



Note de la rédaction : Ce billet de blogue a été publié à l’origine sur le Blogue Tech d’Ubisoft Montréal le 12 août 2022 d’après ces travaux publiés récemment à l’occasion de l’International Conference on Machine Learning (ICML) 2022.
Article: https://proceedings.mlr.press/v162/roy22a
Code: https://github.com/ubisoft/directbehaviorspecification
L’apprentissage par renforcement devient de plus en plus populaire dans l’industrie du jeu vidéo, souvent dans la perspective de tests automatiques tels que la vérification de l’accessibilité, l’équilibrage des personnages, etc. La grande applicabilité de l’apprentissage par renforcement réside dans le fait qu’il nécessite un niveau de supervision plus faible : il est souvent plus facile de spécifier ce qu’il faut faire (apprentissage par renforcement) que la façon dont il faut le faire (apprentissage supervisé).
Cependant, dans les jeux vidéo complexes, il existe plusieurs exigences qu’un PNJ (personnage non joueur) doit suivre et la combinaison de ces exigences dans une seule fonction de récompense peut entraîner des comportements imprévus. Ces exigences sont particulièrement importantes si ces systèmes doivent être utilisés face à des joueurs réels. Par exemple, dans la vidéo ci-dessous, l’agent apprend avec succès à naviguer dans une carte complexe, mais se comporte de manière quelque peu inhabituelle en sautant même lorsque cela n’est pas nécessaire ou en oscillant fréquemment sa vue :

Dans cet autre exemple, un agent entraîné à jouer à For Honor apprend à s’enfuir pour mieux tendre une embuscade à son adversaire ; un comportement qui fonctionne dans ce cas particulier en trouvant un point faible de l’IA codée en dur mais qui ne corresond pas tout à fait à l’intention du concepteur:

L’émergence de ces comportements imprévus n’est pas un bug en soi : l’agent réussit à maximiser la fonction de récompense qui lui a été donnée. Le problème est que cette fonction de récompense a été mal spécifiée, c’est-à-dire qu’elle ne capture pas toujours correctement toutes les exigences de l’utilisateur. En fait, plus le comportement souhaité est complexe, plus il devient difficile de concevoir une bonne fonction de récompense qui mène à ce comportement.
Une approche plus directe de la spécification du comportement
Lors de la conception d’une fonction de récompense, les praticiens de la ML additionnent souvent un certain nombre de composants comportementaux jugés importants pour leur cas d’application :
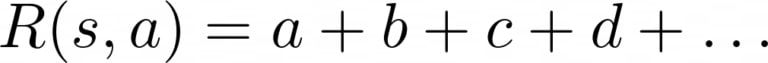
Le problème de l’addition de plusieurs composants comportementaux dans une seule fonction de récompense est que le choix de l’échelle relative de ces composants est souvent contre-intuitif. Par exemple, supposons que nous voulions que notre agent soit capable de naviguer sans sauter excessivement – quel degré de pénalité devons-nous attribuer au saut?
D’autre part, automatiser le processus en recherchant l’espace des coefficients de récompense est très inefficace car l’espace des combinaisons possibles croît de manière exponentielle avec le nombre de coefficients à régler.
Une solution pour trouver automatiquement les valeurs correctes des coefficients consiste à formuler les préférences comportementales supplémentaires sous forme de contraintes dures et à utiliser des méthodes lagrangiennes pour trouver une solution raisonnable à ce problème d’optimisation sous contrainte. Plus formellement, un processus de décision de Markov sous contrainte est constitué d’une fonction de récompense principale R à maximiser et de K contraintes supplémentaires à appliquer:
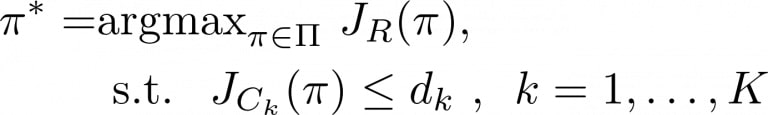
Cependant, cette formulation CMDP ne résout pas entièrement le problème car nous devons encore définir les seuils et les fonctions de coût. De plus, la méthode régulière de Lagrange peut devenir instable et inefficace lorsque l’on applique plusieurs contraintes. Dans ce travail, nous présentons un cadre pour la spécification directe du comportement qui repose sur les modifications suivantes.
