


Une méthode révolutionnaire pour détecter et éliminer les hallucinations dans les modèles d'IA
Les assistants d'IA basés sur les grands modèles de langage (LLM), comme ChatGPT et Gemini, transforment la manière dont des millions de personnes travaillent et vivent. Mais leur tendance à « halluciner », c'est-à-dire à produire des informations fausses mais avec assurance, sape la confiance, ralentit leur adoption et rend leur supervision coûteuse, particulièrement dans des secteurs critiques comme la santé, le droit et la finance. Nous dévoilons une nouvelle méthode pour détecter et éliminer les hallucinations, qui peut être facilement mise en œuvre dans les outils d'IA existants pour accroître leur fiabilité et leur crédibilité.
Notre dernier article, accepté à NeurIPS 2025, From Noise to Narrative: Tracing the Origins of Hallucinations in Transformers, présente une approche révolutionnaire au problème persistant des hallucinations. Au lieu de traiter les modèles d'IA comme des « boîtes noires », nous avons développé des outils pour examiner leur fonctionnement interne, en identifiant et neutralisant les origines des hallucinations au sein du traitement interne du modèle.
Cela nous permet d'empêcher les faussetés d'émerger avant même qu'elles n'atteignent l'utilisateur final.
Détecter les hallucinations de l'intérieur
Jusqu'à présent, la plupart des mesures de sécurité de l'IA se sont concentrées sur le filtrage des entrées et des sorties. Bien qu'importante, cette approche de la « boîte noire » ne s'attaque pas à la cause profonde des hallucinations, qui proviennent souvent du raisonnement interne du modèle.
Imaginez essayer de réparer un moteur défectueux en ne vérifiant que le carburant et l'échappement : vous passeriez à côté de la mécanique interne à l'origine du problème. Notre recherche révèle que de nombreux comportements nuisibles, y compris les hallucinations, proviennent de ces couches internes cachées.
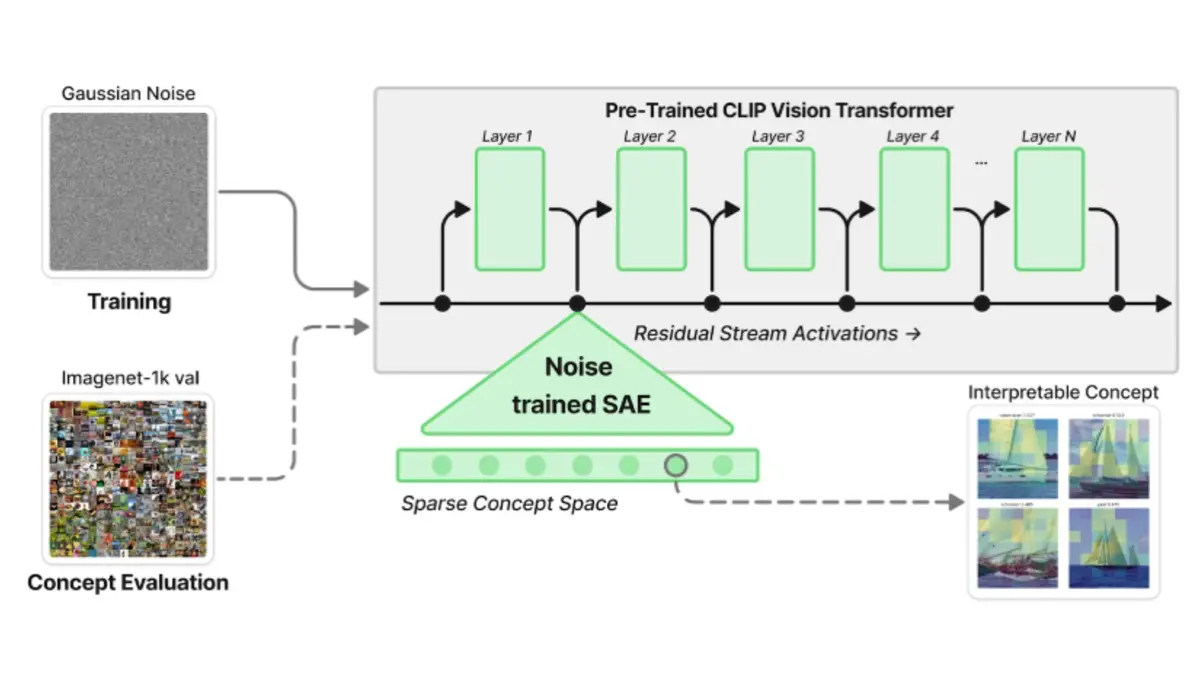
Notre méthode novatrice consiste à observer ce qui se passe lorsque nous fournissons à un modèle d'IA des entrées progressivement dégradées, presque dénuées de sens, aussi appelées du bruit. Étonnamment, au lieu d'« abandonner », le modèle active un nombre croissant d'« unités conceptuelles » internes, inventant essentiellement plus de structure et de sens pour compenser le manque d'entrées cohérentes.
