


Editor's Note: The work presented in this post was conjointly written with Karmesh Yadav of Carnegie Mellon University and is based on a paper to be presented in the Oral track at NeurIPS 2020.
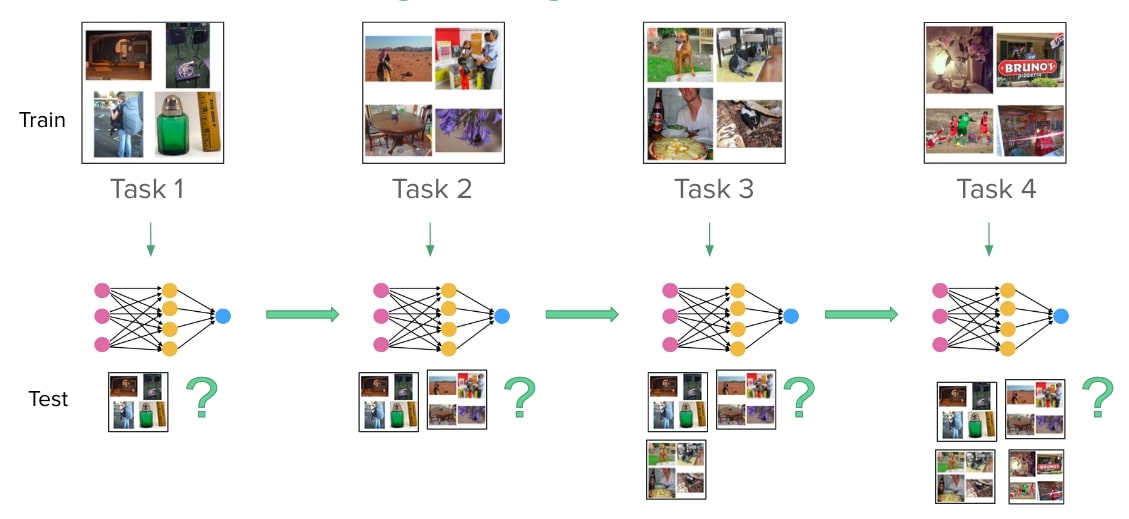
The continual learning (CL) problem involves training models with limited capacity to perform well on a set of an unknown number of sequentially arriving tasks.
Catastrophic forgetting is one of the biggest challenges in this setup. As defined on Wikipedia, it is the tendency of an artificial neural network to completely and abruptly forget previously learned information upon learning new information. It occurs because the i.i.d. sampling conditions required by stochastic gradient descent are violated when the data from different tasks arrives sequentially.
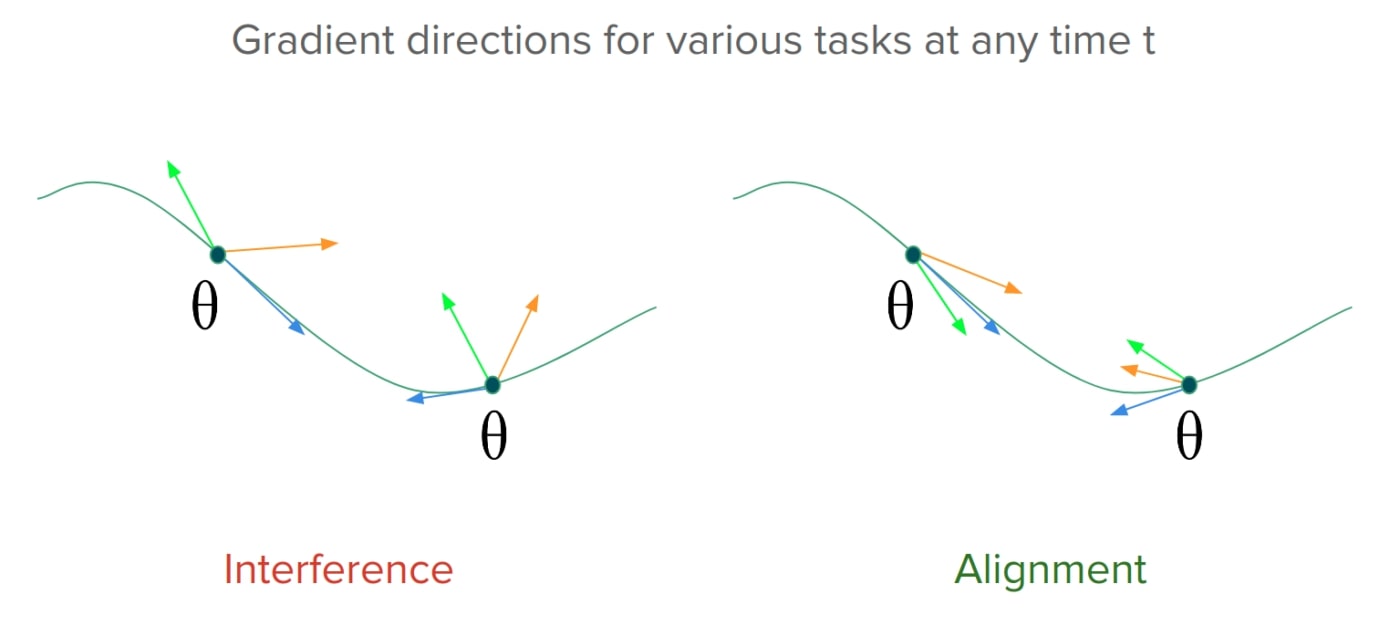
One way to look at the problem of forgetting is through the lens of gradient interference, or negative gradient alignment, as can be seen on the left in the following figure (Figure 2). We see that the task-wise gradients for a model's parameters conflict with each other in certain parts of the parameter space. The performance would thus degrade on the old tasks because the gradient updates made while learning a new task don't align with gradients directions for the old tasks. On the right of the image is an ideal scenario, where the gradients align and therefore progress on learning a new task, which coincides with progress on the old ones. Ensuring gradient-alignment is therefore essential to make shared progress on task-wise objectives under limited availability of training-data. As we will see, this kind of alignment across tasks can be achieved by exploiting some properties of meta-learning based gradient updates.
Why Meta-Learning?
