



Introduction
Deep learning has transformed Artificial Intelligence across various domains, leading to unprecedented performance in speech, audio, image, and text processing. An area experiencing remarkable progress is Conversational AI, which is the technology behind machines engaging in natural conversations with humans. Conversational AI technologies have gained widespread popularity, largely due to modern speech assistants like Siri, Alexa, and Google Home, as well as chatbots such as Chat-GPT, Gemini, and Claude. Millions of users worldwide use this technology every day. Nevertheless, a significant challenge lies in its rapidly increasing exclusivity: only a handful of companies, indeed, have the resources to train cutting-edge models, leaving many academic labs and startups behind. Furthermore, the difficulty in replicating state-of-the-art conversational models is made even more challenging by the fact that the necessary data and training methodologies are typically not made publicly available. This exacerbates a reproducibility crisis within the field.
To mitigate this issue, we started SpeechBrain in 2020 as a Mila project to make Conversational AI more inclusive. Our open-source toolkit helps researchers, practitioners, and early students with basic computer science backgrounds developing Conversational AI techniques. We designed it to make development and research of Conversational AI technologies faster and simpler.
SpeechBrain offers transparency and reproducibility by releasing models and their related "recipes," containing all necessary codes and algorithms for training the models from scratch. Our commitment to true open-source extends beyond model access to include the entire process of model creation, fostering open, transparent, and reproducible research.
With over 140 contributors and support from institutions like Mila, Concordia, Avignon University, Samsung AI, Cambridge University (just to name a few), SpeechBrain was founded in 2020 by Mirco Ravanelli, who is currently an assistant professor at Concordia University (formerly post-doc at Mila), and Titouan Parcollet, who was then an Associate Professor at Avignon University and is now with Samsung AI (and Affiliated Lecturer at the University of Cambridge). Our toolkit has quickly become one of the most popular toolkits for speech processing and it has already been downloaded by millions of users worldwide and reached more than 7.8k stars on GitHub.
During the past year, our community of volunteers has worked hard. Now, we are excited to share that we have launched SpeechBrain 1.0, a remarkable achievement for our project.
SpeechBrain 1.0 features over 200 recipes and 100 pretrained models available on HuggingFace. This version expands support to diverse datasets and tasks, including NLP and EEG processing, and introduces new functionalities such as generative speech models, speech-to-speech translation, spoken language understanding, emotional speech recognition, and interpretable deep learning techniques. We have developed interfaces to support and customize the most popular open-source large language models, such as Llama2. The toolkit now excels in Conversational AI and various sequence processing applications, providing competitive or state-of-the-art performance in many tasks. We created a new repository dedicated to benchmarks, which helps researchers compare their work with others using well-known datasets and models. Right now, it has benchmarks for different areas like speech self-supervised models, continual learning, and EEG processing. Please take a look here for a more detailed overview of the new features.
Our primary focus for the future remains on serving the community. We want to scale SpeechBrain both up and down. Making models bigger and using more data is essential to achieve the best results. We believe this ambitious goal is possible only through a collaborative community effort. Scaling down this technology is equally important. The massive models currently employed are highly computationally intensive, resulting in significant costs and environmental impact. We plan to dedicate research efforts towards downsizing and developing innovative deep learning techniques capable of performing effectively at scales that are more accessible to all.
Technology
Our vision has been deeply inspired by how the human brain works.
Our long-term goal is to develop technology that mirrors the communication abilities of the brain, enabling our toolkit to recognize speech and understand its semantic content, language, emotions, and speaker characteristics, ultimately engaging in natural conversations with humans.
