



Résumé et introduction
Dans le domaine de la science des matériaux, le traitement automatique du langage naturel a le potentiel de révolutionner la manière dont les chercheurs et les chercheuses accèdent à de vastes quantités de documents scientifiques et les utilisent. Le principal défi provient toutefois du manque d’ensembles de données de grande qualité propres au domaine et du besoin de disposer de modèles de langage spécialisés capables d’interpréter et de générer avec précision des textes relatifs à la science des matériaux. Pour y remédier, notre recherche introduit MatSci-NLP, un outil d’étalonnage exhaustif conçu pour évaluer la performance des modèles de traitement du langage naturel dans diverses tâches liées à la science des matériaux. Parallèlement, nous présentons HoneyBee, un grand modèle de langage spécialement adapté à la science des matériaux, qui utilise un nouveau cadre de génération de données fondé sur les instructions, MatSci-Instruct. Nos principales contributions comprennent la création de MatSci-NLP, qui englobe plusieurs tâches de traitement du langage naturel adaptées à la science des matériaux, et la mise au point de HoneyBee, qui tire parti du peaufinage progressif des instructions pour améliorer la performance des modèles. En intégrant MatSci-Instruct à HoneyBee, nous visons à surmonter les défis liés à la rareté des données et à la spécialisation des modèles. Nos conclusions démontrent que le préentraînement propre au domaine et les méthodes novatrices de génération de données améliorent considérablement l’efficacité des grands modèles de langages dans les applications de la science des matériaux.