One of the most common applications of meta-learning is few-shot learning. Upon closer inspection of the meta-learning gradients (derived in the Reptile paper [2]), one can see that the way it facilitates few-shot generalization is through gradient alignment.
Let us quickly recap the simplest gradient-based meta-learning algorithm, Model Agnostic Meta-Learning (MAML) [1]. Suppose we want to train a model to be good at learning from a handful of samples from any data distribution, such that it performs well on unseen samples of this distribution. We can think of this as wanting to optimize two objectives, the one we minimize when we learn on the handful of samples (or [latex] L_ {inner} [/latex]) and the one we test the model on once it has completed learning on the handful of samples (let's call this [latex] L_ {outer} [/latex], it is evaluated on unseen samples from the distribution). The meta-learning update of MAML (depicted in the following figure) proposes to evaluate [latex] L_ {outer} [/latex] on the parameter vector ([latex] \theta_4 [/latex]) obtained after taking a few gradient steps minimizing [latex] L_ {inner} [/latex] starting from an initial vector [latex] \theta_0 [/latex]. The gradient of this [latex] L_ {outer} [/latex], when evaluated w.r.t. [latex] \theta_0 [/latex], will push [latex] \theta_0 [/latex] in a direction where both [latex] L_ {inner} [/latex] and [latex] L_ {outer} [/latex] decrease while the alignment between their gradients increases.
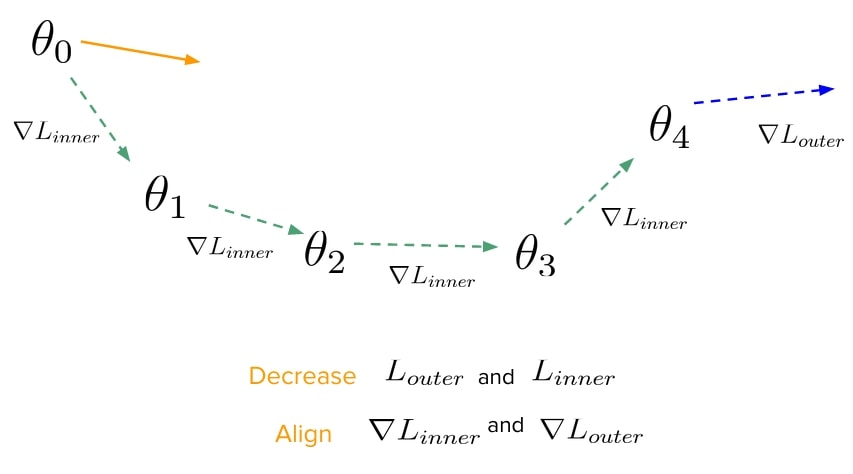
This intuitively makes sense, because the only way to make progress on unseen data (seen for [latex] L_ {outer} [/latex]) is to somehow have the gradients on that data be aligned with the actual gradient steps taken by the model on some seen data (seen during [latex] L_ {inner} [/latex]) (in this case, the few-shot samples).
