


Note de la rédaction : Le travail présenté dans ce billet a été écrit en collaboration avec Karmesh Yadav de l’Université Carnegie Mellon. Il fera l’objet d’une présentation orale à NeurIPS 2020.
Le problème avec l’apprentissage continu, c’est qu’il implique des modèles d’entraînement ayant une capacité limitée à bien fonctionner sur un groupe de tâches dont le nombre est inconnu et qui arrivent de manière séquentielle.
L’oubli catastrophique constitue l’un des plus grands défis dans ce contexte. Tel que le définit Wikipédia, il s’agit de la tendance d’un réseau neuronal artificiel à oublier complètement et brusquement les connaissances qu’il a déjà acquises alors qu’il fait de nouveaux apprentissages. Cela se produit parce que les conditions d’échantillonnage de données iid (indépendantes et identiquement distribuées) requises par la descente de gradient stochastique sont violées lorsque les données des différentes tâches arrivent de manière séquentielle.
On peut aborder le problème de l’oubli par l’entremise de l’interférence de gradient, ou l’alignement de gradient négatif, comme on peut le voir à gauche dans la figure suivante. Nous voyons que les gradients liés aux tâches pour les paramètres d’un modèle entrent en conflit les uns avec les autres dans certaines parties de l’espace des paramètres. La performance altérerait donc les anciennes tâches, car les actualisations des gradients effectuées lors de l’apprentissage d’une nouvelle tâche ne s’alignent pas avec les directions des gradients pour les anciennes tâches. À la droite de l’image se trouve un scénario idéal, où les gradients s’alignent et où, par conséquent, la progression de l’apprentissage d’une nouvelle tâche coïncide avec la progression des anciennes. Il est donc essentiel d’assurer l’alignement des gradients pour réaliser des progrès similaires sur les objectifs liés aux tâches dans un contexte de disponibilité limitée des données d’entraînement. Comme nous allons le voir, ce type d’alignement entre les tâches peut être réalisé en exploitant certaines propriétés des actualisations de gradients fondées sur le méta-apprentissage.
Pourquoi le méta-apprentissage ?
L’une des applications les plus courantes du méta-apprentissage est l’apprentissage en quelques coups. En examinant de plus près les gradients de méta-apprentissage (calculés dans l’article sur la méthode Reptile [2]), on remarque que l’alignement des gradients facilite la généralisation de l’apprentissage en quelques coups.
Récapitulons rapidement le plus simple algorithme de méta-apprentissage fondé sur les gradients, le méta-apprentissage agnostique au modèle [1]. Supposons que nous voulions entraîner un modèle à apprendre à partir d’une poignée d’échantillons de n’importe quelle distribution de données, de telle sorte qu’il soit performant sur des échantillons jamais vus de cette distribution. Cette démarche peut être considérée comme une volonté d’optimiser deux objectifs : celui que nous réduisons au minimum lorsque nous apprenons à partir de la poignée d’échantillons (or \( L_ {interne} \)) et celui sur lequel nous testons le modèle une fois qu’il a terminé l’apprentissage sur la poignée d’échantillons (appelons-le \( L_ {externe} \); il est évalué sur des échantillons jamais vus provenant de la distribution). L’actualisation du méta-apprentissage agnostique au modèle (représenté dans la figure suivante) propose d’évaluer \( L_ {externe} \) sur le vecteur du paramètre (\( \theta_4 \)) obtenu après avoir pris quelques pas de gradient réduisant au minimum \( L_ {interne} \) à partir d’un vecteur initial \( \theta_0 \). Le gradient de ce \( L_ {externe} \), lorsqu’évalué par rapport à \( \theta_0 \), poussera \( \theta_0 \) dans une direction où à la fois \( L_ {interne} \) et \( L_ {externe} \) diminuent alors que l’alignement de leurs gradients augmente.
