



Summary and introduction
In the realm of materials science, natural language processing (NLP) holds the potential to revolutionize how researchers access and utilize vast quantities of scientific literature. The principal challenge, however, resides in the paucity of high-quality, domain-specific datasets and the necessity for specialized language models capable of accurately interpreting and generating materials science text. To address this, our research introduces MatSci-NLP, a comprehensive benchmark designed to evaluate the performance of NLP models across various materials science tasks. Concurrently, we present HoneyBee, a large language model (LLM) fine-tuned specifically for materials science using a novel instruction-based data generation framework, MatSci-Instruct. Our primary contributions include the creation of MatSci-NLP, which encompasses several NLP tasks tailored to materials science, and the development of HoneyBee, which leverages progressive instruction fine-tuning to enhance model performance. By integrating MatSci-Instruct with HoneyBee, we aim to surmount the challenges of data scarcity and model specialization. Our findings demonstrate that domain-specific pre-training and innovative data generation methods significantly improve the efficacy of LLMs in materials science applications.
MatSci-NLP and HoneyBee
The integration of Natural Language Processing (NLP) and material science marks a revolutionary step forward, but this journey began with a significant hurdle: the absence of a unified benchmark dataset. This obstacle was overcome with the introduction of MatSci-NLP, the first benchmark dataset specifically designed for material science. MatSci-NLP acts as a cornerstone, providing a standardized framework to evaluate and compare the performance of various language models tailored to this field. MatSci-NLP