Gradient Alignment: Gradient Episodic Memory (GEM) [4] and its follow-up, A-GEM [5] formulated the CL problem in terms of minimizing gradient interference. While few-shot meta-learning cares about encouraging alignment within tasks, in CL we want to encourage alignment within-and-across tasks. While GEM solves a quadratic program to get the gradient direction that maximally aligns with the gradient on old and new tasks, AGEM simply clips the gradients on new tasks such that they have no component that interferes with old tasks. Meta-Experience Replay (MER) [3] realized that the gradient-alignment based objective of GEM was roughly equivalent to that of first-order meta-learning algorithm Reptile and proposed a replay-based meta-learning algorithm that learned a sequence of tasks while increasing alignment between task-wise objectives.
Online-Aware Meta Learning (OML): Besides incentivizing alignment, meta-learning can also directly influence model optimisation to optimise auxiliary objectives like generalisation, by testing them in the outer loop of learning. This technique of composing objectives was recently explored for continual learning by Javed et. al [6] which proposed pre-training a representation through meta-learning, using catastrophic forgetting as the learning signal in the outer objective. The parameters of a representation learning network (RLN) are fixed, and a task learning network (TLN) further processes the representation and learns continually from a stream of incoming samples. After short intervals, the RLN+TLN is repeatedly evaluated on a set of held-out tasks to measure the forgetting that would've taken place. This meta-learning signal, when backpropagated to the RLN over many epochs leads to it learning a representation that is resistant to catastrophic forgetting and has emergent sparsity. This composition of two losses to simulate continual learning in the inner loop and test forgetting in the outer loop is referred to as the OML objective.
How La-MAML Works
The shortcoming of meta-learning algorithms for continual learning so far is that they have been slow, offline and/or hard to tune. In this work, we overcome these difficulties and unite the insights from OML and MER to develop a meta-learning algorithm for efficient, online continual learning.
Given what we discussed in the last section, it seems like a natural solution is to optimise the OML objective online for all the parameters of a model through a MAML update. Here, the inner objective would be to learn from the incoming data in the streaming task while the outer objective would be to test the adapted parameters on data sampled from all the tasks seen so far. Since data is available only while it is streaming, we could sub-sample and store some of it in a replay buffer and later sample data from it for evaluation in the outer objective.
Simple right? There's one step remaining, we first need to prove that this way of learning optimises the correct objective for continual learning. We derive the gradients of our MAML objective and show their equivalence to that of AGEM's objective in the paper. We refer to this base algorithm as Continual-MAML (C-MAML).
We show in the paper that our version of the meta-objective learns faster - since it aligns the average gradient on the old task data with the gradient on the new task's data instead of trying to align all tasks' gradients with each other (as in MER). We show empirically that the gradient alignment even across the old tasks still remains positive throughout training even when not explicitly incentivized. In addition:
- We note that there is an optimization challenge in CL: using decaying LR schedules to get faster convergence to some minima is not possible here since we have a non-stationary data distribution. However, adaptivity in LRs is still highly desired to better adapt to the optimization landscape, accelerate learning and even to modulate the degree of adaptation to reduce catastrophic forgetting in CL.
- We thus propose La-MAML (depicted in Figure 4, below), where we also optimise over a set of learnable per-parameter learning rates (LRs) to be used in the inner updates. The differences between C-MAML and La-MAML are the [latex] \alpha^j [/latex]'s used as the LR vector in the inner update and updated in the meta-update.