1. Restreindre la famille des CMDP aux fonctions de coûts indicatrices
Un choix de conception efficace pour faciliter la tâche de spécification est d’implémenter les fonctions de coût pour les contraintes uniquement comme des fonctions indicatrices qu’un événement s’est produit dans une paire état-action donnée :
Une telle fonction est généralement simple à mettre en œuvre. Elle suppose seulement que nous puissions détecter le comportement que nous cherchons à faire respecter ! Il est important de noter qu’elle possède la propriété très utile que la somme actualisée attendue d’une fonction d’indicateur peut être interprétée comme la probabilité que l’agent présente ce comportement, rééchelonnée par une certaine constante de normalisation Z:
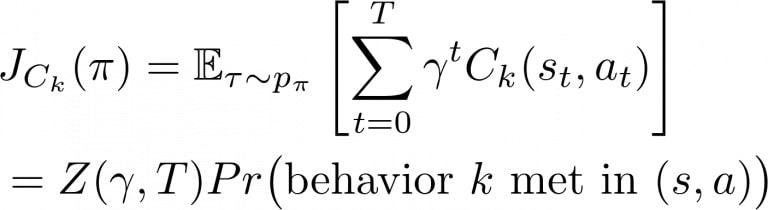
Nous pouvons facilement définir les seuils pour de telles contraintes en choisissant simplement la probabilité d’occurrence souhaitée de ce comportement (entre 0 et 1).
Dans notre exemple précédent, nous voulions limiter les sauts pendant la navigation. En utilisant ce cadre, nous pouvons fixer notre seuil de saut à 10 %, ce qui permettra à l’agent de sauter quand il en a absolument besoin, mais pas de façon excessive.
2. Multiplicateurs de Lagrange normalisés
L’un des problèmes de l’approche lagrangienne ordinaire est que les multiplicateurs des contraintes qui ne sont pas satisfaites vont continuer à augmenter jusqu’à ce que l’agent trouve finalement un moyen de les contrôler. Il est important de maintenir la capacité de tout multiplicateur de Lagrange à devenir arbitrairement plus grand que l’échelle de la fonction de récompense pour garantir que l’agent finira par se concentrer sur la satisfaction de ces contraintes. Cela conduit cependant à des instabilités dans la dynamique d’apprentissage lorsque ces multiplicateurs sont autorisés à augmenter pendant trop longtemps. Cela peut se produire dans le cas de contraintes impossibles à satisfaire, comme nous le simulons ici:
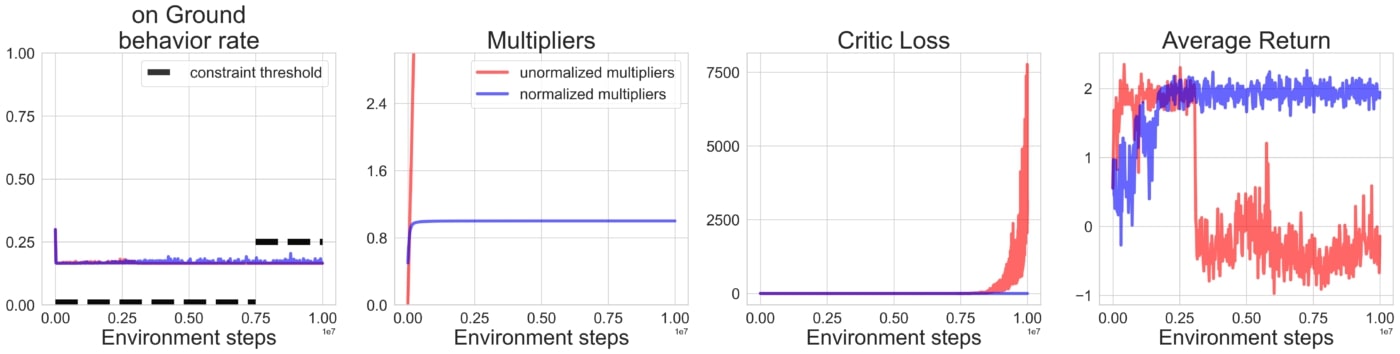
Une solution simple consiste à normaliser les multiplicateurs en les introduisant dans une couche softmax avant de les appliquer à la fonction Lagrangienne. De cette façon, les contraintes peuvent toujours finir par dominer les mises à jour de la politique tout en gardant une taille de pas limitée.
