lucadellalib.github.io/focalcodec-web/
Reference
1 Luca Della Libera, Francesco Paissan, Cem Subakan, Mirco Ravanelli, "FocalCodec: Low-Bitrate Speech Coding via Focal Modulation Networks", Accepted at NeurIPS 2025, ArXiv.
2 Yue Zhao, Yuanjun Xiong, Philipp Krähenbühl, “Image and video tokenization with binary spherical quantization”, In Proceedings of the International Conference on Learning Representations (ICLR), 2025, ArXiv.
3 Jianwei Yang, Chunyuan Li, Xiyang Dai, Lu Yuan, Jianfeng Gao, "Focal modulation networks", In Proceedings of the International Conference on Neural Information Processing Systems (NeurIPS), 2022, ArXiv
4 Luca Della Libera, Cem Subakan, Mirco Ravanelli, “Focal modulation networks for interpretable sound classification”, In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing Workshops (ICASSPW), 2024, ArXiv.
5 Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Xiangzhan Yu, Furu Wei, "WavLM: Large-scale self-supervised pre-training for full stack speech processing", IEEE Journal of Selected Topics in Signal Processing, pages 1505–1518, 2022, ArXiv.