


Editor's Note: This paper was accepted at ICLR 2024.
Human conscious planning breaks down long-horizon tasks into more manageable abstract steps, each of which can be narrowed down further. A trip to a Turkish beach resort can be well implemented if the flight tickets, accommodation, travel plans are well planned out and followed. When purchasing the flight tickets, we don’t necessarily pay attention to other irrelevant factors such as the price of the hotels.
This type of planning attends to important decision points (Sutton et al., 1999) and relevant environmental factors linking the decision points, thus operating abstractly both in time and in space (Dehaene et al., 2020). In contrast, existing RL agents either operate solely based on intuition (model-free methods, as in Kahneman, 2017) or are limited to reasoning over mostly relatively shortsighted plans (model-based methods). The intrinsic limitations constrain the application of RL in real-world under a glass ceiling formed by challenges of longer-term generalization, below the level of human conscious reasoning.
Core Contribution
Inspired by human conscious decision-making, we develop a planning agent that automatically decomposes the complex task at hand into smaller subtasks, by constructing abstract “proxy” problems, just like how humans create abstract versions of complicated tasks. The agent builds an internal structure that represents the decision process meant to solve specific sub-goals that arise and for which the logic is generally re-usable, which is named a proxy problem.
A proxy problem is represented as a graph where 1) the vertices consist of states proposed by a generative model, corresponding to sparse decision points; and 2) the edges, which define temporally-extended transitions, are constructed by focusing on a small amount of relevant information from the states, using an attention mechanism.
Once a proxy problem is constructed and the agent uses it to form a plan, each of the edges defines a new sub-problem, on which the agent will focus next, for example, getting flight tickets, booking hotels. This divide-and-conquer strategy allows constructing partial solutions that generalize better to new situations (e.g., reusing the skill of buying plane tickets), while also giving the agent flexibility to construct abstractions necessary for the problem at hand (different trips should be planned differently). Our theoretical analysis establishes guarantees on the quality of the solution to the overall problem.

Experimental Results
We examine empirically whether out-of-training-distribution generalization can be achieved through our method after using only a few training tasks. We show through detailed controlled experiments that Skipper performs mostly significantly better in terms of zero-shot generalization when trained on reasonable amount of tasks, compared to the baselines and to state-of-the-art Hierarchical Planning (HP) methods:
LEAP (Nasiriany et al., 2019) uses a shortest-path evolutionary algorithm to perform planning during decision time. This strategy mimics the evolution of DNAs to achieve better plans.
Director (Hafner et al., 2022) employs background planning and imagines at decision time a future state certain time-steps away to use as a goal. It uses the model to generate extra imaginary data for the value estimator to be trained on.
From the content presented in the Appendix, we deduce additionally that:
Spatial abstraction based on the local perception field is crucial for the scalability of the agents;
Skipper performs well by reliably decomposing the given tasks, and achieving the sub-tasks robustly. Its performance is bottlenecked by the accuracy of the estimated proxy problems as well as the checkpoint policies, which correspond to goal generalization and capability generalization, respectively. This matches well with our theory. The proposed delusion suppression technique (in Appendix) is effective in suppressing plans with non-existent checkpoints as targets, thereby increasing the accuracy of the proxy problems;
LEAP fails to generalize well within its original form and can generalize better when its compatibility with terminal states as well as the suppression of delusional plans are improved;
Director may generalize better only in domains where long and informative trajectory collection is possible, due to the characteristics of its recurrent state space models;
We verified empirically that, as expected, Skipper is compatible with stochasticity.