3. Contrainte bootstrap
Enfin, en présence de plusieurs contraintes, l’espace des politiques réalisables peut devenir très difficile à parcourir et même contenir des régions réalisables complètement déconnectées. Cela peut empêcher l’agent de progresser dans la tâche principale et rester bloqué dans des optima locaux peu performants.
Pour contourner ce problème, nous proposons d’ajouter à l’ensemble de contraintes une description éparse de la tâche à accomplir, qui amorcera l’apprentissage de la tâche principale pendant que l’agent cherche encore une politique réalisable. Le problème d’optimisation devient:
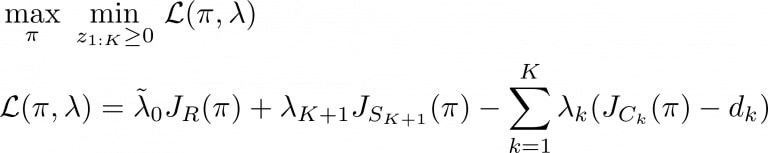
Le multiplicateur de la fonction de récompense principale est fixé au multiplicateur de la contrainte bootstrap lorsque l’agent a encore de mauvaises performances sur la tâche, et au complémentaire de tous les multiplicateurs des contraintes dans le cas contraire:
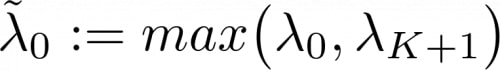
Résultats
Nous évaluons d’abord ce cadre dans l’environnement Arena. Dans l’arène, l’agent doit apprendre à naviguer vers son objectif tout en satisfaisant jusqu’à 5 contraintes comportementales:
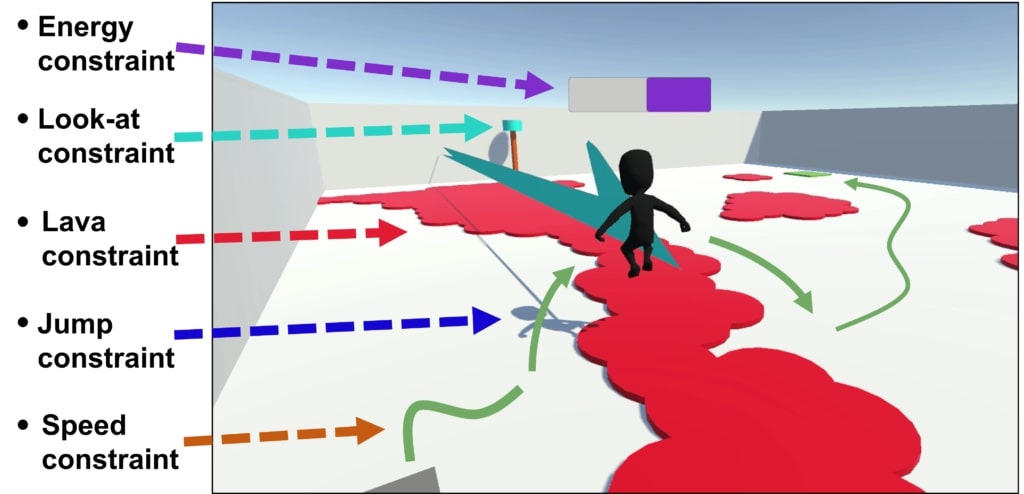
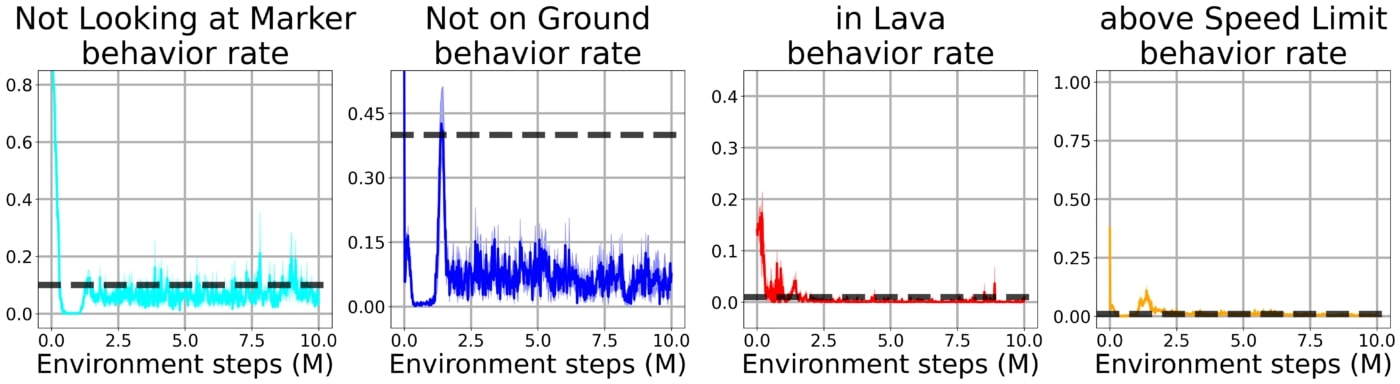
Si l’on entraine un agent uniquement sur la fonction de récompense principale sans enforcer aucune contrainte, le problème devient très facile à résoudre mais l’agent fait fi de toutes les préférences du concepteur en courant dans la lave, en épuisant son énergie et ainsi de suite:

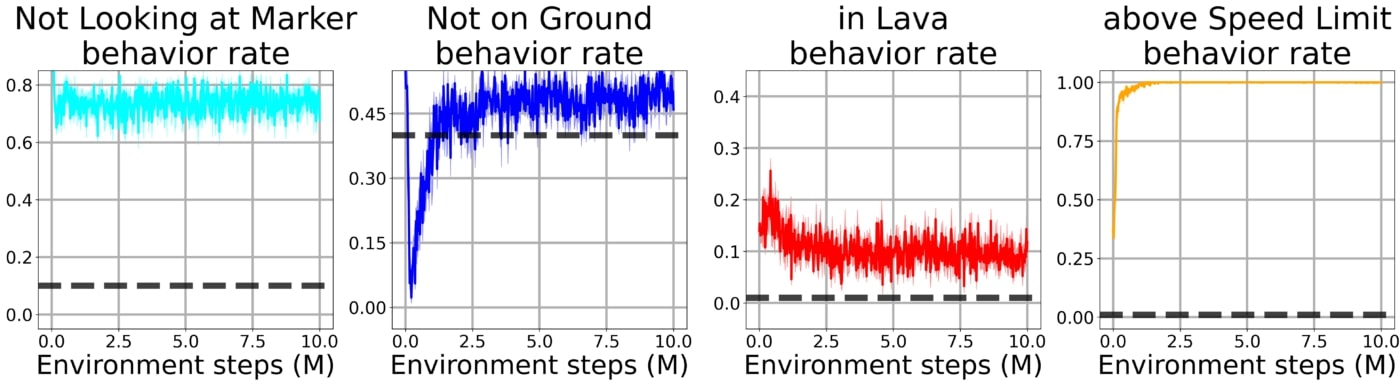
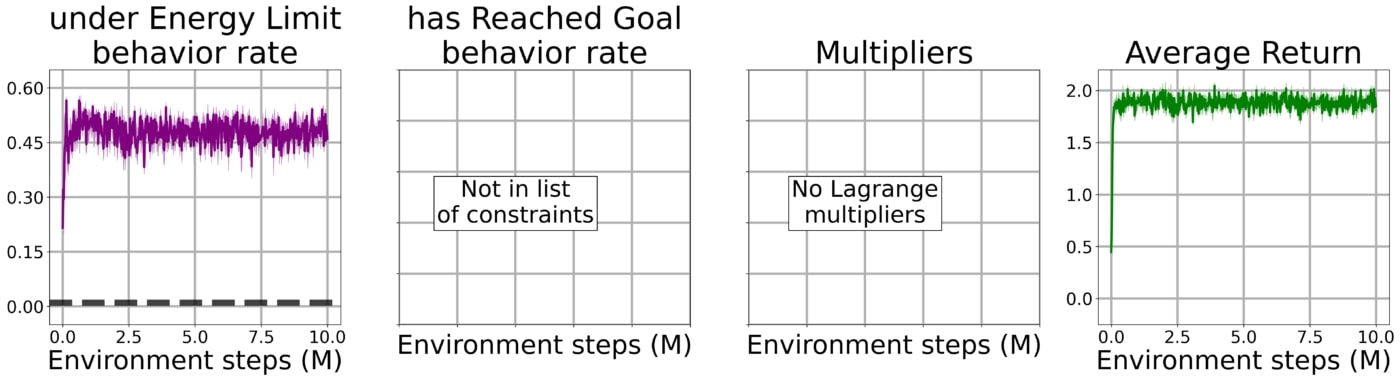