Alignement des gradients : Avec le gradient à mémoire épisodique [4] et le gradient A à mémoire épisodique [5] qui l’a suivi, le problème de l’apprentissage continu a été formulé en termes de réduction au minimum de l’interférence de gradient. Alors que le méta-apprentissage en quelques coups se préoccupe d’encourager l’alignement au sein des tâches, en apprentissage continu, nous voulons encourager l’alignement au sein des tâches et entre elles. Si le gradient à mémoire épisodique résout un programme quadratique pour obtenir la direction du gradient qui s’aligne au maximum avec le gradient sur les anciennes et les nouvelles tâches, le gradient A à mémoire épisodique fixe simplement les gradients sur les nouvelles tâches de telle sorte qu’aucune de leurs composantes n’interfère avec les anciennes tâches. La méta-rediffusion de l’expérience [3] a permis de réaliser que l’objectif du gradient à mémoire épisodique fondé sur l’alignement des gradients était à peu près équivalent à celui de l’algorithme de méta-apprentissage Reptile de premier ordre et a proposé un algorithme de méta-apprentissage fondé sur la rediffusion qui a appris une séquence de tâches tout en augmentant l’alignement entre les objectifs liés aux tâches.
Méta-apprentissage en ligne : En plus d’encourager l’alignement, le méta-apprentissage peut également influer directement sur les modèles afin qu’ils optimisent les objectifs auxiliaires, comme la généralisation, en les testant dans la boucle extérieure de l’apprentissage. Cette technique de composition d’objectifs a récemment été explorée pour l’apprentissage continu par Javed et coll. [6], qui ont proposé de préentraîner une représentation au moyen du méta-apprentissage, en utilisant l’oubli catastrophique comme signal d’apprentissage dans l’objectif extérieur. Les paramètres d’un réseau d’apprentissage de représentations sont établis, et un réseau d’apprentissage de tâches traite davantage la représentation et apprend en continu à partir d’un flux d’échantillons entrants. Après de courts intervalles, le réseau d’apprentissage de représentations et le réseau d’apprentissage de tâches sont évalués de manière répétée pour un ensemble de tâches retenues afin de mesurer l’oubli qui aurait eu lieu. Ce signal de méta-apprentissage, lorsqu’il est rétropropagé au réseau d’apprentissage de représentations sur de nombreuses époques, conduit à l’apprentissage d’une représentation qui résiste à l’oubli catastrophique et présente une rareté émergente. Cette composition de deux pertes pour simuler l’apprentissage continu dans la boucle intérieure et tester l’oubli dans la boucle extérieure est appelée « objectif de méta-apprentissage en ligne ».
Comment fonctionne le méta-apprentissage prospectif (La-MAML)
Jusqu’à présent, les points faibles des algorithmes de méta-apprentissage pour l’apprentissage continu sont qu’ils sont lents, hors ligne ou difficiles à régler. Dans cette recherche, nous surmontons ces difficultés et unissons les connaissances acquises grâce au méta-apprentissage en ligne et à la méta-rediffusion de l’expérience afin de concevoir un méta-algorithme d’apprentissage qui permet un apprentissage continu en ligne efficace.
En se basant sur la dernière section, il semble qu’une solution naturelle consiste à optimiser l’objectif du méta-apprentissage en ligne pour tous les paramètres d’un modèle par l’entremise d’une actualisation du méta-apprentissage agnostique au modèle. Ici, l’objectif intérieur consisterait à tirer des enseignements des flux de données entrantes pour une tâche, tandis que l’objectif extérieur consisterait à tester les paramètres adaptés sur des données échantillonnées à partir de toutes les tâches vues jusqu’à présent. Puisque les données ne sont accessibles que pendant leur diffusion en continu, nous pourrions en sous-échantillonner et en conserver une partie dans une mémoire tampon de rediffusion, puis en prélever des échantillons pour les évaluer dans le cadre de l’objectif extérieur.
Simple, n’est-ce pas ? Il reste une étape à franchir : nous devons d’abord prouver que cette façon d’apprendre optimise le bon objectif de l’apprentissage continu. Nous calculons les gradients de l’objectif de notre méta-apprentissage agnostique au modèle et montrons qu’ils sont équivalents à ceux de l’objectif du gradient A à mémoire épisodique dans l’article. Nous appelons cet algorithme de base le méta-apprentissage agnostique au modèle continu.
