


A groundbreaking study to detect and remove hallucinations in AI models
AI assistants based on large language models, like ChatGPT and Gemini, are transforming how millions of people work and live. But their tendency to "hallucinate"—producing confident yet false information— undermines trust, slows adoption, and adds costly oversight, especially in critical sectors like healthcare, law, and finance. We unveil a new method to detect and eliminate hallucinations that can easily be implemented in existing AI tools to increase their reliability and trustworthiness.
Our latest paper accepted at NeurIPS 2025, From Noise to Narrative: Tracing the Origins of Hallucinations in Transformers, introduces a groundbreaking approach to the persistent problem of hallucinations. Instead of treating AI models as "black boxes," we've developed tools to peer inside, identifying and neutralizing the origins of hallucinations deep within the model's internal processing.
This allows us to prevent false outputs from emerging before they ever reach the end user.
Detecting hallucinations from within
Until now, most AI safety measures have focused on filtering inputs and outputs. While important, this "black box" approach fails to address the root cause of hallucinations, which often stem from the model's internal reasoning.
Imagine trying to fix a faulty engine by only checking the fuel and exhaust: you would miss the internal mechanics causing the problem. Our research reveals that many harmful behaviors, including hallucinations, arise from these hidden internal layers.
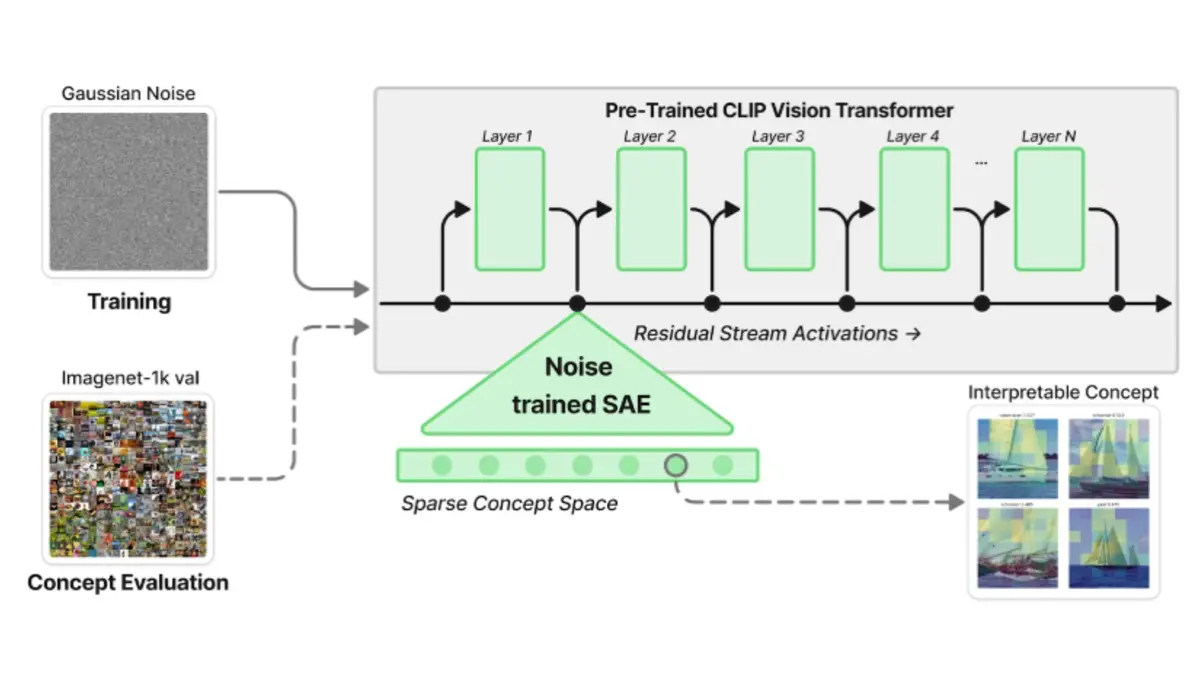
Our novel tactic involves observing what happens when we feed an AI model progressively degraded, nearly meaningless inputs — noise. Surprisingly, instead of "giving up," the model activates an increasing number of internal "concept units," essentially inventing more internal structure and meaning to compensate for the lack of coherent input.
This suggests that AI models have internal "leanings" or strong priors that can lead them to construct meaning even when there's no real signal, like a human “seeing” familiar shapes in clouds.
Here are some concepts that the LLM imagines in pure noise inputs:

Suppressing hallucinations in real-time
Crucially, these hallucination-prone activations tend to emerge in the middle layers of the transformer, becoming a fertile ground for "conceptual wandering" when the input is unclear. By monitoring these internal concept activations, we can predict whether a model is about to hallucinate even before it generates an output.
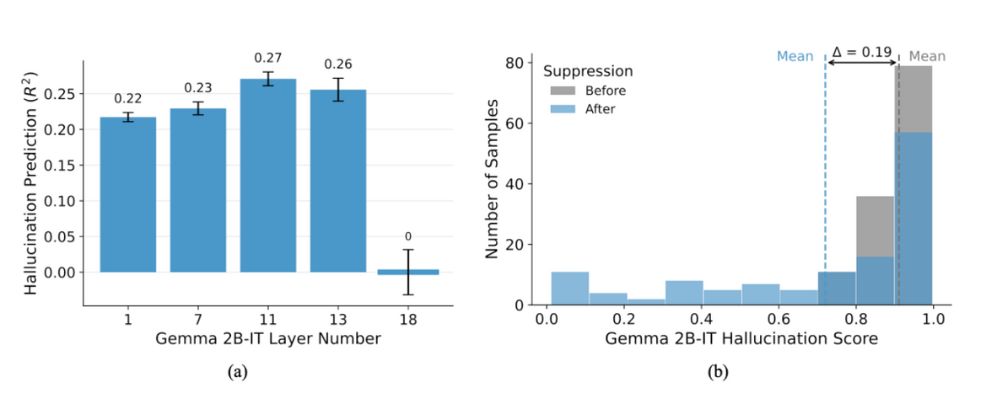
Beyond mere observation, we have designed experiments that causally intervene in the model's internal processing. By surgically identifying and suppressing specific "culprit" concept activations in the middle layers, we demonstrated that we can significantly reduce hallucinated content and improve correctness.
This is akin to muting an off-key voice in a choir to restore harmony.
Ready for deployment
This breakthrough opens the door to real-time mitigation of hallucinations: we can now design AI models that can monitor their own internal processes, detect the precursors to a hallucination, and dynamically course-correct before the false information is ever formed.
This method can also be extended to address other critical AI failure modes, including systematic biases and hijacking attempts.
With our method, organizations designing LLM-powered products and services can build more reliable, trustworthy AI systems, accelerating the safe and widespread adoption of AI across all industries to unlock its immense potential to drive innovation and solve complex challenges.


