



Note de la rédaction : Basé sur des travaux présentés à la conférence ICLR 2022 dans la catégorie « Spotlight ».
Les systèmes basés sur l’attention ont provoqué un changement considérable au sein de l’écosystème de l’apprentissage automatique et ont pavé la voie à l’ère des modèles pré-entraînés à grande échelle. Ces modèles reposent en grande partie sur le mécanisme d’attention multi-têtes (multi-head attention ou MHA) qui est constitué de plusieurs flux d’attention parallèles. Dans le cadre de ce travail, nous proposons une interprétation d’inspiration cognitive des limites et des rigidités de cet algorithme. Nous présentons un nouveau mécanisme visant à résoudre certains des problèmes liés à ses contraintes.
Dans les sections ci-après, nous introduisons d’abord l’attention de type « clé-valeur » qui forme la base du MHA et la traitons en tant que mécanisme de recherche et de récupération. Dans cette optique, nous donnons un aperçu des limites du MHA tout en offrant une méthode alternative, appelée « Attention compositionnelle ». À travers nos expériences, nous constatons que cette dernière résout certains des défis liés au MHA.
Recherche et récupération
L’attention clé-valeur standard est une procédure de communication qui canalise les informations entre différents jetons (tokens). Elle combine une requête à des clés pour générer une recherche, soit un système de