is not just any dataset; it is a comprehensive collection that covers a wide spectrum of material science topics shown in Figure 1. This benchmark dataset includes diverse materials science tasks, such as predicting material properties and extracting information from papers, and all tasks are unified as text-to-schema format to encourage the generalize across multiple tasks. By offering a robust and extensive dataset, MatSci-NLP ensures that any language model claiming to excel in material science must demonstrate its abilities across a broad and complex range of tasks. As shown in Figure 2, we find that domain-specific pre-training affects model performance and imbalanced datasets in MatSci-NLP skew performance metrics.
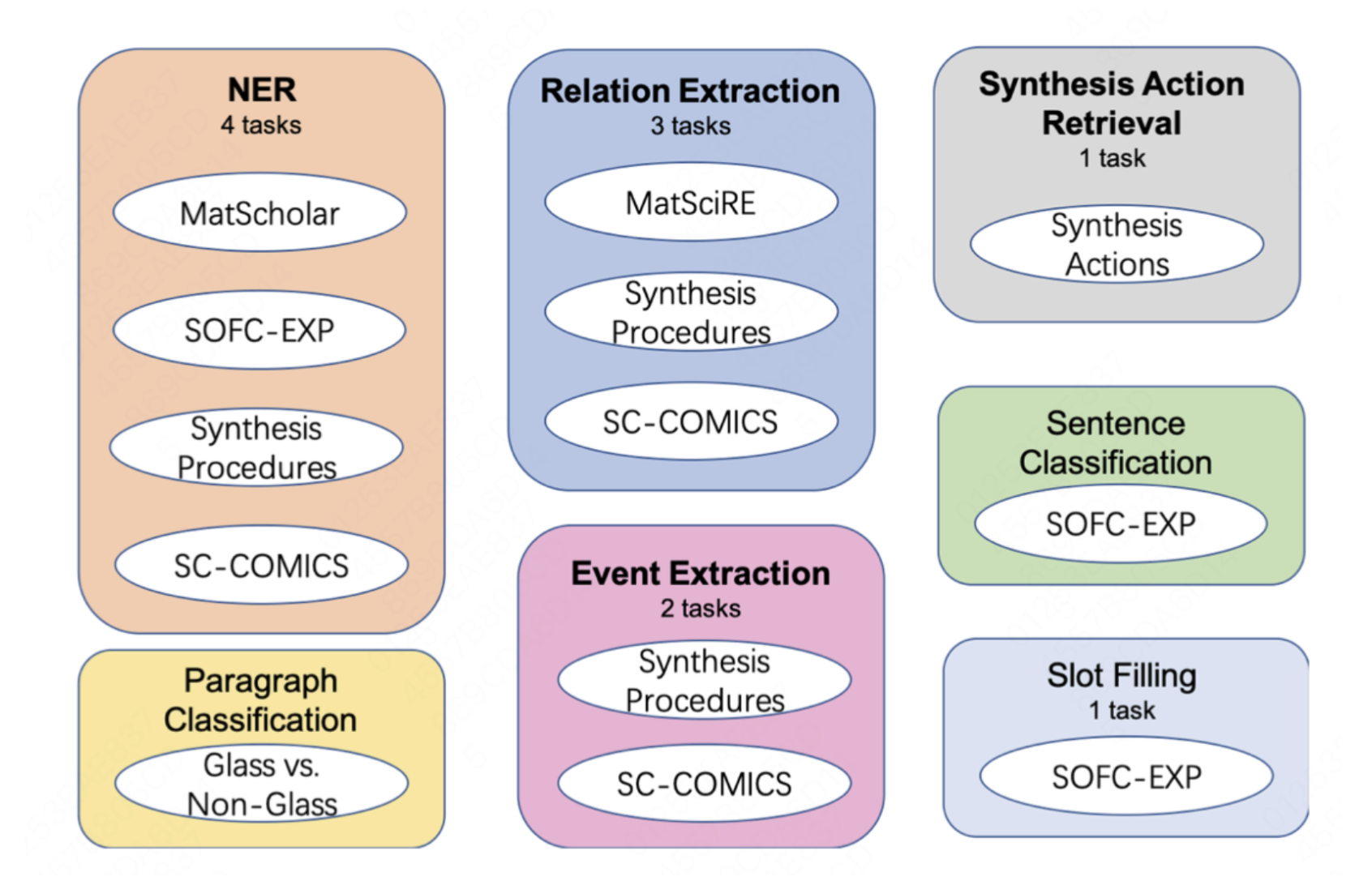
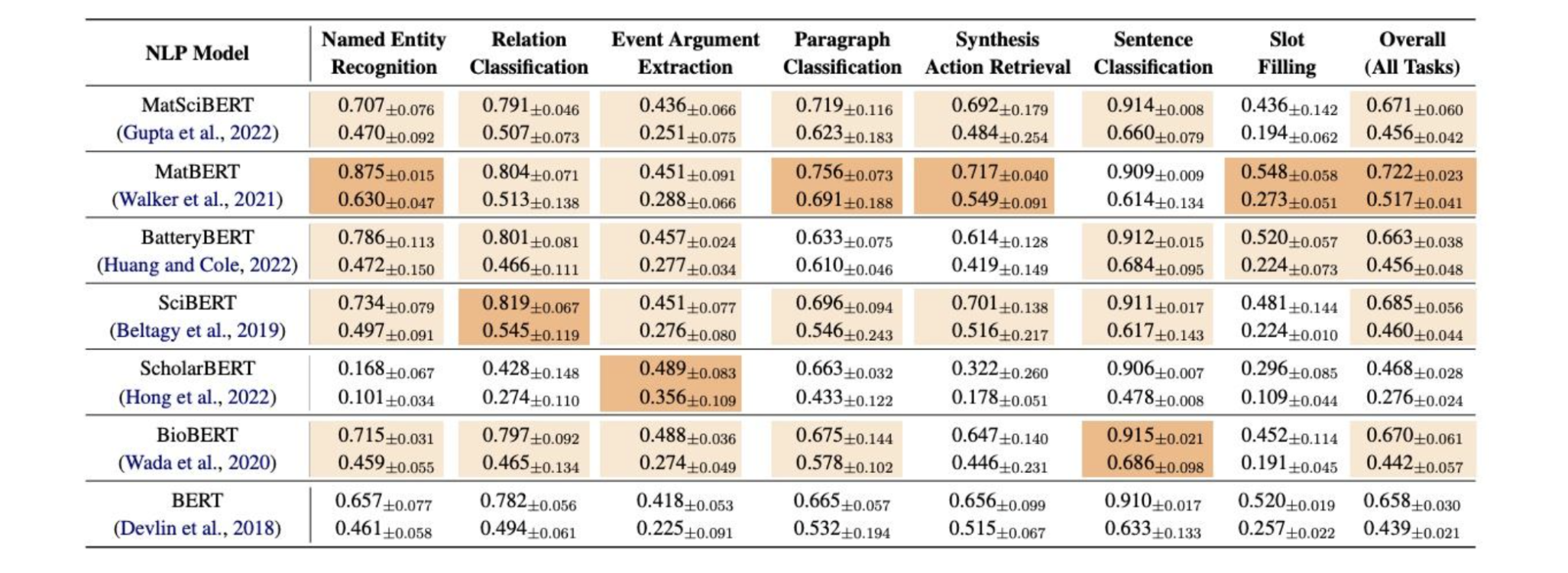
The significance of MatSci-NLP is further highlighted by its role in the development of HoneyBee, a state-of-the-art language model in material science, which achieves the best performance on MatSci-NLP compared with general domain LLMs. As shown in Figure 3, One of the most innovative aspects of HoneyBee’s development was the automatic generation of a large-scale, high-quality instruction tuning corpus. This process can be likened to operating a highly efficient, automated factory. Rather than manually crafting each piece of instructional data, which would be labor-intensive and inconsistent, advanced algorithms were employed to generate the corpus. By parsing and comprehending existing material science literature, these algorithms created a diverse set of instructions and examples, ensuring that the training data was both comprehensive and relevant. This automation significantly boosted HoneyBee’s performance on specialized tasks, akin to how an automated factory produces high-quality products at scale and with precision.