MatSci-NLP et HoneyBee
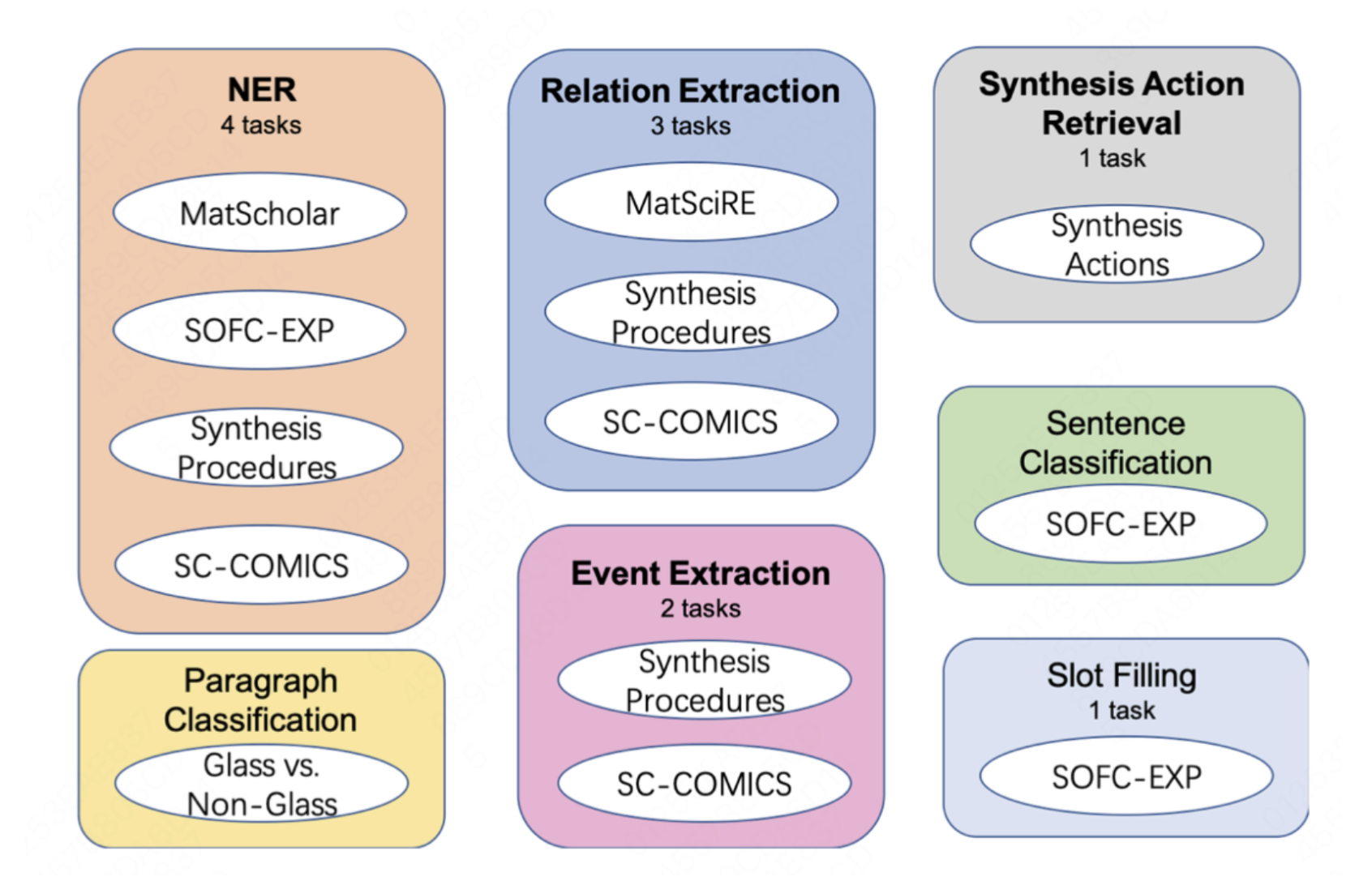
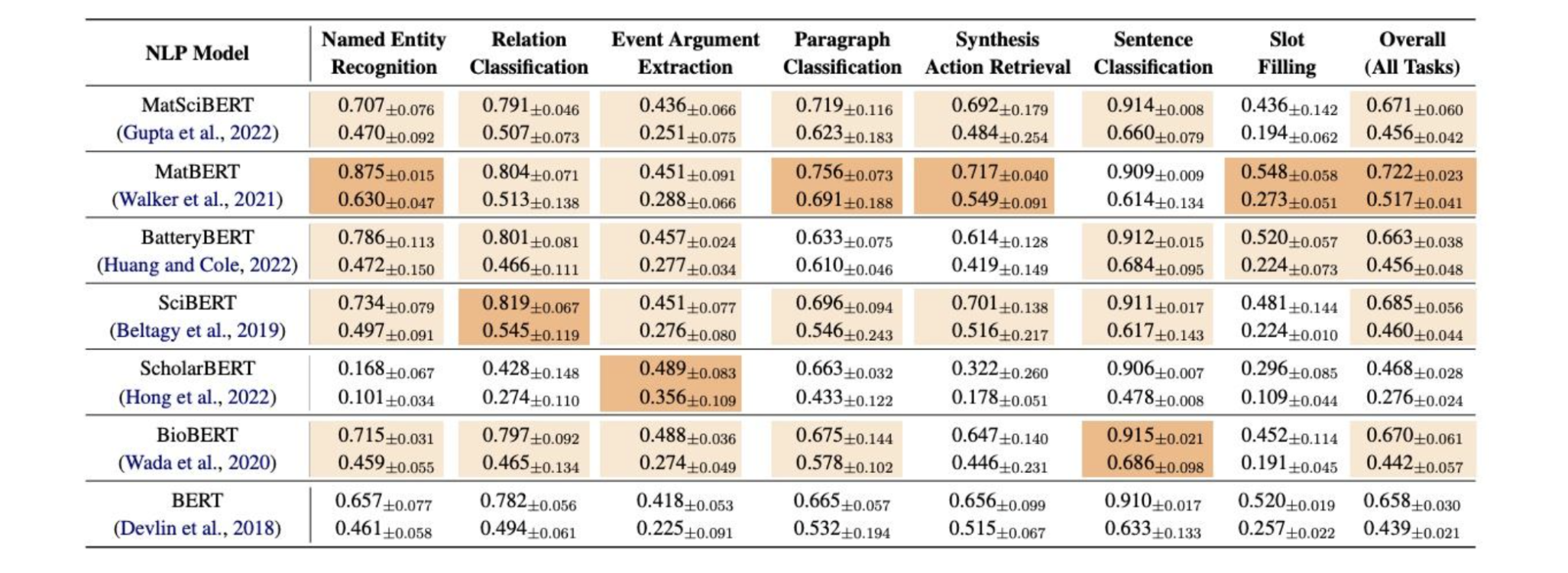
L’intégration du traitement du langage naturel et de la science des matériaux constitue une avancée révolutionnaire. Toutefois, elle s’est heurtée d’emblée à un obstacle considérable : l’absence d’un ensemble de données de référence unifié. Cet obstacle a été surmonté avec l’introduction de MatSci-NLP, le premier ensemble de données de référence spécifiquement conçu pour la science des matériaux. MatSci-NLP sert de pierre angulaire en fournissant un cadre standardisé permettant d’évaluer et de comparer la performance de divers modèles de langage adaptés à ce domaine. Il ne s’agit pas d’un ensemble de données comme les autres; c’est une collection exhaustive qui couvre un large éventail de sujets liés à la science des matériaux, comme le présente la figure 1. Cet ensemble de données de référence comprend diverses tâches liées à la science des matériaux, comme la prédiction des propriétés des matériaux et l’extraction de renseignements à partir d’articles. Toutes les tâches sont unifiées au format texte-vers-schéma afin d’encourager la généralisation à de nombreuses tâches. En proposant un ensemble de données robuste et étendu, MatSci-NLP garantit que tout modèle de langage prétendant exceller dans le domaine de la science des matériaux doit démontrer