notation normalisé pouvant indiquer où accéder à l’information. Suite à la recherche, l’information réelle est récupérée à travers les valeurs, et ce, de manière normalisée grâce à une combinaison convexe.
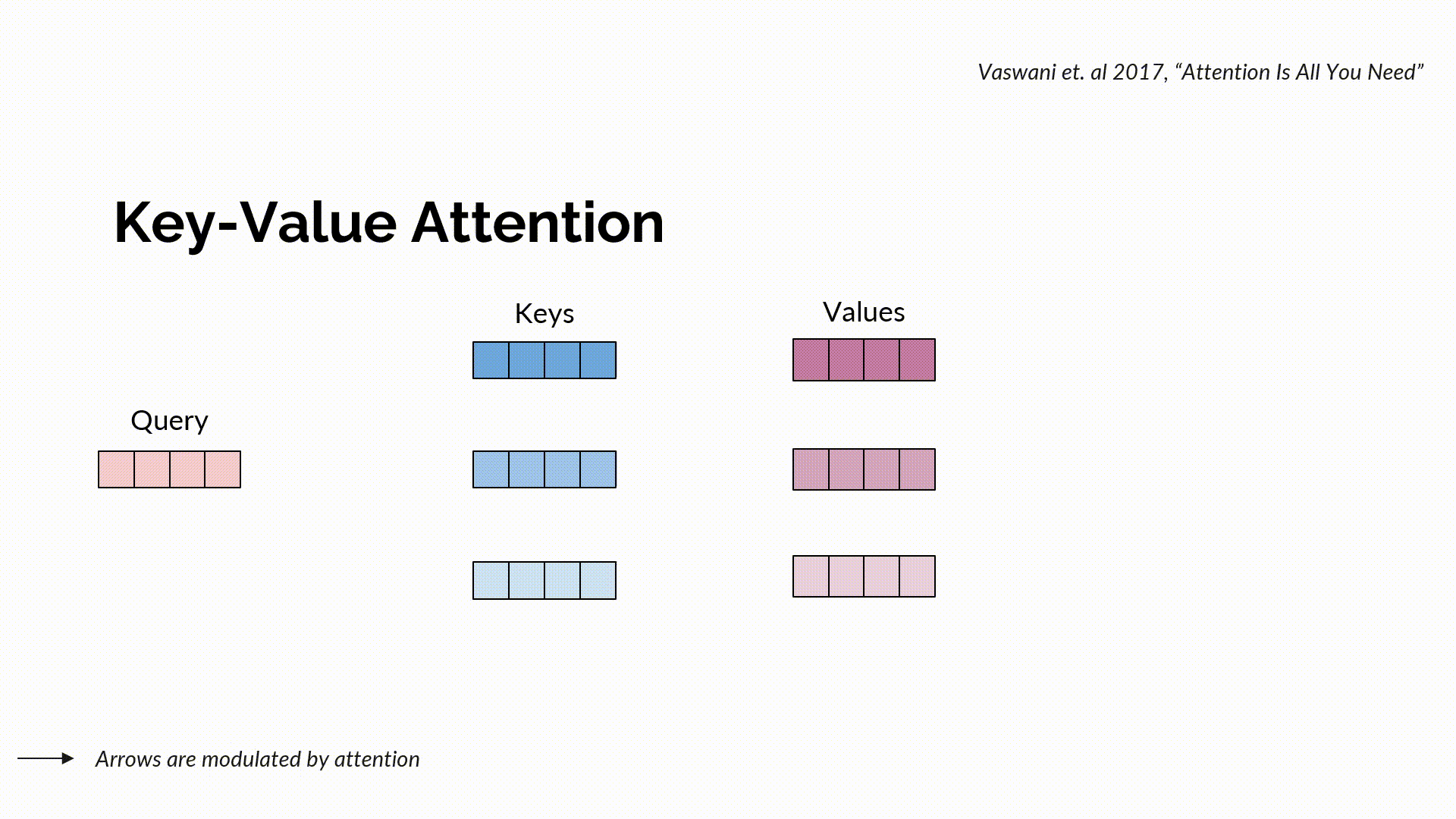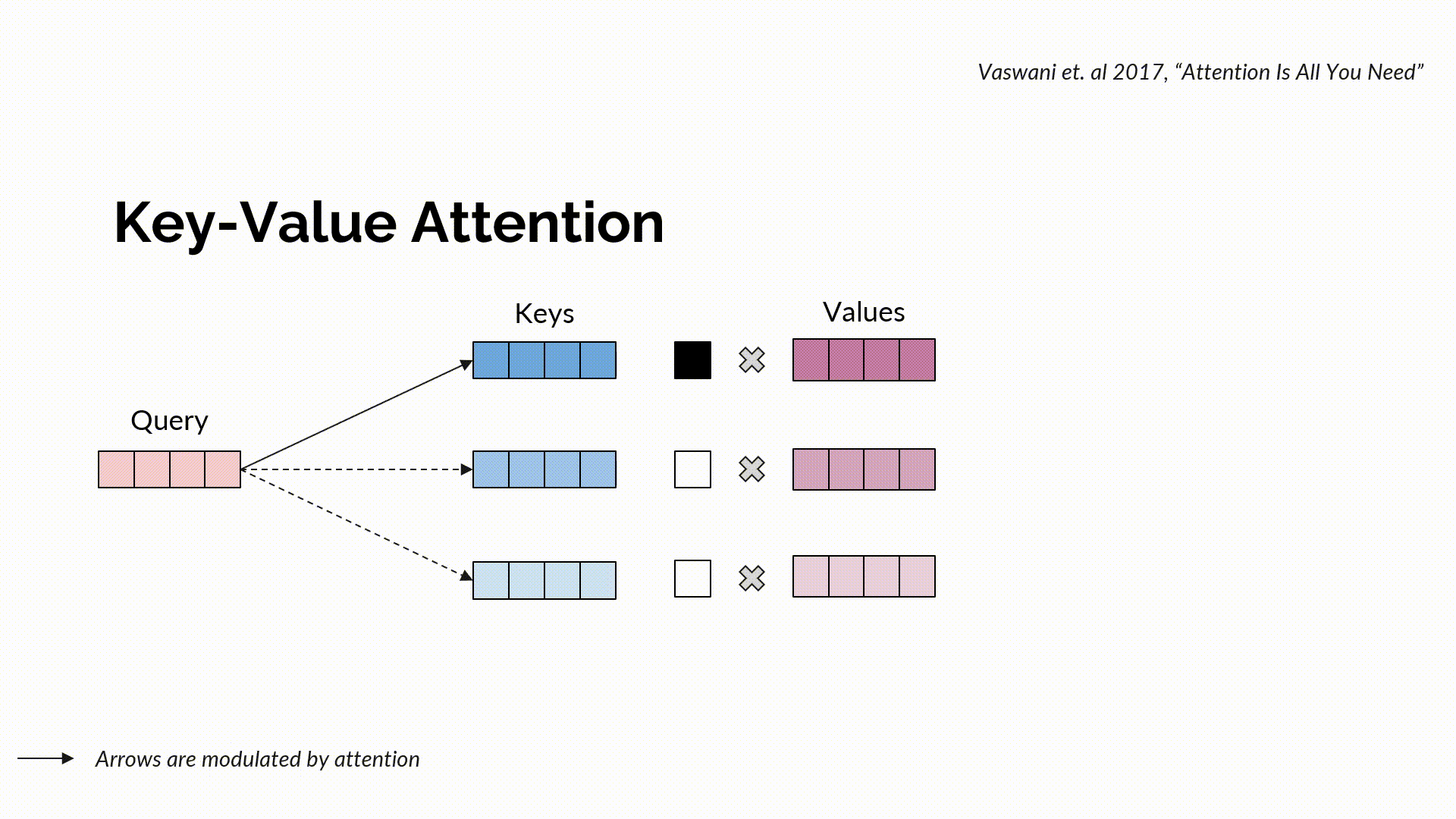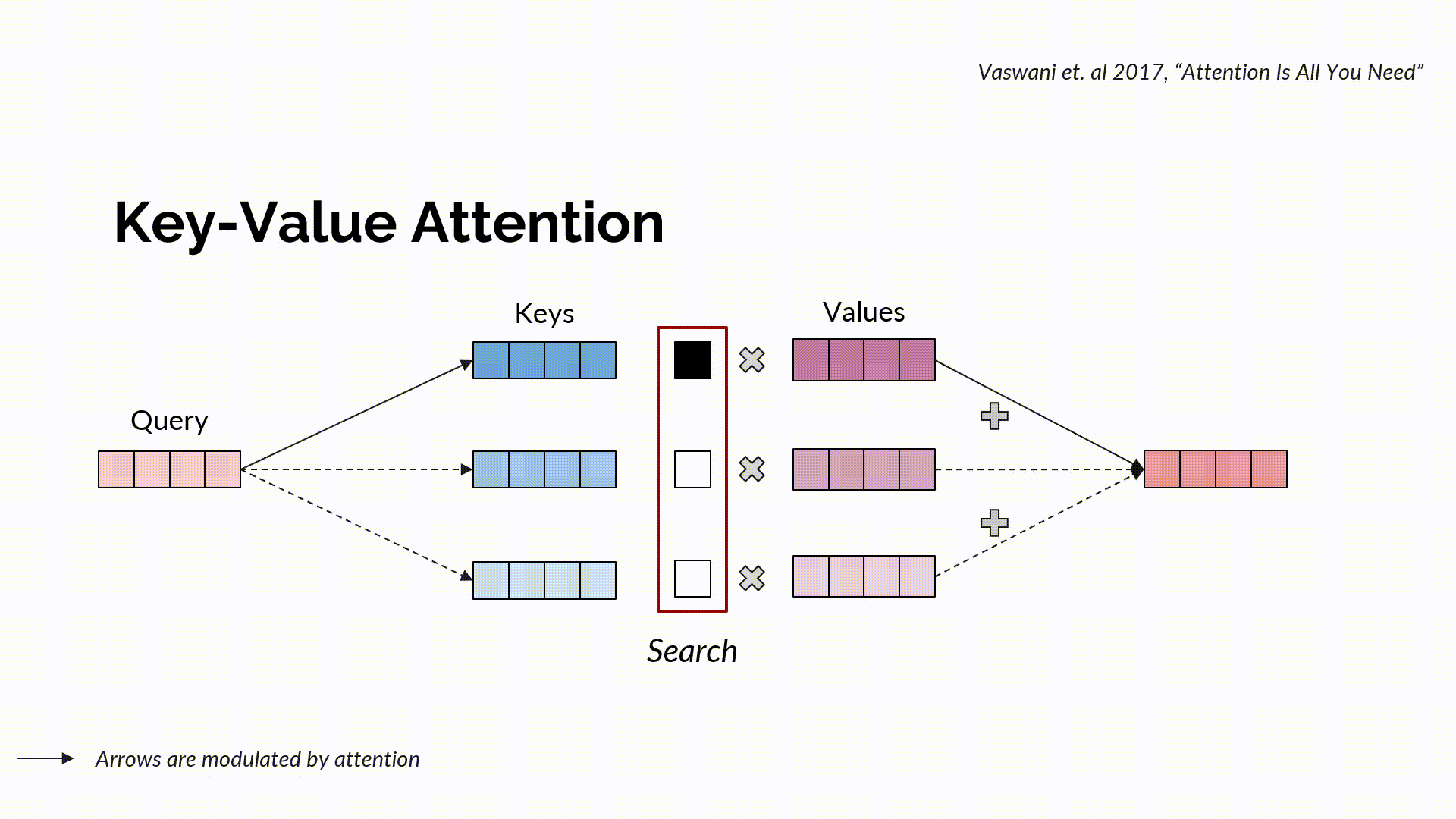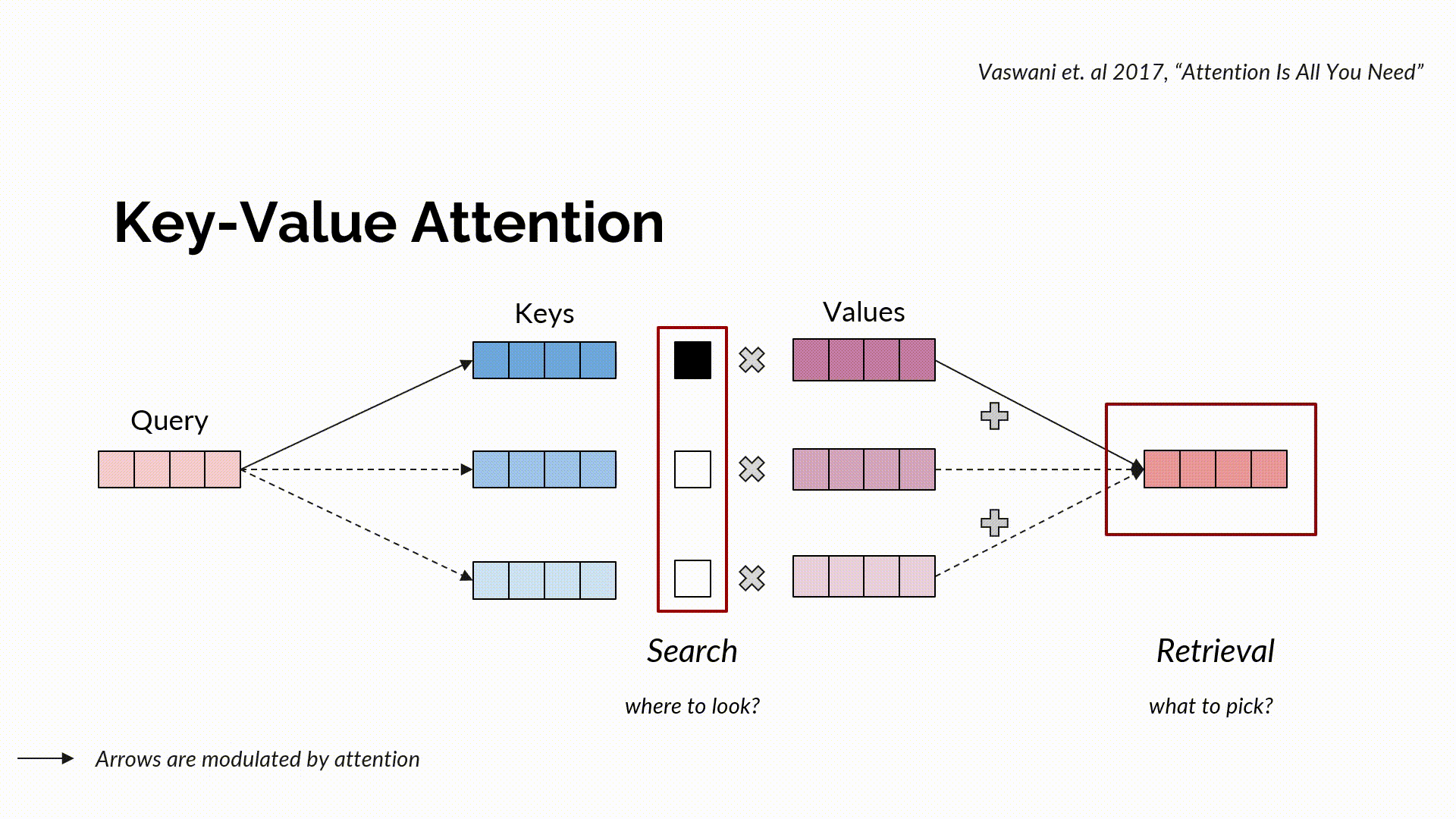
L’attention multi-têtes peut être perçue comme de multiples compositions parallèles de recherche et de récupération (chacune d’entre elles étant appelée une tête), où une recherche est définie en utilisant des vecteurs de requête et de clé, et une récupération grâce à la configuration des valeurs. Intuitivement, une fonction recherche indique où aller chercher par le biais du score de similarité d’une requête relatif aux clés. Les clés qui sont bien alignées avec les requêtes obtiennent des scores d’attention plus élevés que les autres. La fonction recherche correspond à une configuration de requêtes et de clés qui calcule le produit à point échelonné de la matrice de requête avec celle de la matrice de clé – qui est normalisée via la fonction softmax pour obtenir les scores d’attention. Tenant compte de la sortie de la recherche, la fonction récupération nous indique intuitivement ce qu’il faut choisir en effectuant une combinaison pondérée de l’attention avec les valeurs et en retournant les informations requises.
