


Introduction
L’apprentissage profond a transformé l’intelligence artificielle dans divers domaines. Cela a permis d’atteindre des performances sans précédent dans le traitement de la parole, du son, de l’image et du texte. Un domaine qui connaît des progrès remarquables est l’IA conversationnelle. C’est la technologie qui permet aux machines d’engager des conversations naturelles avec les humains. Les technologies d’IA conversationnelle ont gagné en popularité, en grande partie grâce aux assistants vocaux modernes comme Siri, Alexa et Google Home, ainsi qu’aux agents conversationnels comme Chat-GPT, Gemini et Claude. Des millions d’utilisateurs et d’utilisatrices dans le monde entier ont recours à ces technologies tous les jours. Néanmoins, un défi considérable réside dans son caractère de plus en plus exclusif : seule une poignée d’entreprises dispose en effet des ressources nécessaires pour entraîner des modèles de pointe, laissant de nombreux laboratoires universitaires et jeunes pousses à la traîne. De plus, la difficulté de reproduire les modèles conversationnels de pointe est d’autant plus grande que les données et les méthodes d’entraînement nécessaires ne sont généralement pas mises à la disposition du public. Cela exacerbe la crise de reproductibilité dans le domaine.
Pour atténuer ce problème, nous avons lancé SpeechBrain en 2020 en tant que projet de Mila visant à rendre l’IA conversationnelle plus inclusive. Notre trousse à outils en source ouverte aide les chercheur·euse·s, les praticien·ne·s et les étudiant·e·s débutant·e·s ayant une formation de base en informatique à développer des techniques d’IA conversationnelle. Nous l’avons conçu pour accélérer et simplifier le développement et la recherche de technologies d’IA conversationnelle. SpeechBrain offre transparence et reproductibilité en publiant des modèles et leurs « recettes » connexes, qui contiennent tous les codes et algorithmes nécessaires à l’entraînement des modèles à partir de zéro. Notre engagement en faveur d’un véritable code en source ouverte va au-delà de l’accès aux modèles et englobe l’ensemble du processus de création de modèles, ce qui favorise une recherche ouverte, transparente et reproductible.
Fort de ses 140 contributeurs et contributrices et du soutien d’institutions comme Mila, l’Université Concordia, l’Université d’Avignon, Samsung AI et l’Université de Cambridge, entre autres, SpeechBrain a été créé en 2020 par Mirco Ravanelli, actuellement professeur adjoint à l’Université Concordia (anciennement postdoctorant à Mila), et Titouan Parcollet, alors professeur agrégé à l’Université d’Avignon et aujourd’hui à l’emploi de Samsung AI (et chargé de cours affilié à l’Université de Cambridge). Notre trousse à outils est rapidement devenue l’une des plus populaires pour le traitement de la parole. Elle a déjà été téléchargée par des millions de personnes dans le monde entier et a obtenu plus de 7,8 millions d’étoiles sur GitHub.
Au cours de l’année écoulée, notre communauté de bénévoles a travaillé d’arrache-pied. Aujourd’hui, nous sommes ravis de vous annoncer que nous avons lancé SpeechBrain 1.0, ce qui représente une avancée remarquable pour notre projet. SpeechBrain 1.0 propose plus de 200 recettes et 100 modèles préentraînés sur HuggingFace. Cette version étend la prise en charge à divers ensembles de données et tâches, y compris le traitement du langage naturel et le traitement des électroencéphalogrammes. De plus, elle introduit de nouvelles fonctionnalités comme les modèles de parole génératifs, la traduction de parole à parole, la compréhension du langage parlé, la reconnaissance vocale émotionnelle et les techniques d’apprentissage profond interprétables. Nous avons mis au point des interfaces pour prendre en charge et personnaliser les grands modèles de langage à source ouverte les plus populaires, comme Llama2. La trousse à outils excelle désormais dans l’IA conversationnelle et dans diverses applications de traitement de séquences, offrant une performance concurrentielle ou à la pointe de la technologie pour de nombreuses tâches. Nous avons créé un nouveau référentiel consacré aux benchmarks, qui aide les chercheurs et chercheuses à comparer leurs travaux avec d’autres en utilisant des ensembles de données et des modèles bien connus. Pour l’instant, il propose des modèles de référence dans différents domaines, comme les modèles auto-supervisés grâce à la parole, l’apprentissage continu et le traitement des électroencéphalogrammes. Vous trouverez ici un aperçu plus détaillé des nouvelles fonctionnalités.
