


Note de la rédaction : Cet article a été accepté à ICLR 2024.
Chez l’être humain, la planification consciente décompose les tâches à long terme en étapes abstraites plus faciles à gérer, chacune d’entre elles pouvant être encore plus circonscrite. Un séjour dans une station balnéaire turque peut être bien réalisé si les billets d’avion, l’hébergement et les plans de voyage sont bien planifiés et respectés. Lors de l’achat des billets d’avion, nous ne prêtons pas nécessairement attention à d’autres facteurs non pertinents, comme le prix des chambres d’hôtel.
Ce type de planification s’intéresse aux points de décision importants (Sutton et al., 1999) et aux facteurs environnementaux pertinents qui relient les points de décision, fonctionnant ainsi de manière abstraite à la fois dans le temps et dans l’espace (Dehaene et al., 2020). À l’opposé, les agents d’apprentissage par renforcement existants fonctionnent soit uniquement sur la base de l’intuition (méthodes sans modèle, comme dans Kahneman, 2017), soit se limitent à raisonner sur des plans le plus souvent à relativement courte portée (méthodes fondées sur des modèles). Les limitations intrinsèques restreignent l’application de l’apprentissage par renforcement dans le monde réel sous un plafond de verre formé par les défis liés à la généralisation à long terme, au-dessous du niveau de raisonnement conscient de l’être humain.
Contribution principale
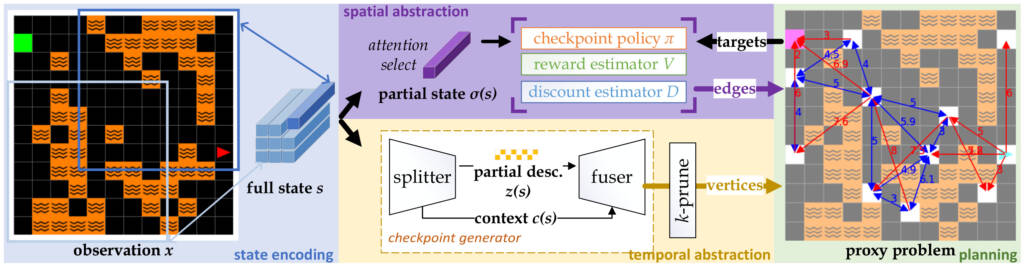
Inspirés par la prise de décision consciente chez l’être humain, nous développons un agent de planification qui décompose automatiquement la tâche complexe à accomplir en sous-tâches plus petites, en construisant des problèmes abstraits « intermédiaires », tout comme les êtres humains créent des versions abstraites de tâches compliquées. L’agent construit une structure interne qui représente le processus décisionnel destiné à résoudre des sous-objectifs précis qui se présentent et pour lesquels la logique est généralement réutilisable, ce que l’on appelle un problème intermédiaire.
Un problème intermédiaire est représenté sous la forme d’un graphe dont 1) les sommets sont constitués d’états proposés par un modèle génératif, correspondant à des points de décision dispersés; et 2) les arêtes, qui définissent des transitions étendues dans le temps, sont construites en se concentrant sur une petite quantité de renseignements pertinents provenant des états, à l’aide d’un mécanisme d’attention.
Une fois qu’un problème intermédiaire est construit et que l’agent s’en sert pour former un plan, chacune des arêtes définit un nouveau sous-problème, sur lequel l’agent se concentrera ensuite, par exemple, l’obtention de billets d’avion, la réservation de chambres d’hôtel. Cette stratégie « diviser pour régner » permet de construire des solutions partielles qui généralisent mieux lors de nouvelles situations (e.g., réutiliser la compétence d’achat de billets d’avion), tout en donnant à l’agent la souplesse nécessaire pour construire les abstractions nécessaires au problème en question (différents voyages doivent être planifiés différemment). Notre analyse théorique établit des garanties quant à la qualité de la solution au problème global.