Étant donné que les différentes têtes ne partagent aucune information, les paires de recherche et de récupération du MHA sont assez rigides. Pour surmonter cette rigidité, nous proposons l’Attention compositionnelle qui permet d’intégrer un choix de repérage plug and play (« brancher et utiliser ») pour différentes recherches de manière flexible, dynamique et contextuelle. L’attention compositionnelle offre non seulement un ensemble plus global de mécanismes d’attention, mais aussi permet davantage de paires recherche-récupération que le MHA.
Illustration
Imaginez un monde orienté objet où chaque objet est composé de multiples caractéristiques telles que la forme, la couleur et l’emplacement. La tâche vise à fournir des réponses raisonnables aux questions basées sur ce monde. Ceci peut être considéré comme le visuel questions et réponses (VQA) – une tâche qui a gagné en popularité au sein de la communauté de l’apprentissage automatique au cours des dernières années.
Nous cherchons à obtenir une compréhension abstraite de haut niveau de ce que les différentes têtes d’un mécanisme d’attention multi-têtes devraient apprendre lorsqu’elles sont soumises à différents types de questions dans cette configuration. En utilisant le langage de la recherche et de la récupération, nous voyons que pour chaque type de question, un certain modèle de recherche et de récupération est appris dans les têtes. Dans le mécanisme d’attention multi-têtes standard, cela conduit à l’apprentissage de paramètres redondants.

Dans l’illustration ci-dessus, nous voyons que la connaissance possédée par la tête-3 est complètement redondante, car les parties individuelles existent déjà dans la tête-1 et la tête-2, mais la correspondance n’existe pas. Pour contrer cette redondance, nous proposons l’attention compositionnelle, qui vise des compositions flexibles de recherche et de récupération.
Méthode
Alors que les systèmes MHA ne peuvent modéliser qu’une correspondance biunivoque entre la recherche et la récupération, il faut allouer une toute nouvelle tête pour répondre à la troisième question, même si les éléments de connaissance individuels existent déjà dans les deux premières têtes et mènent à des redondances. Pour éliminer celles-ci, nous avons besoin d’une notion de partage de l’information entre les têtes. Nous y parvenons grâce à une sélection dynamique et contextuelle de la récupération pour chaque recherche, ce qui permet de partager les récupérations entre les recherches.
Dans l’attention compositionnelle, nous partageons les paramètres de récupération à travers toutes les recherches et effectuons ensuite des récupérations dynamiques en fonction du contexte. En procédant ainsi, nous assouplissons le couple statique recherche-récupération que l’on observe généralement dans le MHA et favorisons une plus grande flexibilité. Nous y parvenons en suivant les étapes suivantes :
- Nous effectuons d’abord \(S\) recherches parallèles (similaires à MHA) en transformant linéairement les plongements en requêtes et clés et en calculant leurs produits scalaires.
- Une fois les opérations de recherche effectuées, nous effectuons \(R\) récupérations possibles par recherche en combinant chaque recherche avec tous les ensembles de valeurs obtenus.
- Pour effectuer des récupérations contextuelles, nous utilisons un mécanisme d’attention secondaire qui combine les différentes récupérations \(R\) par recherche d’une manière normalisée.