ses capacités dans un large éventail de tâches complexes. Comme le montre la figure 2, nous constatons que le préentraînement propre au domaine influe sur la performance du modèle et que les ensembles de données déséquilibrés dans MatSci-NLP faussent les mesures de performance.
L’importance de MatSci-NLP est encore accentuée par son rôle dans la mise au point de HoneyBee, un modèle de langage de pointe dans le domaine de la science des matériaux. HoneyBee enregistre la meilleure performance sur MatSci-NLP par rapport aux grands modèles de langage généraux. Comme le montre la figure 3, l’un des aspects les plus novateurs de HoneyBee a été la génération automatique d’un corpus de peaufinage des instructions à grande échelle et de grande qualité. Ce processus peut s’apparenter à l’exploitation d’une usine automatisée très efficace. Plutôt que de produire manuellement chaque donnée d’instruction, ce qui demanderait beaucoup de travail et serait incohérent, on a fait appel à des algorithmes avancés pour générer le corpus. En analysant et en comprenant la documentation existante sur la science des matériaux, ces algorithmes ont créé un ensemble varié d’instructions et d’exemples, assurant ainsi que les données d’entraînement étaient à la fois exhaustives et pertinentes. Cette automatisation a considérablement dopé la performance de HoneyBee dans le cadre de tâches spécialisées, un peu à la manière d’une usine automatisée qui fabrique massivement et avec précision des produits de grande qualité.