Nous montrons dans cet article que notre version du méta-objectif apprend plus rapidement puisqu’il aligne le gradient moyen des données de l’ancienne tâche avec le gradient des données de la nouvelle tâche au lieu d’essayer d’aligner tous les gradients des tâches les uns avec les autres (comme dans la méta-rediffusion de l’expérience). Nous démontrons de manière empirique que l’alignement des gradients, même des anciennes tâches, demeure positif tout au long de l’entraînement, même lorsqu’il n’est pas explicitement encouragé.
De plus,
- Nous constatons un défi d’optimisation dans l’apprentissage continu : l’utilisation de calendriers de taux d’apprentissage palimpsestes pour obtenir une convergence plus rapide vers certains minimas est impossible ici puisque la distribution des données n’est pas stationnaire. Cependant, une adaptabilité des taux d’apprentissage est encore fortement souhaitée, ce qui permettrait de mieux se conformer au paysage de l’optimisation, d’accélérer l’apprentissage et même de moduler le degré d’adaptation afin de réduire l’oubli catastrophique dans l’apprentissage continu.
- Nous proposons donc le méta-apprentissage prospectif (illustré dans la figure suivante), dans lequel nous optimisons également un ensemble de taux d’apprentissage par paramètre pouvant être appris, destinés à être utilisés dans les actualisations intérieures. Les différences entre le méta-apprentissage agnostique au modèle continu et le méta-apprentissage prospectif sont les \( \alpha^j \) utilisés comme vecteurs des taux d’apprentissage dans l’actualisation intérieure et actualisés dans la méta-actualisation.

Cette proposition est motivée par l’observation suivante : l’expression du gradient de l’objectif de méta-apprentissage en ligne relative à ces taux d’apprentissage reflète directement l’alignement entre les anciennes et les nouvelles tâches.
Par conséquent, les taux d’apprentissage sont actualisés à des valeurs plus élevées si les gradients entre les anciennes et les nouvelles tâches s’alignent pour un paramètre et diminuent s’ils interfèrent.
Nous proposons d’abord d’actualiser les taux d’apprentissage et ensuite de s’en servir pour actualiser la pondération dans les méta-actualisations afin que le méta-objectif module de manière prudente la cadence et la direction de l’apprentissage. Cela permet de progresser plus rapidement dans l’apprentissage d’une nouvelle tâche tout en facilitant le transfert des anciennes tâches. Il est à noter que le fait de fixer les gradients de façon excessive peut nuire aux progrès réalisés dans de nouvelles tâches, et ne représente qu’une moitié de la solution. La solution idéale consisterait à essayer d’aligner les gradients entre les tâches dès le départ afin de ne pas avoir à les fixer autant par la suite – c’est ce qui se produit dans le méta-apprentissage prospectif – ce qui lui donne un avantage sur le gradient A à mémoire épisodique, qui se contente de fixer les gradients, et sur la méta-rediffusion de l’expérience/gradient à mémoire épisodique, qui essaie simplement de les aligner davantage.
Expériences
Nous menons des expériences dans lesquelles on demande au modèle d’apprendre un ensemble de tâches de classification de données transmises en continu de façon séquentielle. Les expériences sont réalisées sur les jeux de données du MNIST, du CIFAR et de TinyImagenet dans les configurations à passage unique et à passages multiples où les données au sein d’une tâche peuvent être traitées pour une seule ou plusieurs époques respectivement. Les expériences portent à la fois sur des configurations de type « conscient de la tâche » (task-aware) et « agnostique à la tâche » (task-agnostic).
Pour comparer différentes approches, nous utilisons la précision retenue (la précision moyenne sur l’ensemble des tâches à la fin de la formation) ainsi que le transfert en chaînage arrière et l’interférence (la variation moyenne de la précision de chaque tâche entre le moment où elle a été apprise et la fin de la dernière tâche). S’il y a moins de transfert en chaînage arrière et d’interférence, il y aura moins d’oublis pendant la formation.