Expériences
Nous testons le modèle que nous proposons sur diverses tâches allant de la prévision synthétique d’ensemble à ensemble et de la réponse à des questions visuelles à la classification d’images et à la modélisation du langage. Nous constatons de manière globale que l’attention compositionnelle surpasse l’attention multi-têtes dans ces différents contextes, souvent même avec moins de récupérations et dans des paramètres hors-distribution.
Tâche de récupération contextuelle
Cette tâche est formée d’un ensemble d’objets de faible dimension avec de multiples caractéristiques. Chaque objet doit accéder à d’autres objets et en extraire certaines caractéristiques pour résoudre une tâche simple en aval. Le choix des objets auxquels accéder et des caractéristiques à récupérer est fourni par des informations contextuelles, sous la forme de signaux à un coup. Cette suite de tâches est définie par le nombre de recherches (c’est-à-dire le nombre d’objets auxquels chaque objet doit accéder) et le nombre de récupérations (c’est-à-dire le nombre de caractéristiques qui peuvent être interrogées à partir de chaque objet). Non seulement nous constatons que l’attention compositionnelle surpasse l’attention multi-têtes, mais nous constatons également qu’elle peut mieux se généraliser dans des contextes hors-distribution où certaines combinaisons de recherches et de récupérations sont retirées de la distribution d’entraînement.
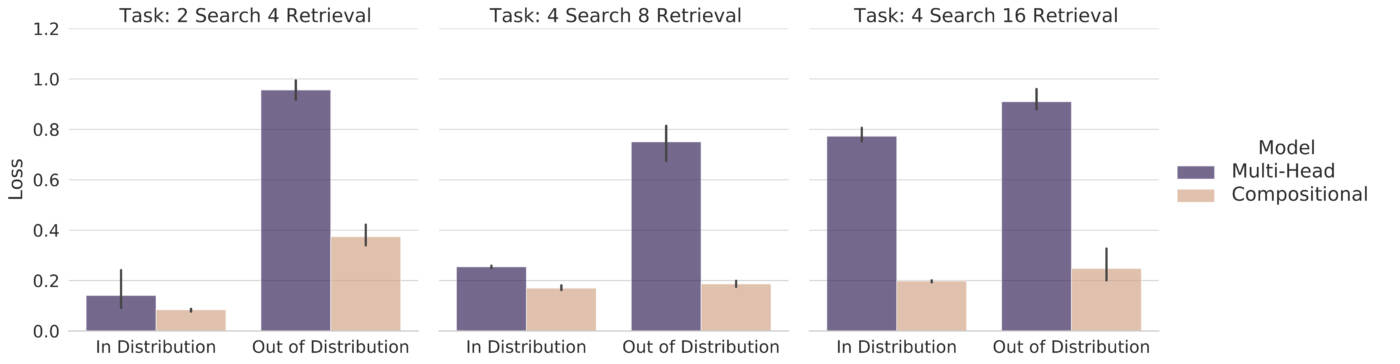
Tâche Sort-of-CLEVR
Nous expérimentons sur une tâche de réponse à une question visuelle basée sur le raisonnement qui consiste en une scène visuelle de plusieurs objets et une question relative au contexte visuel. La tâche comprend trois types de questions : (a) unaires, qui sont basées sur les propriétés d’objets uniques, (b) binaires, qui sont basées sur la relation entre deux objets, et (c) ternaires, qui sont basées sur la relation entre trois objets. Nous constatons généralement que l’attention compositionnelle surpasse l’attention multi-têtes pour tous les types de questions, et souvent avec un nombre inférieur de récupérations.