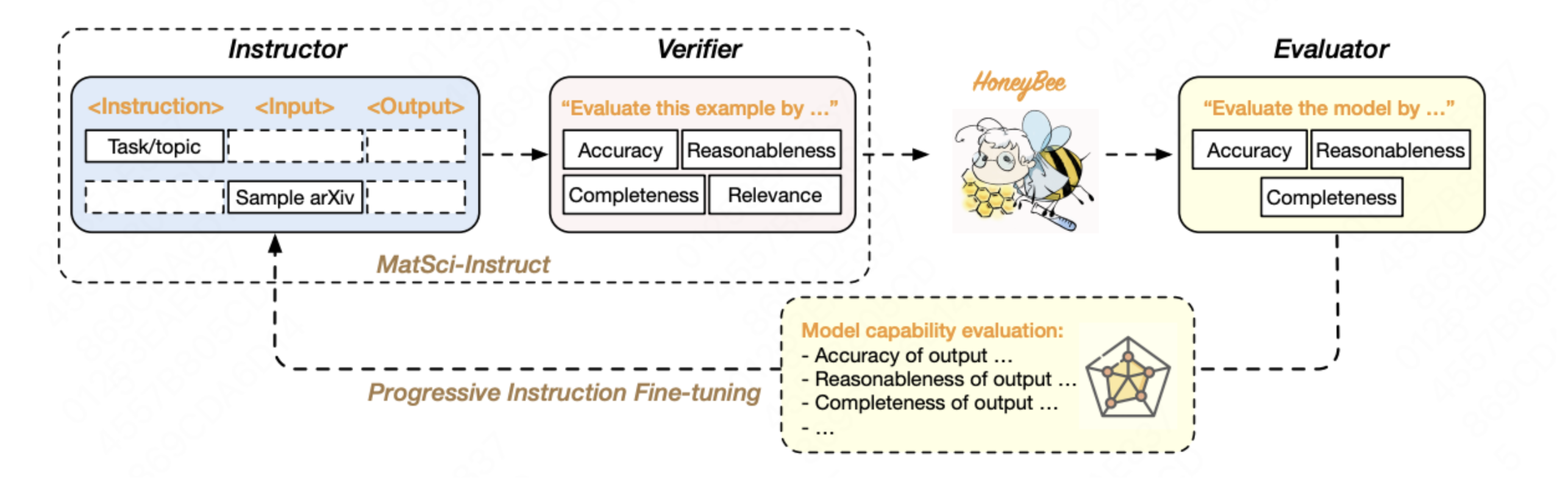
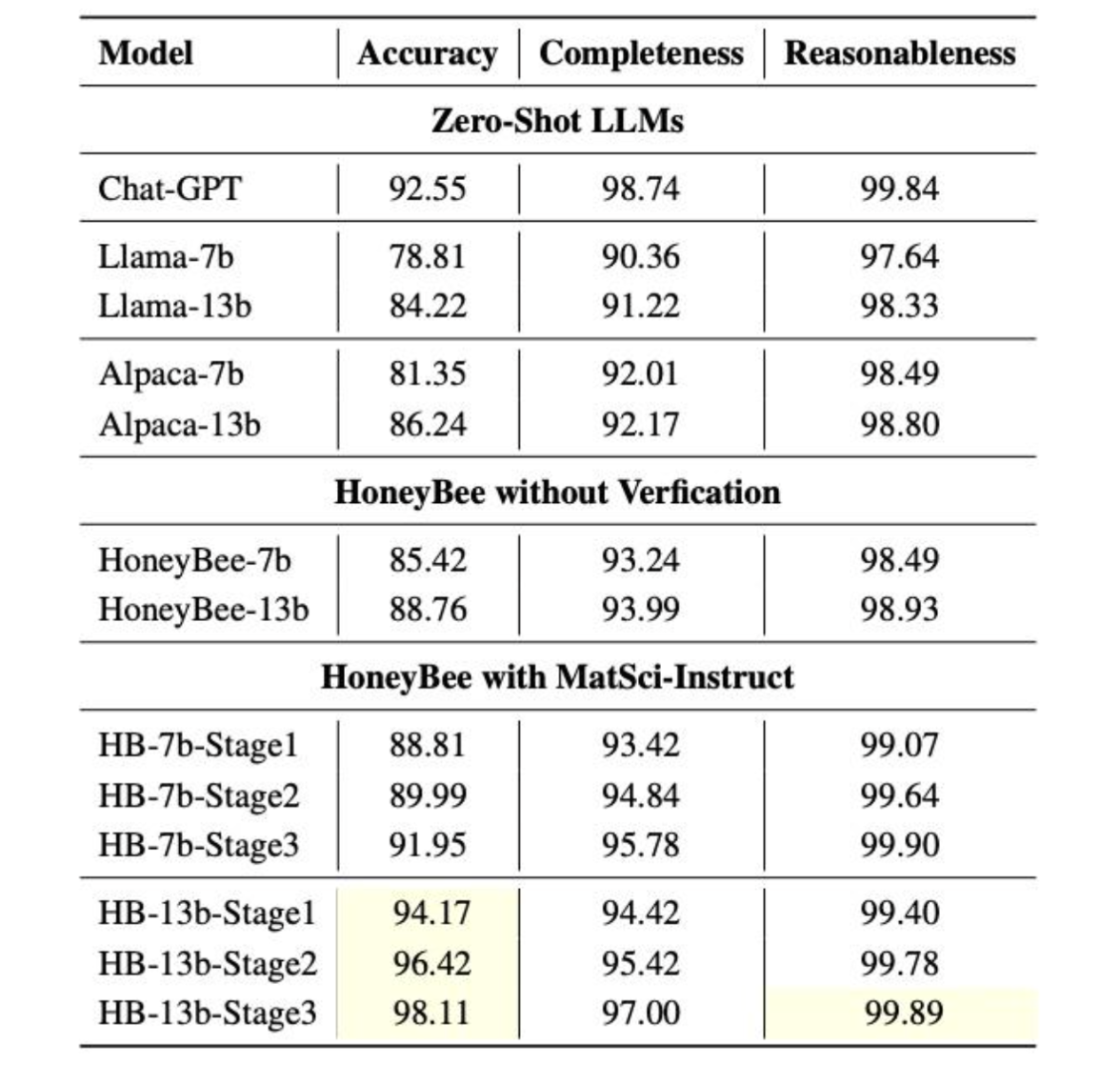
Pour maximiser l’efficacité de l’apprentissage, HoneyBee a utilisé une boucle de rétroaction continue, qui associe la génération d’instructions à l’évaluation de la capacité du modèle. Imaginez ce processus comme un thermostat intelligent qui ajuste continuellement la température en fonction de la rétroaction en temps réel. Pour HoneyBee, la performance du modèle vis-à-vis des instructions générées a été constamment contrôlée et évaluée. Cette rétroaction a ensuite servi à peaufiner le processus de génération d’instructions, en veillant à ce que le modèle reçoive les données d’entraînement les plus utiles. Les résultats de la figure 4 montrent que HoneyBee s’améliore progressivement à chaque itération de MatSci-Instruct.
La collaboration entre MatSci-NLP et HoneyBee offre de nouvelles possibilités de recherche et d’innovation dans le domaine de la science des matériaux. MatSci-NLP établit un point de référence pour l’évaluation, tandis que HoneyBee démontre l’efficacité de l’entraînement spécialisé et de la génération automatique d’instructions. Ensemble, ils constituent une avancée transformatrice, dans laquelle les outils de traitement du langage naturel stimulent le progrès scientifique dans le domaine de la science des matériaux, ce qui devrait se traduire par d’autres percées à l’avenir.
Conclusion
En résumé, notre recherche aborde les défis majeurs liés à l’application du traitement du langage naturel à la science des matériaux en concevant des outils spécialisés comme MatSci-NLP et HoneyBee. Ces outils s’appuient sur un préentraînement propre au domaine, des méthodes novatrices de génération de données et des processus d’apprentissage itératifs pour améliorer de façon considérable la performance et la fiabilité des grands modèles de langage scientifiques. Ces avancées ouvrent la voie à une découverte et à une application plus efficaces et plus précises des connaissances dans le domaine de la science des matériaux, soulignant ainsi le potentiel de transformation du traitement du langage naturel dans ce secteur.