À l’avenir, nous continuerons à nous concentrer sur le service à la communauté. Nous voulons à la fois augmenter et réduire l’échelle de SpeechBrain. Pour obtenir les meilleurs résultats, il est essentiel d’agrandir les modèles et d’utiliser davantage de données. Nous sommes d’avis que cet objectif ambitieux n’est possible que grâce à un effort de collaboration de la part de la communauté. Il est tout aussi important de réduire l’échelle de cette technologie. Les modèles massifs actuellement utilisés sont très gourmands en calculs, ce qui entraîne des coûts et un impact environnemental considérables. Nous prévoyons de consacrer nos efforts de recherche à la réduction d’échelle et à la mise au point de techniques d’apprentissage profond novatrices capables d’être performantes à des échelles plus accessibles à tout le monde.
Technologie
Notre vision a été profondément inspirée par le fonctionnement du cerveau humain. Notre objectif à long terme est de mettre au point une technologie qui reflète les capacités de communication du cerveau, permettant à notre trousse à outils de reconnaître la parole et d’en comprendre le contenu sémantique, la langue, les émotions et les caractéristiques de la personne qui parle, pour finalement engager des conversations naturelles avec les êtres humains.
Je tiens à souligner que notre vision ne se limite pas aux interactions textuelles avec les machines, comme le font les grands modèles de langage actuels. Aujourd’hui, la façon dont nous interagissons avec les machines est souvent banale, ennuyeuse et déconnectée. Nous sommes