Nous comparons le méta-apprentissage agnostique au modèle continu et le méta-apprentissage prospectif à diverses approches antérieures de l’apprentissage continu en ligne, notamment la rediffusion de l’expérience, iCarl et le gradient à mémoire épisodique. Nous effectuons également de nombreuses ablations pour le méta-apprentissage prospectif, alors que nous utilisons et actualisons les taux d’apprentissage de différentes manières afin de comprendre les avantages de la modulation que nous proposons.
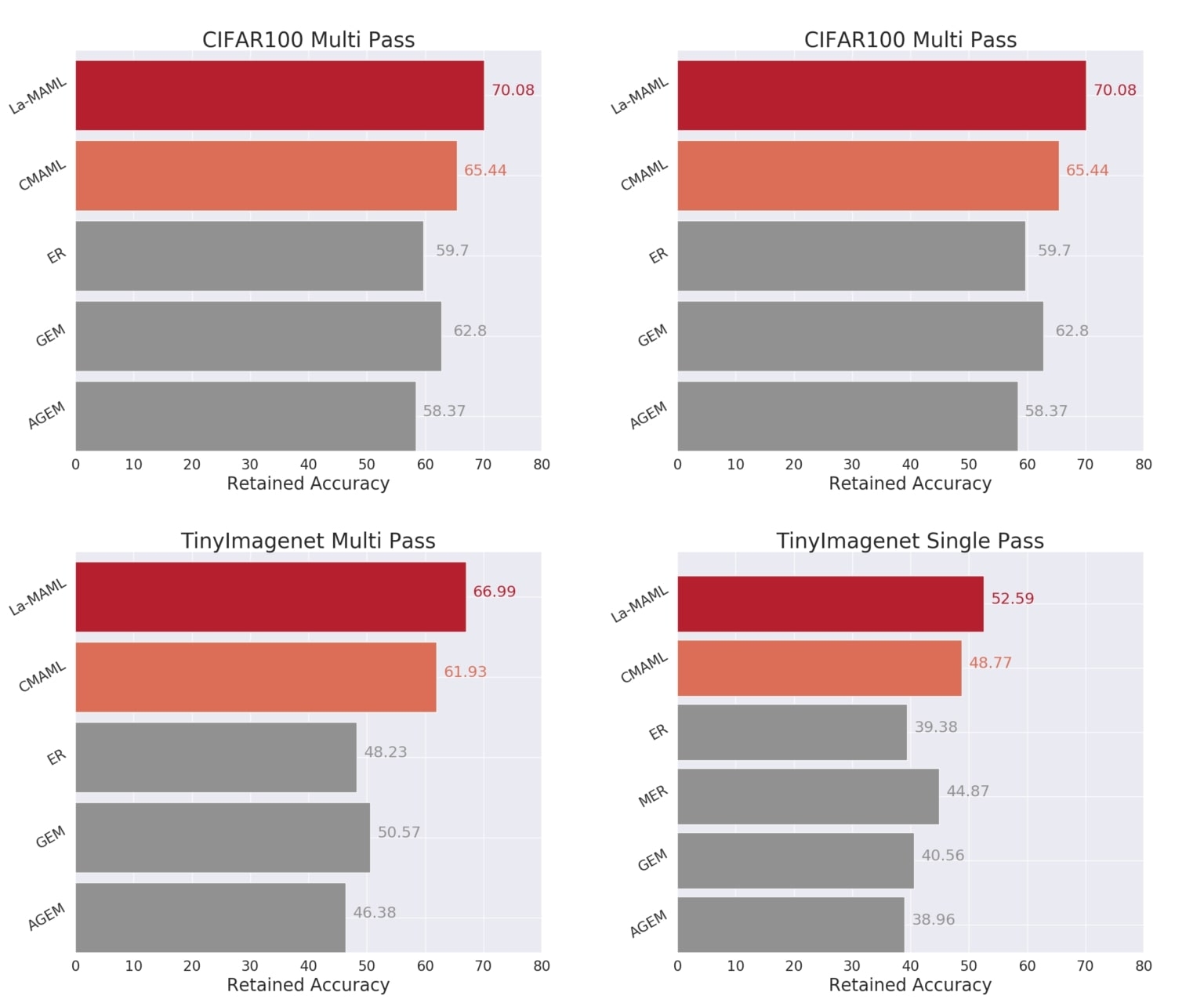
La figure ci-dessus présente les résultats de nos expériences pour certaines des lignes de base. Nous observons systématiquement que le méta-apprentissage prospectif est plus performant que d’autres modes d’apprentissage continu sur les deux jeux de données, quelle que soit la configuration. Parmi les approches les plus performantes, le méta-apprentissage prospectif présente le plus faible taux de transfert en chaînage arrière et d’interférence. Le méta-apprentissage et la modulation des taux d’apprentissage combinés révèlent une amélioration de plus de 10 % et 18 % (à mesure que le nombre de tâches augmente du CIFAR à Imagenet) par rapport à la méta-rediffusion de l’expérience, qui constitue souvent une ligne de base très solide. Cela démontre que l’optimisation des taux d’apprentissage facilite l’apprentissage et que notre actualisation asynchrone contribue à la consolidation des connaissances en imposant des actualisations prudentes pour atténuer les interférences. Des résultats plus complets, sur un ensemble plus vaste de lignes de base et d’ablations du méta-apprentissage prospectif, sont présentés dans cet article.
Conclusion