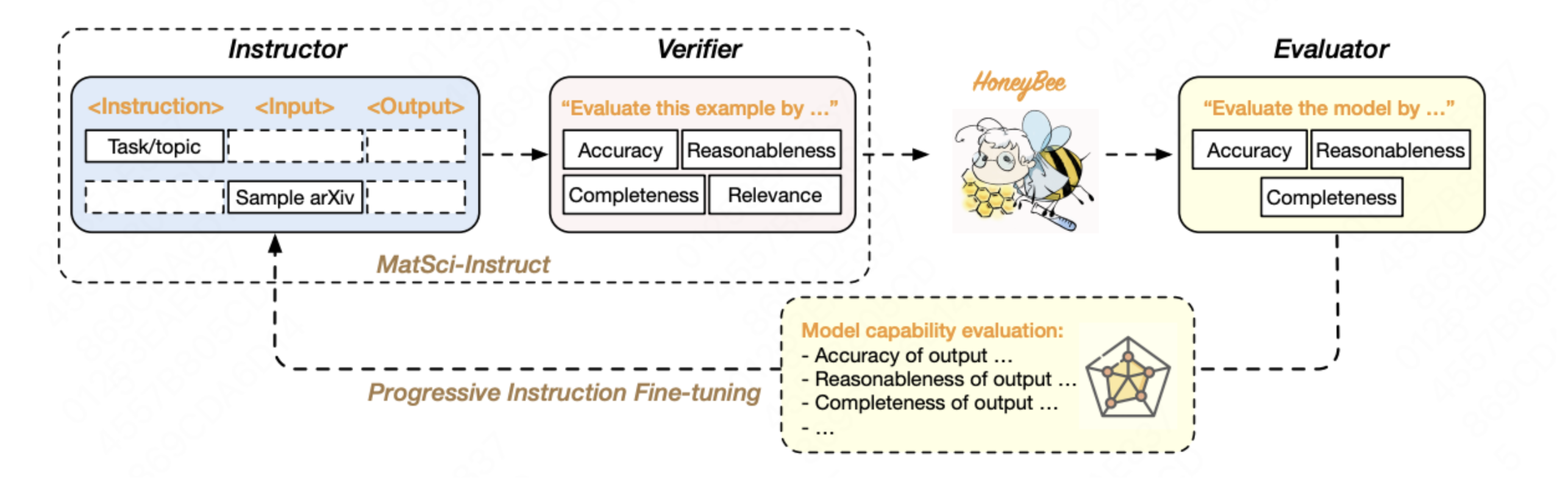
To maximize learning efficiency, HoneyBee employed a continuous feedback loop that combined instruction generation with model ability evaluation. Picture this process as a smart thermostat that continually adjusts the temperature based on real-time feedback. For HoneyBee, the model’s performance on generated instructions was constantly monitored and evaluated. This feedback was then used to refine the instruction generation process, ensuring that the model received the most beneficial training data. The results in Figure 4 show that HoneyBee gets progressively better with each iteration of MatSci-Instruct.
