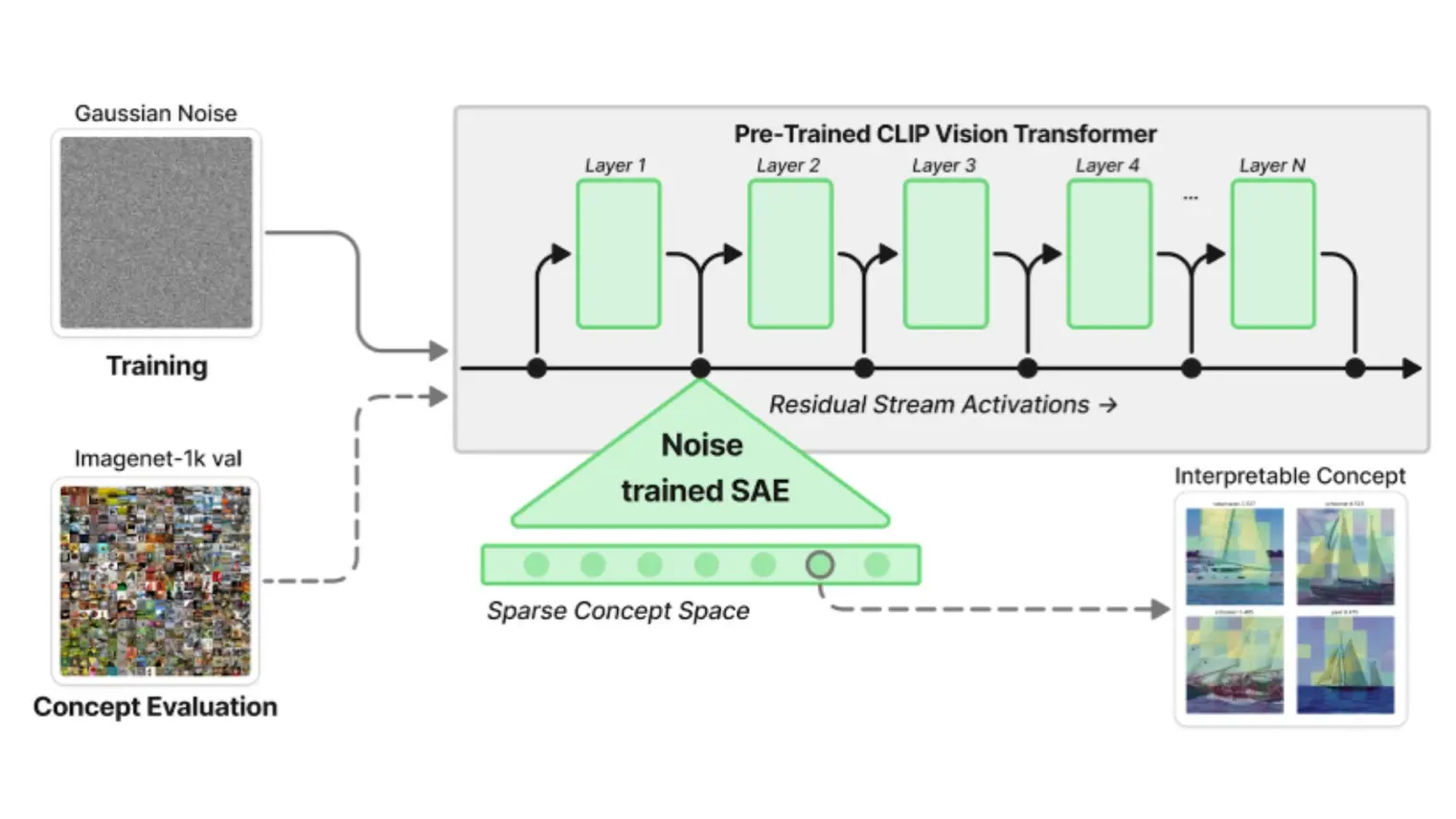
As generative AI systems become competent and democratized in science, business, and government, deeper insight into their failure modes now
… (see more) poses an acute need. The occasional volatility in their behavior, such as the propensity of transformer models to hallucinate, impedes trust and adoption of emerging AI solutions in high-stakes areas. In the present work, we establish how and when hallucinations arise in pre-trained transformer models through concept representations captured by sparse autoencoders, under scenarios with experimentally controlled uncertainty in the input space. Our systematic experiments reveal that the number of semantic concepts used by the transformer model grows as the input information becomes increasingly unstructured. In the face of growing uncertainty in the input space, the transformer model becomes prone to activate coherent yet input-insensitive semantic features, leading to hallucinated output. At its extreme, for pure-noise inputs, we identify a wide variety of robustly triggered and meaningful concepts in the intermediate activations of pre-trained transformer models, whose functional integrity we confirm through targeted steering. We also show that hallucinations in the output of a transformer model can be reliably predicted from the concept patterns embedded in transformer layer activations. This collection of insights on transformer internal processing mechanics has immediate consequences for aligning AI models with human values, AI safety, opening the attack surface for potential adversarial attacks, and providing a basis for automatic quantification of a model's hallucination risk.