Résultats expérimentaux
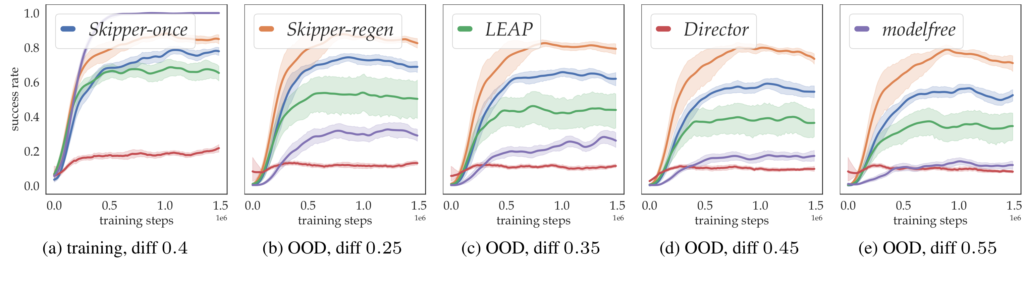
Nous examinons de manière empirique si notre méthode permet d’obtenir une généralisation de la distribution hors entraînement après l’utilisation de quelques tâches d’entraînement seulement. Nous montrons, au moyen d’expériences contrôlées détaillées, que Skipper obtient des résultats considérablement meilleurs en termes de généralisation zéro-coup lorsqu’il est entraîné sur un nombre raisonnable de tâches, par rapport aux points de référence et aux méthodes de planification hiérarchique de pointe :
LEAP (Nasiriany et al., 2019) utilise un algorithme évolutionnaire de recherche du plus court chemin pour effectuer la planification au moment de la décision. Cette stratégie imite l’évolution de l’ADN afin d’obtenir de meilleurs plans.
Director (Hafner et al., 2022) fait appel à la planification en arrière-plan et imagine, au moment de la décision, un état futur à certains pas de temps de distance qui servira d’objectif. Il utilise le modèle pour générer des données imaginaires supplémentaires sur lesquelles l’estimateur de valeur est entraîné.
À partir du contenu présenté dans l’annexe, nous déduisons également que :
l’abstraction spatiale fondée sur le champ de perception local est cruciale pour assurer la capacité des agents à fonctionner à différentes échelles;
Skipper obtient de bons résultats en décomposant de manière fiable les tâches données et en réalisant les sous-tâches de manière robuste. Sa performance est limitée par la précision des problèmes intermédiaires estimés ainsi que par les politiques de points de contrôle, qui correspondent respectivement à la généralisation des objectifs et à la généralisation des capacités. Cela correspond bien à notre théorie. La technique de suppression des délires proposée (en annexe) est efficace pour supprimer les plans dont les cibles sont des points de contrôle inexistants, ce qui accroît la précision des problèmes intermédiaires;
LEAP ne généralise pas bien dans sa forme originale et peut mieux généraliser lorsque sa compatibilité avec les états terminaux ainsi que la suppression des plans délirants sont améliorées;
Director peut mieux généraliser uniquement dans les domaines où la collecte de trajectoires longues et informatives est possible, en raison des caractéristiques de ses modèles d’espace d’état récurrents;
Nous avons vérifié de manière empirique que, comme prévu, Skipper est compatible avec la stochasticité.
Faits saillants (TL;DR)
Skipper permet d’obtenir une généralisation hors distribution zéro-coup supérieure. Les avantages de la généralisation proviennent principalement des sources suivantes :
Diviser pour régner motivé par la théorie : nous proposons des problèmes intermédiaires pour lesquels une stratégie de diviser pour régner pourrait être mise en œuvre dans le cadre d’un raisonnement à plus long terme en vue d’une meilleure généralisation. Des analyses théoriques sont présentées pour montrer le scénario applicable et les garanties de performance;
Abstraction spatio-temporelle : l’abstraction temporelle nous permet de décomposer la tâche donnée en tâches plus petites, tandis que l’abstraction spatiale portant sur les caractéristiques de l’état au moyen d’un mécanisme d’attention est utilisée pour améliorer l’apprentissage local et la généralisation;
La planification du moment de la décision est utilisée en raison de sa capacité à améliorer la politique dans des situations nouvelles;
Apprentissage de bout en bout à partir de l’expérience rétrospective, hors politique : pour maximiser l’efficacité de l’échantillonnage et faciliter l’entraînement, nous proposons d’utiliser des méthodes auxiliaires (hors politique) pour l’estimation des arêtes. Nous proposons également d’apprendre une génération de points de contrôle conditionnée par le contexte, à la fois à partir de la relecture de l’expérience rétrospective;
Des problèmes intermédiaires de meilleure qualité : nous introduisons des techniques d’élagage pour améliorer la dispersion des problèmes intermédiaires, ce qui se traduit par une meilleure qualité;
Suppression des délires: nous proposons une technique de suppression des délires afin de réduire au minimum le comportement consistant à poursuivre des résultats inexistants. Pour ce faire, on expose les estimateurs d’arêtes à des cibles qui, autrement, n’existeraient pas dans l’expérience.
(travaux réalisés en grande partie pendant la période où Harry, Harm et Romain travaillaient à MSR)
Il s’agit de notre deuxième travail de recherche portant sur l’intégration d’un comportement conscient de traitement de l’information dans les agents d’apprentissage par renforcement. Ce travail s’appuie sur nos travaux antérieurs sur l’abstraction spatiale dans le domaine de la planification (NeurIPS 2021). Il attire l’attention sur la dimension manquante de l’abstraction spatiale dans les cadres d’abstraction temporelle existants.