Quand l’on enforce les contraintes en utilisant la méthode de Lagrange de base, l’agent adopte un comportement trop conservateur pour éviter de violer les contraintes et ainsi n’apprend pas du tout à résoudre la tâche principale:
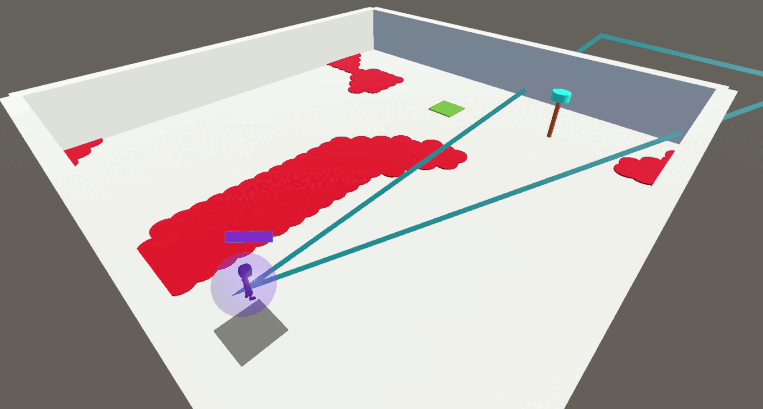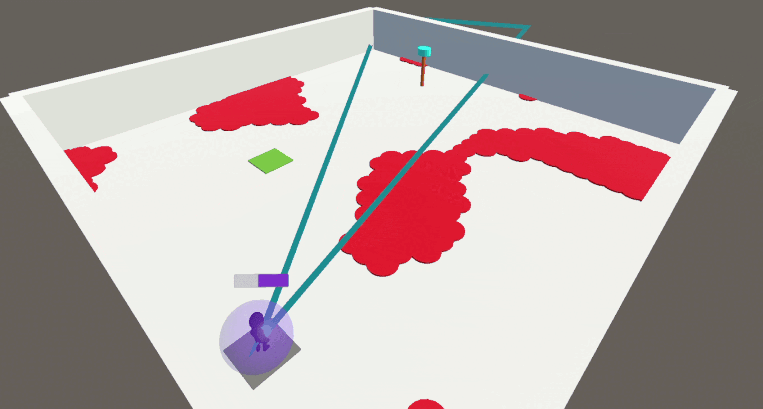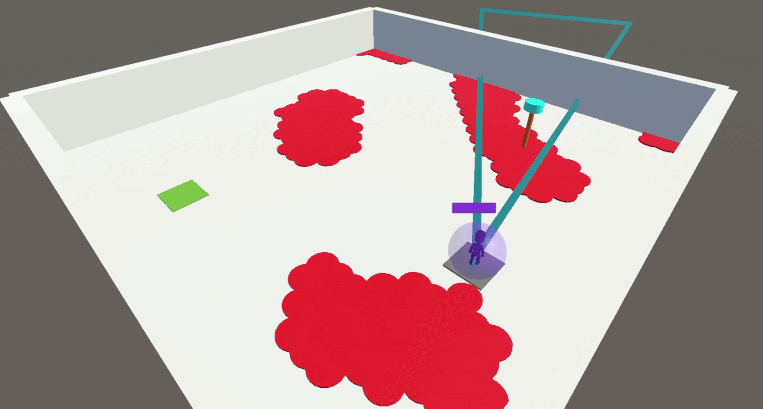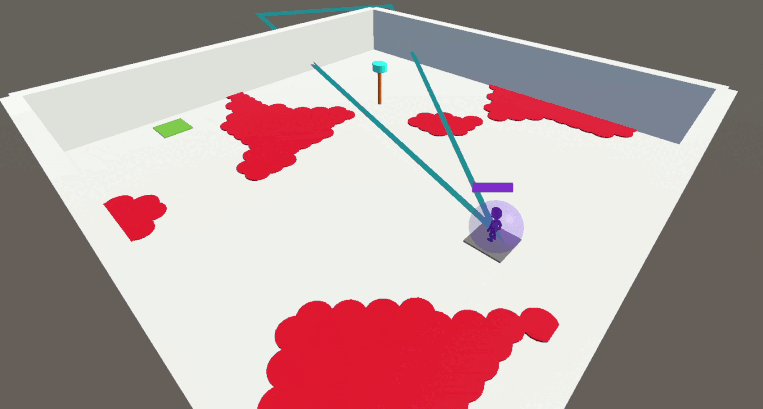
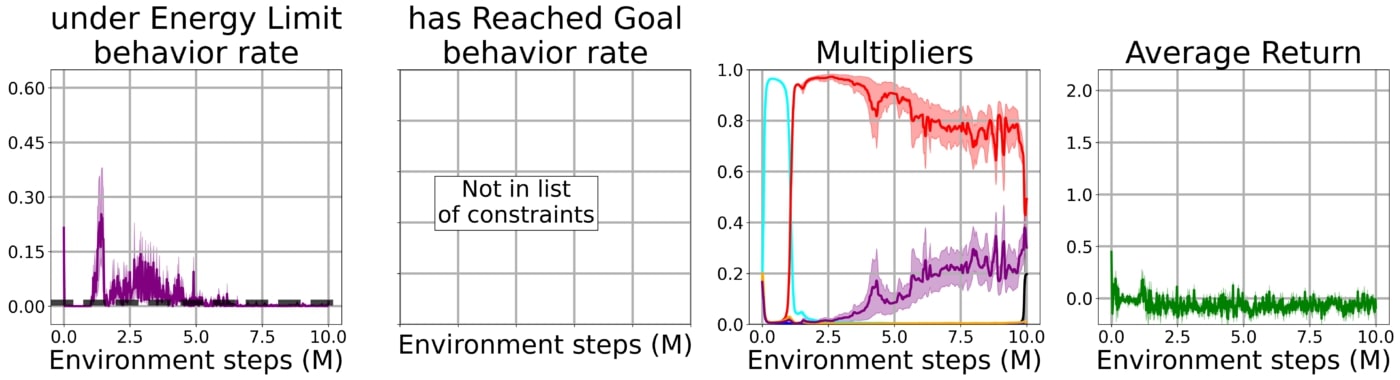
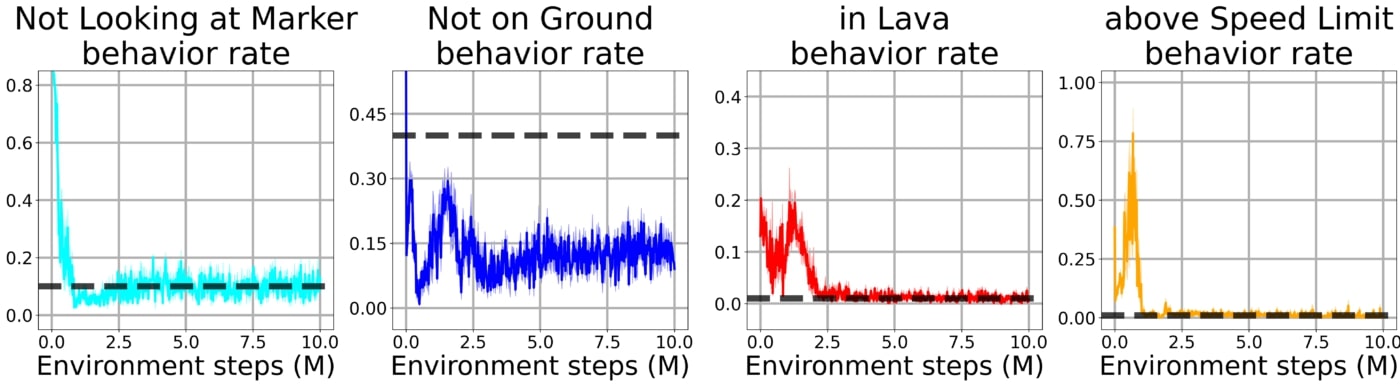
En utilisant notre approche avec la contrainte bootstrap, l’agent apprend rapidement à résoudre la tâche tout en étant soumis à toutes les contraintes simultanément.