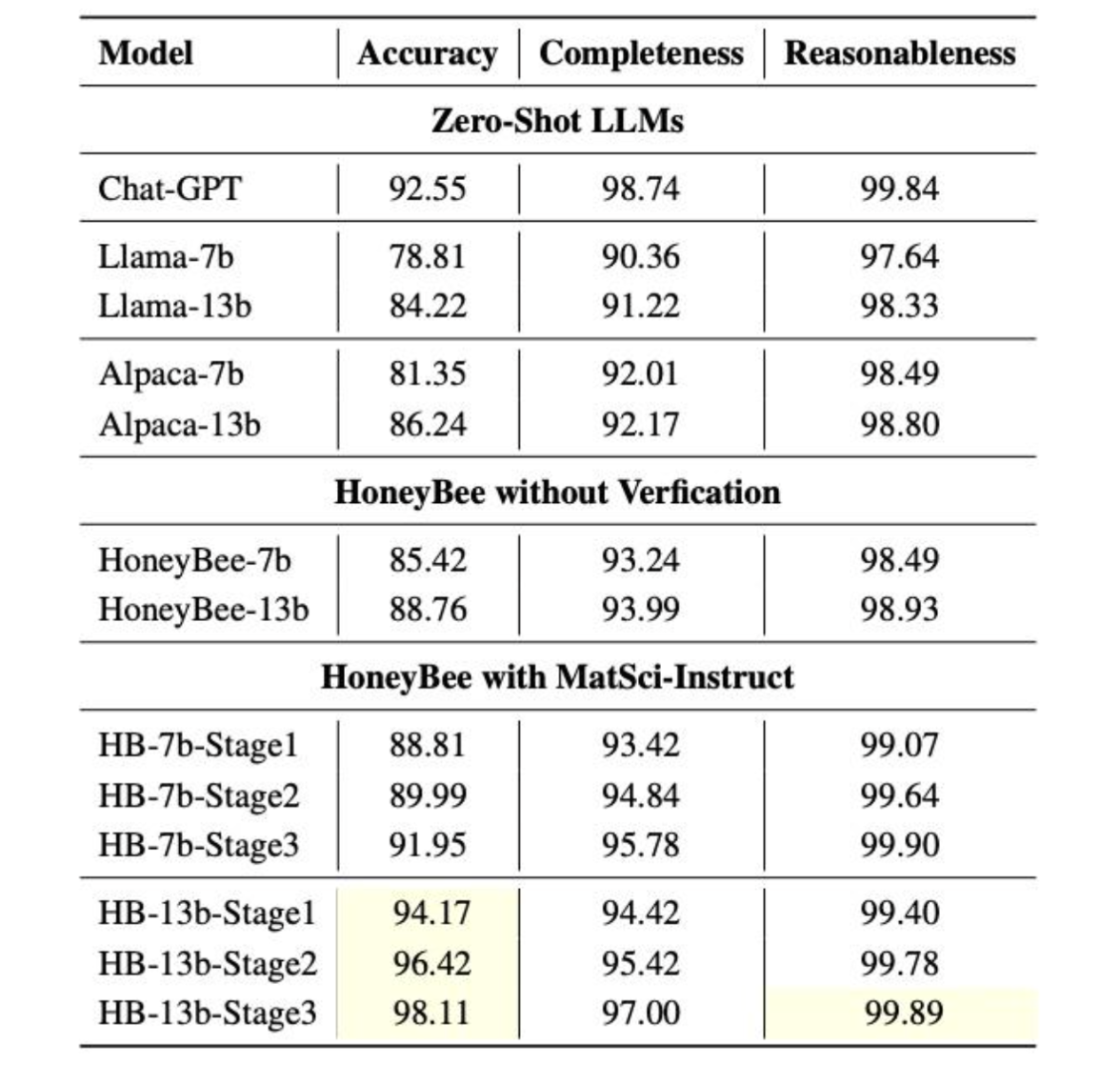
The collaboration between MatSci-NLP and HoneyBee opens new avenues for research and innovation in material science. MatSci-NLP sets a benchmark for evaluation, while HoneyBee showcases the effectiveness of specialized training and automated instruction generation. Together, they signify a transformative advancement, where NLP tools drive scientific progress in material science, promising further breakthroughs in the future.
Conclusion
In summary, our research addresses critical challenges in applying NLP to materials science by developing specialized tools like MatSci-NLP and HoneyBee. These tools leverage domain-specific pre-training, innovative data generation methods, and iterative learning processes to significantly enhance the performance and reliability of scientific LLMs. Moving forward, these advancements pave the way for more efficient and accurate discovery and application of materials science knowledge, highlighting the transformative potential of NLP in this field.