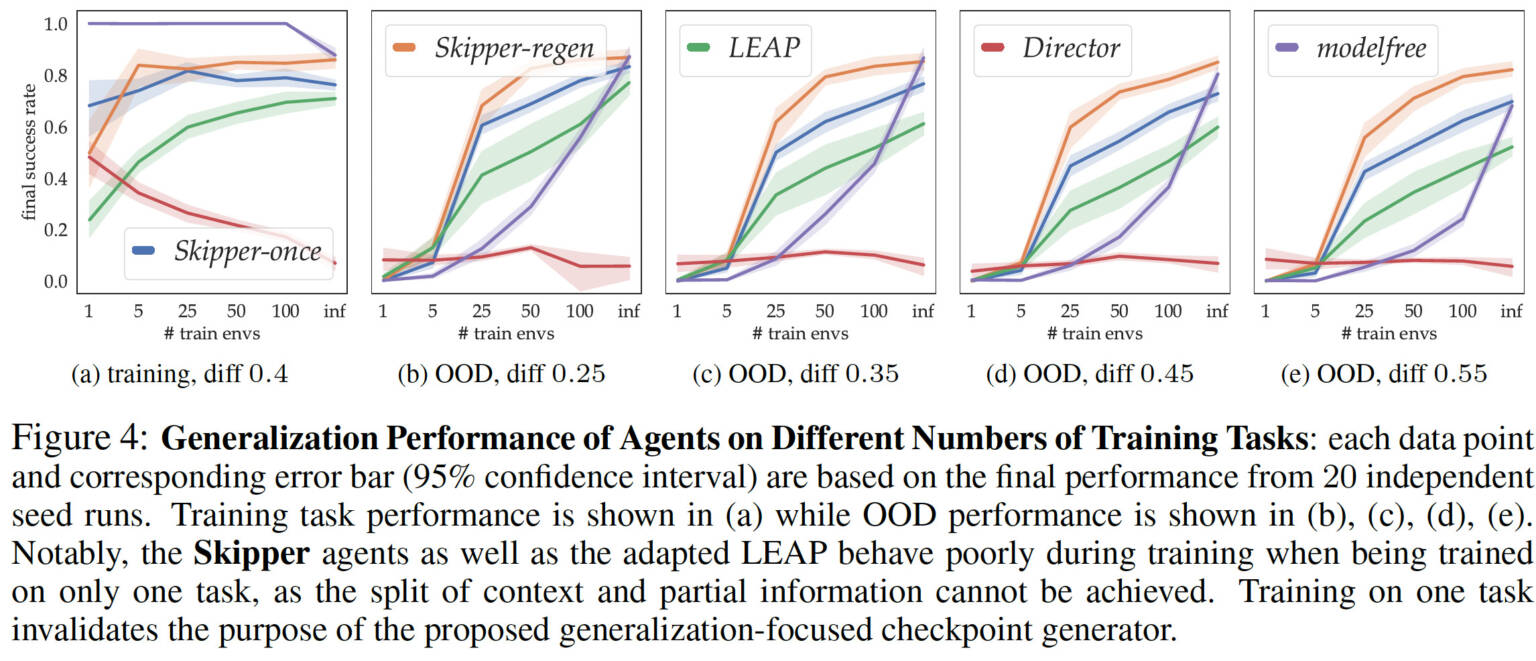
In conclusion, the experiments verified the claimed performance characteristics of Skipper and its significant abilities to enhance out-of-distribution generalization.
Highlights (TL;DR)
Skipper achieves superior zero-shot out-of-distribution generalization. The generalization advantages mainly come from the following sources:
Theory-Motivated Divide-and-Conquer: we propose proxy problems with which a divide and conquer strategy could implement over longer-term reasoning for better generalization. Theoretical analyses are presented to show the applicable scenario and performance guarantees;
Spatio-temporal abstraction: temporal abstraction allows us to break down the given task into smaller ones, while spatial abstraction over the state features through an attention mechanism is used to improve local learning and generalization;
Decision-time planning is employed due to its ability to improve the policy in novel situations;
Learning end-to-end from hindsight, off-policy: to maximize sample efficiency and the ease of training, we propose to use auxiliary (off-)policy methods for edge estimation, and learn a context-conditioned checkpoint generation, both from hindsight experience replay;
Higher quality proxies: we introduce pruning techniques to improve the sparsity of the proxy problems, which leads to better quality;
Delusion suppression: we propose a delusion suppression technique to minimize the behavior of chasing non-existent outcomes. This is done by exposing the edge estimators to targets that would otherwise not exist in experience.
(work largely done during Harry, Harm and Romain’s time at MSR)
This is our 2nd work on integrating conscious information processing behavior into Reinforcement Learning (RL) agents. This work builds upon our previous work on spatial abstraction (NeurIPS 2021) in planning, raising the attention of the missing flavor of spatial abstraction in the existing temporal abstraction frameworks.