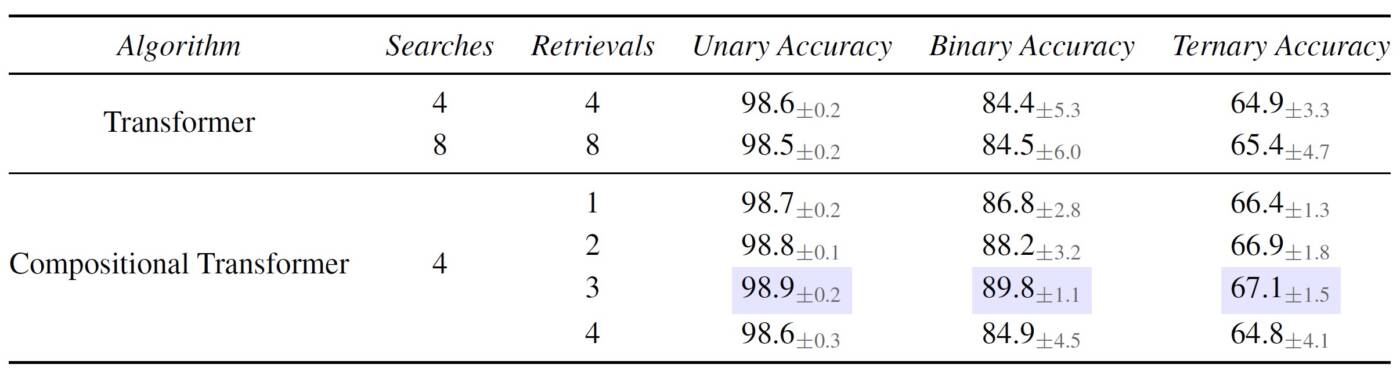
Tâche de modélisation du langage
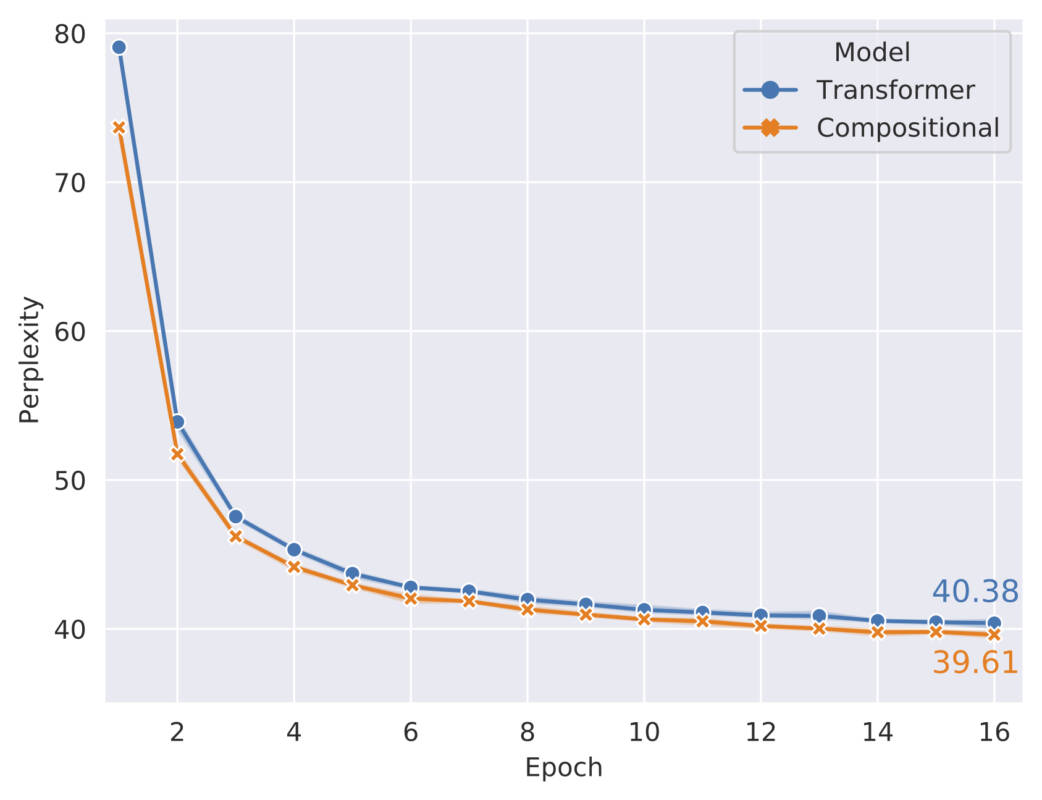
Nous réalisons également des expériences de modélisation du langage sur le jeu de données WikiText-103. Nous constatons qu’avec le même nombre de recherches et de récupérations, l’attention compositionnelle surpasse l’attention multi-têtes.
Pour plus d’informations, veuillez consulter notre publication arXiv et notre code.
Pour consulter mon site Web personnel : https://sarthmit.github.io/
Auteurs de l’étude
Sarthak Mittal
Sharath Chandra Raparthy
Irina Rish
Yoshua Bengio
Guillaume Lajoie