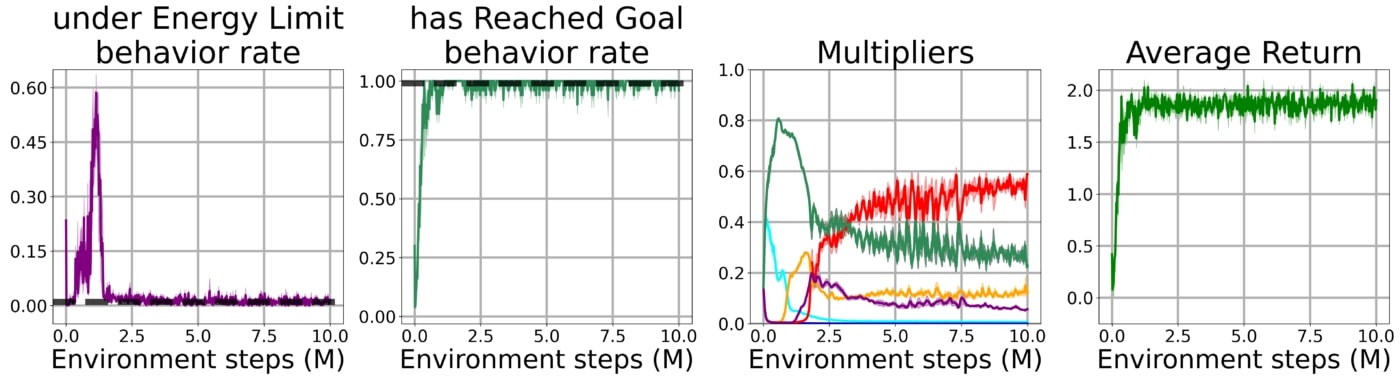
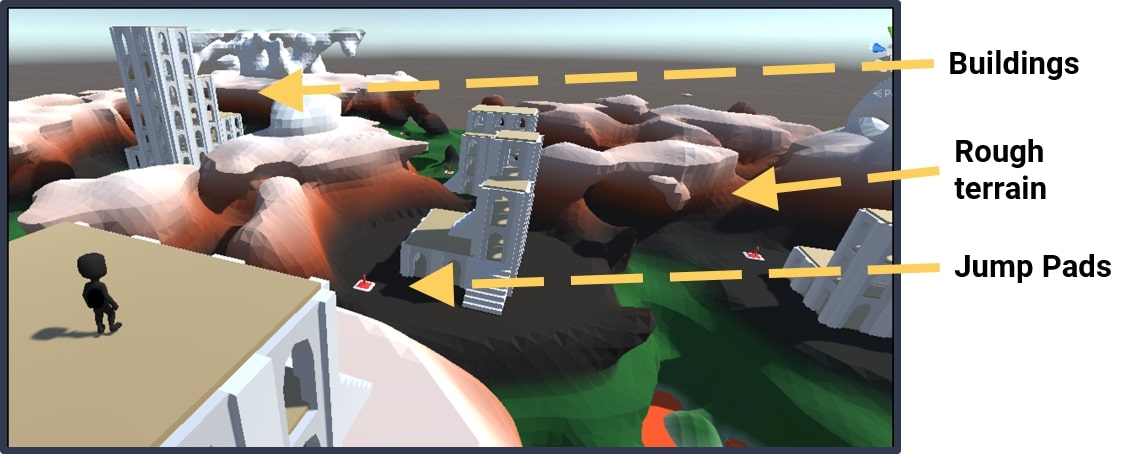
Nous vérifions également que cette méthode s’applique à des problèmes plus complexes en l’évaluant dans l’environnement OpenWorld. Contrairement à l’environnement Arena, ce monde représente maintenant une tâche de navigation 3D incorporant des caractéristiques telles qu’un terrain accidenté, des bâtiments et des tremplins:
Sans aucune modification des hyperparamètres de l’enveloppe lagrangienne, l’agent est à nouveau capable d’apprendre à résoudre la tâche tout en respectant les contraintes, ce qui montre que cette méthode peut être utilisée pour des tâches de contrôle très complexes.

Conclusion
Ce travail est une première étape dans la construction d’un cycle de développement meilleur et plus rapide pour l’application de la RL dans les jeux vidéo modernes. En permettant aux utilisateurs finaux d’interagir de manière plus intuitive avec l’interface de spécification des problèmes, et un cadre de spécification qui conduit de manière plus fiable au comportement attendu, nous pouvons réduire considérablement la quantité d’effort, de calcul et de temps nécessaire pour incorporer des PNJ formés à l’aide de l’apprentissage par renforcement.
Bibtex
@InProceedings{pmlr-v162-roy22a,
title = {Direct Behavior Specification via Constrained Reinforcement Learning},
author = {Roy, Julien and Girgis, Roger and Romoff, Joshua and Bacon, Pierre-Luc and Pal, Chris J},
booktitle = {Proceedings of the 39th International Conference on Machine Learning},
pages = {18828–18843},
year = {2022},
volume = {162},
publisher = {PMLR}
}