This is motivated by our observation that the expression for the gradient of the OML objective with respect to these LRs directly reflects the alignment between the old and new tasks.
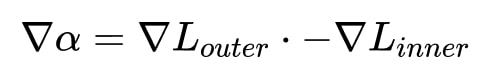
Therefore, the LRs get updated to higher values if the gradients across old and new tasks align for a parameter and get decreased if they interfere.
We propose updating the LRs first and then using them to carry out the weight update in the meta-updates so that the meta-objective conservatively modulates the pace and direction of learning. This serves to achieve quicker learning progress on a new task while facilitating transfer on old tasks. Note that clipping gradients excessively can sacrifice progress on new tasks, and is only one half of the solution. The ideal solution should try to align gradients across tasks in the first place so that one doesn't need to clip them as much later on - this is something that happens in La-MAML - which gives it an edge over AGEM which simply clips gradients and over MER/GEM to try to align them more.
Experiments
We conduct experiments where the model is asked to learn a set of sequentially streaming classification tasks. Experiments are performed on the MNIST, CIFAR and TinyImagenet datasets in the Single and Multiple-Pass setups where data within a task is allowed to be processed for single or multiple epochs respectively. The experiments cover both task-aware and task-agnostic setups.
To compare various approaches, we use the retained accuracy (RA) - the average accuracy across tasks at the end of training - and backward-transfer and interference (BTI) - the average change in the accuracy of each task from when it was learnt to the end of the last task. A smaller BTI implies lesser forgetting during training.
We compare C-MAML and La-MAML against various prior approaches in online continual learning including Experience Replay (ER), iCarl and GEM among others. We also perform multiple ablations for La-MAML, where we use and update the LRs in different ways to understand the benefits of our proposed modulation.
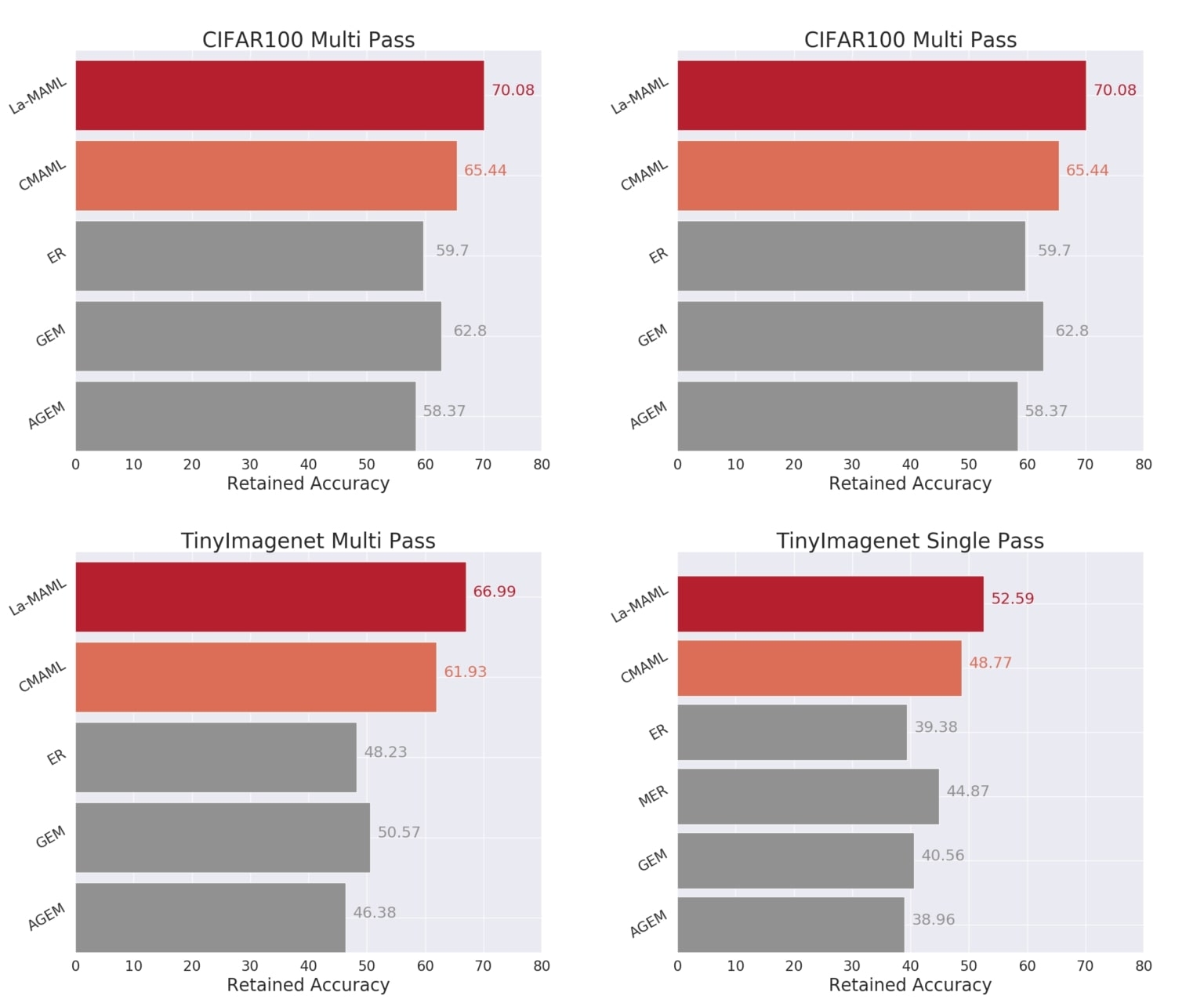