Dans cet article, nous avons présenté brièvement le méta-apprentissage prospectif, un algorithme de méta-apprentissage efficace qui tire parti de la rediffusion pour éviter l’oubli et favorise un transfert en chaînage arrière positif en apprenant les pondérations et les taux d’apprentissage de manière asynchrone. Le méta-apprentissage prospectif est en mesure d’apprendre en ligne sur un flux de données non stationnaire et de s’adapter aux tâches de vision. À l’avenir, il faudra travailler davantage à l’analyse et à la production de bons optimiseurs pour l’apprentissage continu, car nombre de nos optimiseurs standard visent à assurer une convergence plus rapide des configurations d’apprentissage stationnaires.
Pour plus de renseignements, consultez notre :
Article (qui fera l’objet d’une présentation orale à NeurIPS 2020) : [https://arxiv.org/abs/2007.13904]
Code : https://github.com/montrealrobotics/La-MAML/
Références
[1] Chelsea Finn, Pieter Abbeel, and Sergey Levine. Model-agnostic meta-learning for fast adaptation of deepnetworks. InProceedings of the 34th International Conference on Machine Learning-Volume 70, pages1126–1135. JMLR. org, 2017
[2] Alex Nichol, Joshua Achiam, and John Schulman. On first-order meta-learning algorithms.arXiv preprintarXiv: 1803.02999, 2018
[3] Matthew Riemer, Ignacio Cases, Robert Ajemian, Miao Liu, Irina Rish, Yuhai Tu and Gerald Tesauro. Learning to learn without forgetting by maximizing transfer and minimizing interference. InInternational Conference on Learning Representations, 2019. URL: https://openreview.net/forum?id=B1gTShAct7.
[4] David Lopez-Paz and Marc'Aurelio Ranzato. Gradient episodic memory for continual learning. Advances in Neural Information Processing Systems, pages 6467–6476, 2017.
[5] Arslan Chaudhry, Marc'Aurelio Ranzato, Marcus Rohrbach, and Mohamed Elhoseiny. Efficient lifelonglearning with a-GEM. InInternational Conference on Learning Representations, 2019. URL: https://openreview.net/forum?id=Hkf2_sC5FX.
[6] Khurram Javed and Martha White. Meta-learning representations for continual learning. Advances inNeural Information Processing Systems, pages 1818–1828, 2019.