fermement convaincus qu’une communication engageante implique la prise en compte de divers facteurs, notamment l’état émotionnel de la personne qui parle, l’environnement acoustique et les caractéristiques propres à cette personne, comme son âge, son accent et son origine culturelle. Cette approche nécessite de lier différentes technologies par une approche holistique, ce que nous faisons aujourd’hui avec SpeechBrain en ayant recours à l’apprentissage profond.
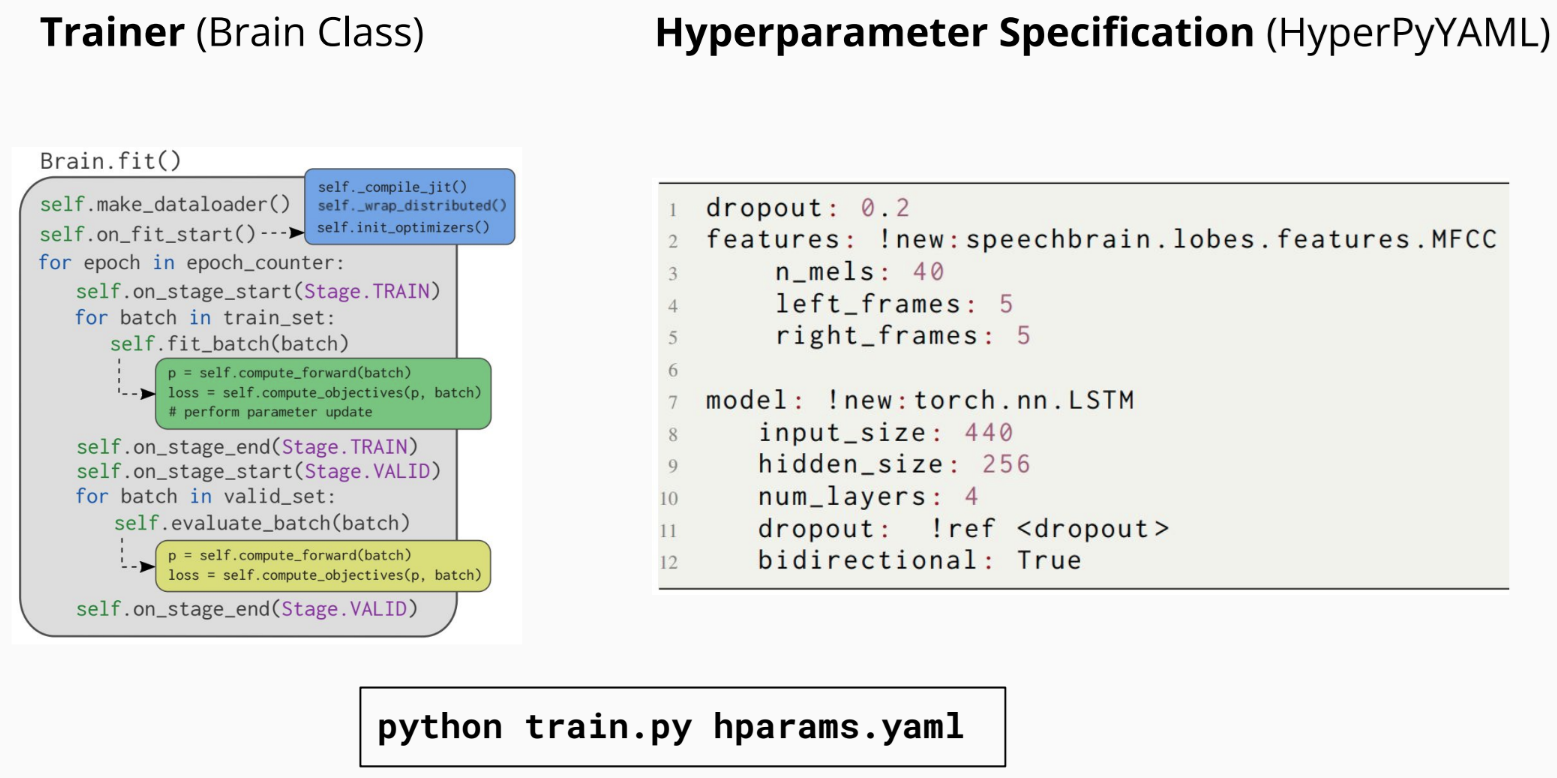
Nous avons créé une architecture logicielle qui correspond à notre vision. Comme le montre la figure ci-dessus, chaque tâche de SpeechBrain suit la même structure de code pour faciliter son utilisation. Tous les hyperparamètres sont stockés dans un fichier YAML, dans lequel nous spécifions les hyperparamètres du modèle et configurons les classes ou les fonctions qui les utiliseront. Par exemple, dans la figure ci-dessus (à droite), nous définissons le paramètre « dropout », que le modèle LSTM utilisera. Les hyperparamètres sont fournis à un script Python (entraîneur) chargé de coordonner toutes les étapes nécessaires à l’entraînement du modèle. Nous avons tout conçu de manière à ce que tout soit flexible et facilement personnalisable. Par exemple, les utilisateurs et utilisatrices peuvent facilement ajuster tous les calculs pour mettre en œuvre des fonctionnalités précises, comme le calcul à terme, les pertes, etc. Les utilisateurs et utilisatrices peuvent passer d’une tâche à l’autre de manière très naturelle, car la structure fondamentale du code reste cohérente.