Cela suggère que les modèles d'IA ont des « tendances » internes ou de forts a priori qui peuvent les amener à construire du sens même en l'absence de signal réel, comme un humain qui « voit » des formes familières dans les nuages.
Voici quelques concepts que le LLM imagine à partir d'entrées de bruit pur :

Supprimer les hallucinations en temps réel
Fait crucial, ces activations sujettes aux hallucinations ont tendance à émerger dans les couches intermédiaires du transformeur, devenant un terrain fertile pour la « divagation conceptuelle » lorsque l'entrée n'est pas claire. En surveillant ces activations de concepts internes, nous pouvons prédire si un modèle est sur le point d'halluciner avant même qu'il ne génère un résultat.
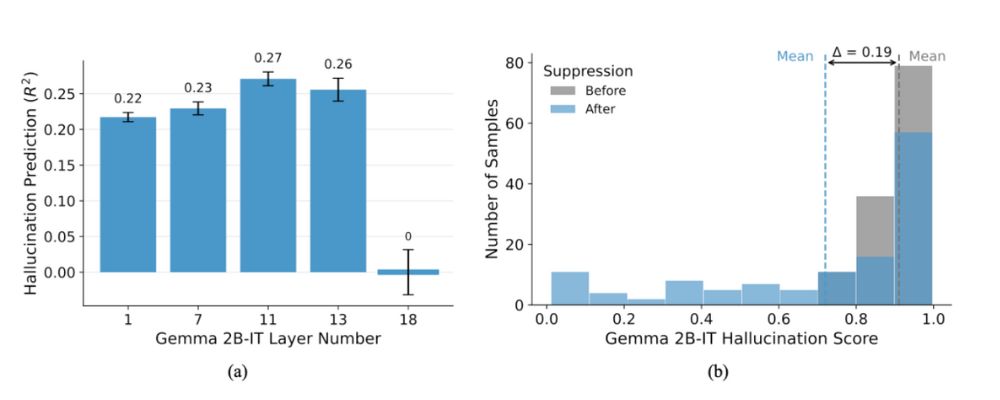
Au-delà de la simple observation, nous avons conçu des expériences qui interviennent de manière causale dans le traitement interne du modèle. En identifiant et en supprimant précisément des activations conceptuelles « fautives » spécifiques dans les couches intermédiaires, nous avons démontré que nous pouvons réduire de manière significative le contenu halluciné et améliorer l'exactitude.
Cela s'apparente à mettre en sourdine une voix fausse dans une chorale pour restaurer l'harmonie.
Prêt pour le déploiement
Cette percée ouvre la voie à une atténuation des hallucinations en temps réel : nous pouvons désormais concevoir des modèles d'IA capables de surveiller leurs propres processus internes, de détecter les précurseurs d'une hallucination et de corriger dynamiquement leur trajectoire avant même que l'information fausse ne soit formée.
Cette méthode peut également être étendue pour traiter d'autres modes de défaillance critiques de l'IA, y compris les biais systématiques et les tentatives de détournement.
Avec notre méthode, les organisations qui conçoivent des produits et services basés sur les LLM peuvent construire des systèmes d'IA plus fiables et dignes de confiance, accélérant ainsi l'adoption sûre et généralisée de l'IA dans tous les secteurs pour libérer son immense potentiel afin de stimuler l'innovation et de résoudre des défis complexes.