The figure above (Figure 5) reports the results of our experiments for some of the baselines. We consistently observe superior performance of La-MAML as compared to other CL baselines on both datasets across setups. Among the high-performing approaches, La-MAML has the lowest BTI. Combined meta-learning and LR modulation show an improvement of more than 10% and 18% (as the number of tasks increases from CIFAR to Imagenet) over the ER, which is often a very strong baseline. This shows that optimizing the LRs aids learning and our asynchronous update helps in knowledge consolidation by enforcing conservative updates to mitigate interference. More comprehensive results with a wider set of baselines and ablations of La-MAML can be found in the paper.
Conclusion
In this post, we gave a brief introduction to La-MAML, an efficient meta-learning algorithm that leverages replay to avoid forgetting and favors positive backward transfer by learning the weights and LRs in an asynchronous manner. It is capable of learning online on a non-stationary stream of data and scales to vision tasks. In the future, more work on analyzing and producing good optimizers for CL is needed, since many of our standard go-to optimizers are aimed at ensuring faster convergence in stationary learning setups.
For more information, check out our:
- Paper (to be presented in the Oral track at NeurIPS 2020): https://arxiv.org/abs/2007.13904
- Code: https://github.com/montrealrobotics/La-MAML/
References
[1] Chelsea Finn, Pieter Abbeel, and Sergey Levine. Model-agnostic meta-learning for fast adaptation of deepnetworks. InProceedings of the 34th International Conference on Machine Learning-Volume 70, pages1126–1135. JMLR. org, 2017
[2] Alex Nichol, Joshua Achiam, and John Schulman. On first-order meta-learning algorithms.arXiv preprintarXiv: 1803.02999, 2018
[3] Matthew Riemer, Ignacio Cases, Robert Ajemian, Miao Liu, Irina Rish, Yuhai Tu and Gerald Tesauro. Learning to learn without forgetting by maximizing transfer and minimizing interference. InInternational Conference on Learning Representations, 2019. URL: https://openreview.net/forum?id=B1gTShAct7.
[4] David Lopez-Paz and Marc'Aurelio Ranzato. Gradient episodic memory for continual learning. InAdvances in Neural Information Processing Systems, pages 6467–6476, 2017.
[5] Arslan Chaudhry, Marc'Aurelio Ranzato, Marcus Rohrbach, and Mohamed Elhoseiny. Efficient lifelonglearning with a-GEM. InInternational Conference on Learning Representations, 2019. URL: https://openreview.net/forum?id=Hkf2_sC5FX.
[6] Khurram Javed and Martha White. Meta-learning representations for continual learning. InAdvances inNeural Information Processing Systems, pages 1818–1828, 2019.