I want to emphasize that our vision extends beyond text-based interactions with machines, as done by current large language models. The way we interact with machines today is often plain, annoying, and disconnected. I firmly believe that engaging communication involves considering various factors, including the emotional state of the speaker, analyzing the acoustic environment, and considering specific speaker characteristics such as age, accent, and cultural background. This approach requires connecting different technologies through a holistic approach, which is what nowadays we are doing with SpeechBrain using deep learning.
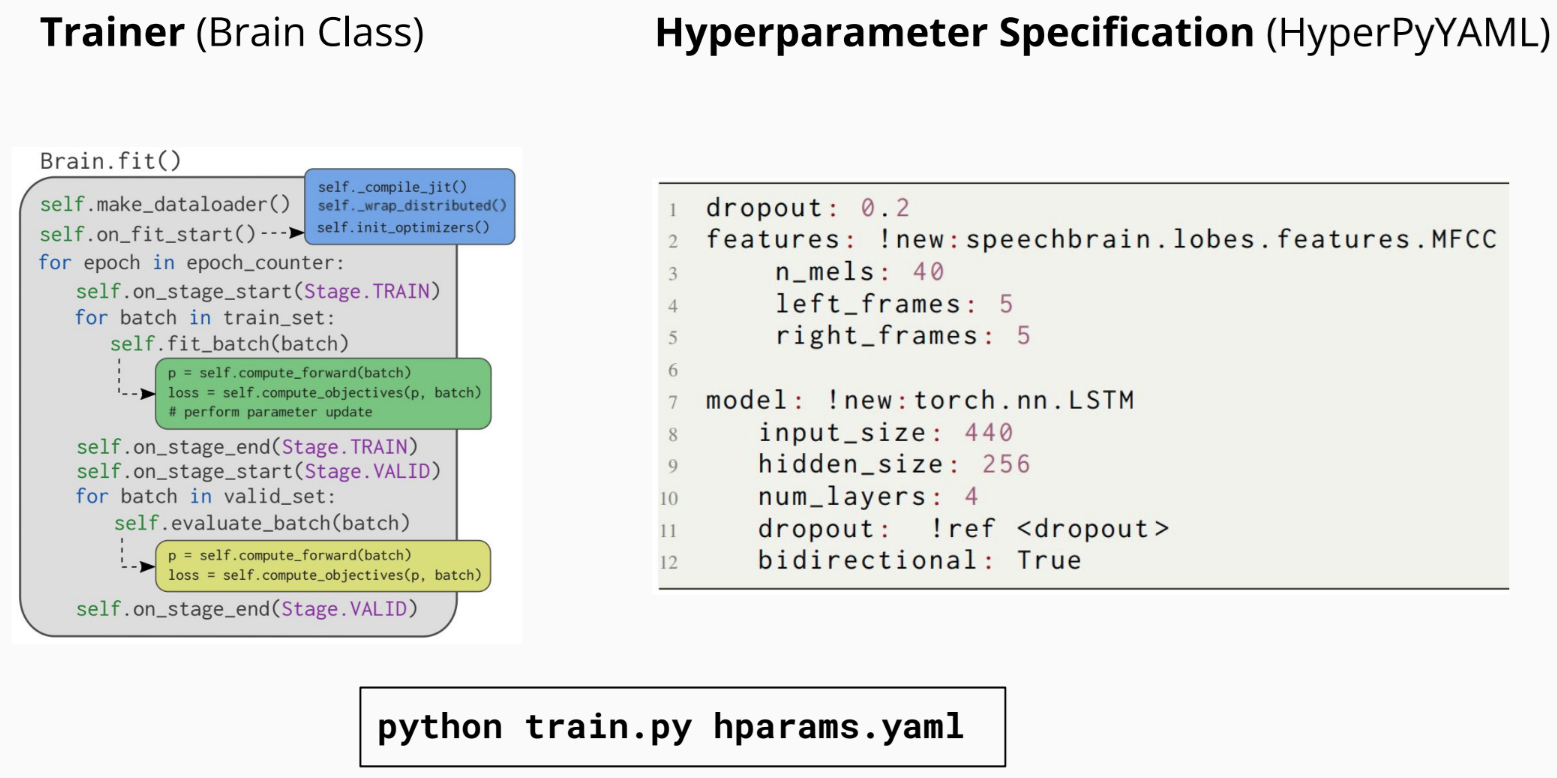
We created a software architecture to match our vision. As shown in the figure above, every task in SpeechBrain follows the same code structure to make it easier to use. All the hyperparameters are stored in a YAML file, where we specify the model's hyperparameters and set up the classes or functions that will utilize them. For example, in the figure above (right), we define the "dropout" parameter, which the LSTM model will use. The hyperparameters are provided to a Python script (trainer) responsible for coordinating all the necessary steps to train the model. We designed everything to be flexible and easily customizable. For example, users can easily adjust all computations to implement specific functionalities, such as forward computation, losses, and more. Users can jump from one task to another very naturally because the fundamental structure of the code remains consistent.
Use Cases
SpeechBrain is designed to facilitate the development of Conversational AI technologies. We created it for researchers, practitioners, and students in their early stages of learning, as well as for software engineers involved in Conversational AI projects across both small startups and large corporations. In the last part of this blog post, I'd like to explore several use cases where SpeechBrain can be particularly effective:
A) Research scenario
Imagine you are a deep learning researcher eager to test your fancy model in a speech-processing task like speech recognition. You can easily plug your model into the existing pipelines and compare its performance with the state-of-the-art models already available in SpeechBrain. This feature significantly speeds up your research.
B) Education Scenario
Now, picture yourself as an early-career student, perhaps an undergraduate with basic programming and computing knowledge. If you are keen to familiarize yourself with Conversational AI technologies,SpeechBrain is the way to go. SpeechBrain facilitates your learning journey by offering comprehensive documentation at various levels, including practical tutorials explaining Conversational AI technology and its implementation. I use SpeechBrain in my Conversational AI class (COMP 499/691 at Concordia University), and even undergraduates can grasp how to utilize SpeechBrain for implementing speech technologies after a brief learning curve.
C) Industrial Scenario
An increasing number of companies are using SpeechBrain to develop their products. Imagine yourself working in such a company, where you have to show a proof of concept to your supervisors within a tight timeframe. We engineered SpeechBrain to simplify and accelerate the development of speech technologies. You can rapidly prototype and refine your ideas until they meet the required standards, enabling companies to innovate quickly and effectively.
D) Practitioners Scenario
Finally, imagine you are a passionate practitioner of deep learning eager to gain hands-on experience in Conversational AI. You aim to learn more by creating customized models tailored to your specific needs (e.g., a speech recognizer tailored to your voice or a keyword spotting system responsive to custom keywords). SpeechBrain is going to help you.
With a large collection of pretrained models and training recipes, SpeechBrain provides the ideal toolkit for personalizing models. Whether you're fine-tuning existing models or creating entirely new ones, SpeechBrain helps practitioners explore a challenging topic like Conversational AI through hands-on learning.
Acknowledgement
I want to warmly thank all our contributors who generously donate their time and expertise to the community. I also express gratitude to all our industrial sponsors who have contributed with funds or provided computational resources necessary for the development and maintenance of our project (HuggingFace, OVHCloud, Baidu USA, ViaDialog, Samsung, Naver Labs Europe). I would like to remark on the crucial role played by LIA (Laboratoire Informatique d’Avignon), with which we established a long-term and productive collaboration. Finally, I would encourage everyone to star our project on GitHub if our contribution to the community is appreciated. Your support means a lot to us.
References
SpeechBrain Website - https://speechbrain.github.io/
Code Repository: https://github.com/speechbrain/speechbrain
Model Repository: https://huggingface.co/speechbrain
Reference Paper : https://arxiv.org/abs/2106.04624