Cas d’utilisation
SpeechBrain est conçu pour faciliter le développement des technologies d’IA conversationnelle. Nous l’avons créé à l’intention des chercheur·euse·s, des praticien·ne·s et des étudiant·e·s en début d’apprentissage, ainsi que des ingénieur·e·s logiciels qui participent à des projets d’IA conversationnelle au sein tant de petites pousses que de grandes sociétés. Dans la dernière partie de ce billet de blogue, nous aimerions explorer plusieurs cas d’utilisation où SpeechBrain peut être particulièrement efficace :
A) Scénario de recherche
Imaginez que vous êtes un·e chercheur·euse en apprentissage profond avide de tester son modèle fantaisiste dans une tâche de traitement de la parole, comme la reconnaissance vocale. Vous pouvez facilement intégrer votre modèle dans les pipelines actuels et comparer sa performance avec celle des modèles de pointe déjà disponibles dans SpeechBrain. Cette fonctionnalité accélère considérablement votre recherche.
B) Scénario d’éducation
Imaginez maintenant que vous êtes un·e étudiant·e en début de carrière, peut-être au premier cycle, qui possède des connaissances de base en matière de programmation et d’informatique. Si vous souhaitez vous familiariser avec les technologies d’IA conversationnelle, SpeechBrain est la solution idéale. SpeechBrain facilite votre démarche d’apprentissage en offrant une documentation complète à différents niveaux, y compris des tutoriels expliquant la technologie de l’IA conversationnelle et sa mise en œuvre. SpeechBrain est utilisé dans le cours d’IA conversationnelle (COMP 499/691 à l’Université Concordia), et même les étudiant·e·s de premier cycle peuvent comprendre comment l’utiliser pour mettre en œuvre des technologies de la parole après une brève courbe d’apprentissage.
C) Scénario d’industrie
De plus en plus d’entreprises font appel à SpeechBrain pour développer leurs produits. Imaginez-vous travaillant dans une telle entreprise, où vous devez présenter une démonstration de faisabilité à vos responsables dans un délai serré. Nous avons conçu SpeechBrain dans le but de simplifier et d’accélérer le développement des technologies de la parole. Vous pouvez rapidement créer des prototypes et affiner vos idées jusqu’à ce qu’elles répondent aux normes requises, ce qui permet aux entreprises d’innover de façon rapide et efficace.
D) Scénario pour les praticien·ne·s
Enfin, imaginez que vous vous passionnez pour l’apprentissage profond et que vous souhaitez acquérir une expérience pratique en matière d’IA conversationnelle. Vous cherchez à en savoir plus en créant des modèles personnalisés en fonction de vos besoins particuliers (p. ex., un système de reconnaissance de la parole adapté à votre voix ou un système de repérage de mots clés répondant à des mots clés personnalisés). SpeechBrain va vous aider.
Grâce à sa vaste collection de modèles préentraînés et de recettes d’entraînement, SpeechBrain constitue la trousse à outils idéale pour personnaliser les modèles. Qu’il s’agisse d’affiner des modèles existants ou d’en créer de nouveaux, SpeechBrain aide les praticiens et les praticiennes à explorer un sujet difficile comme l’IA conversationnelle au moyen d’un apprentissage pratique.
Remerciements
Nous tenons à remercier chaleureusement toutes les personnes qui ont contribué à ce projet et qui ont généreusement mis leur temps et leur expertise au service de la communauté. Nous exprimons également notre gratitude à tous nos commanditaires industriels, qui ont contribué par des fonds ou fourni les ressources informatiques nécessaires au développement et à l’entretien de notre projet (HuggingFace, OVHCloud, Baidu USA, ViaDialog, Samsung et Naver Labs Europe). Nous voudrions souligner le rôle crucial joué par le LIA (Laboratoire informatique d’Avignon), avec lequel nous avons établi une collaboration fructueuse à long terme. Enfin, nous encourageons tout le monde à donner une étoile à notre projet sur GitHub si notre contribution à la communauté est appréciée. Votre soutien est très important pour nous.
Références
Site Web SpeechBrain - https://speechbrain.github.io/
Référentiel de codes : https://github.com/speechbrain/speechbrain
Référentiel de modèles : https://huggingface.co/speechbrain
Document de référence : https://arxiv.org/abs/2106.04624


