



Editor's Note: Based on work presented at ICLR 2022 as Spotlight.
Attention-based systems have led to a considerable change in the Machine Learning ecosystem and have led to the era of large-scale pretrained models. These models heavily rely on Multi-Head Attention (MHA), which is built up of multiple parallel attention streams. In this work, we propose a cognitive-inspired understanding of the shortcomings and rigidities of this algorithm and, guided by these limitations, propose a novel mechanism aimed at solving some of these problems.
In the following sections, we first introduce key-value attention which forms the backbone of MHA, and view it as a search-retrieval mechanism. Through this lens, we provide an illustration of its limitations and consequently provide an alternative method called Compositional Attention, which we uncover solves some of these problems in the experiments that we consider.
Search and Retrieval
Standard key-value attention is a communicating procedure that channels information between different tokens. It combines a query with keys to obtain search, a soft scoring that indicates where to access information from. Corresponding to this search, the actual information is retrieved through the values, again in a soft manner through a convex combination.
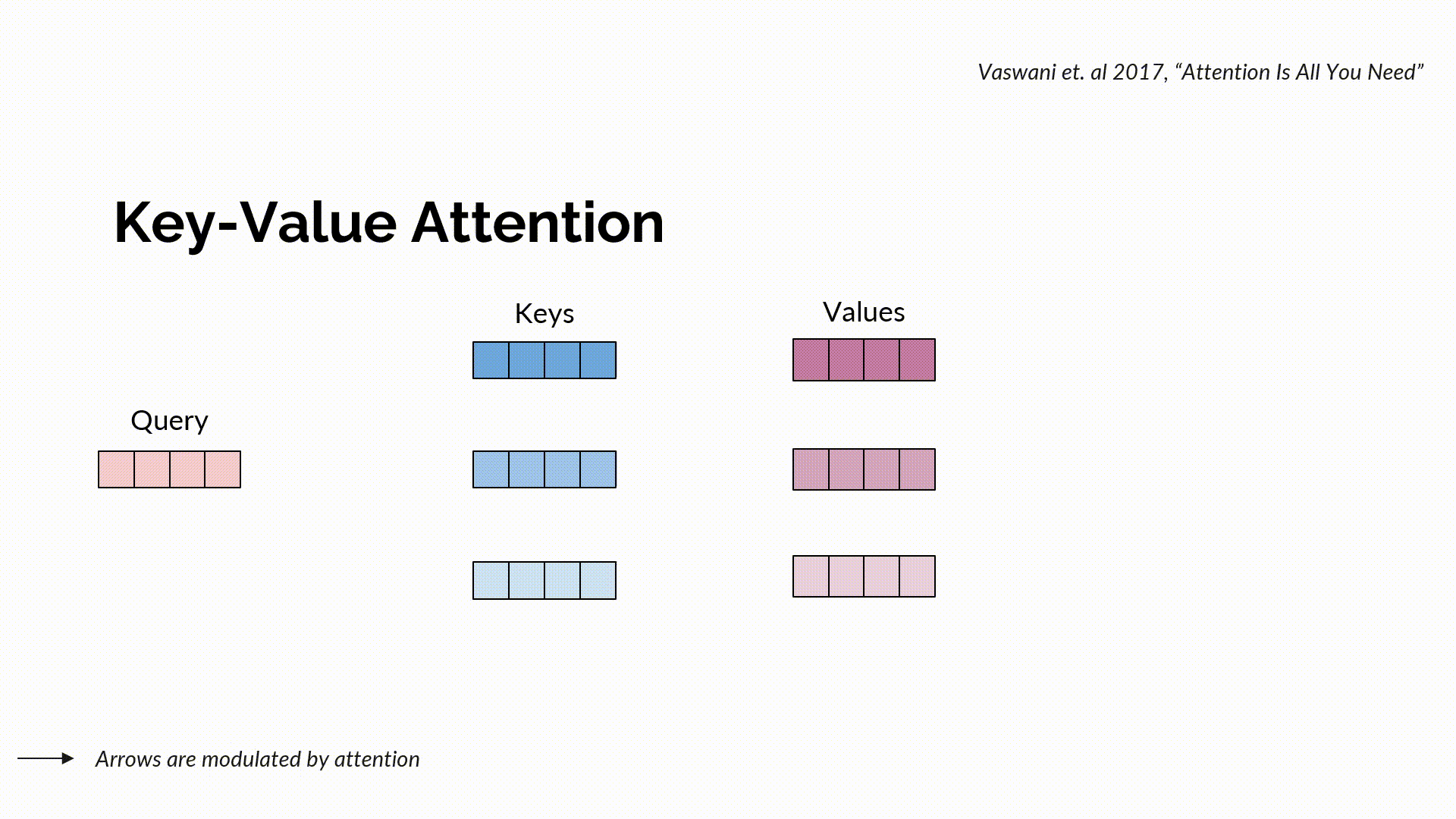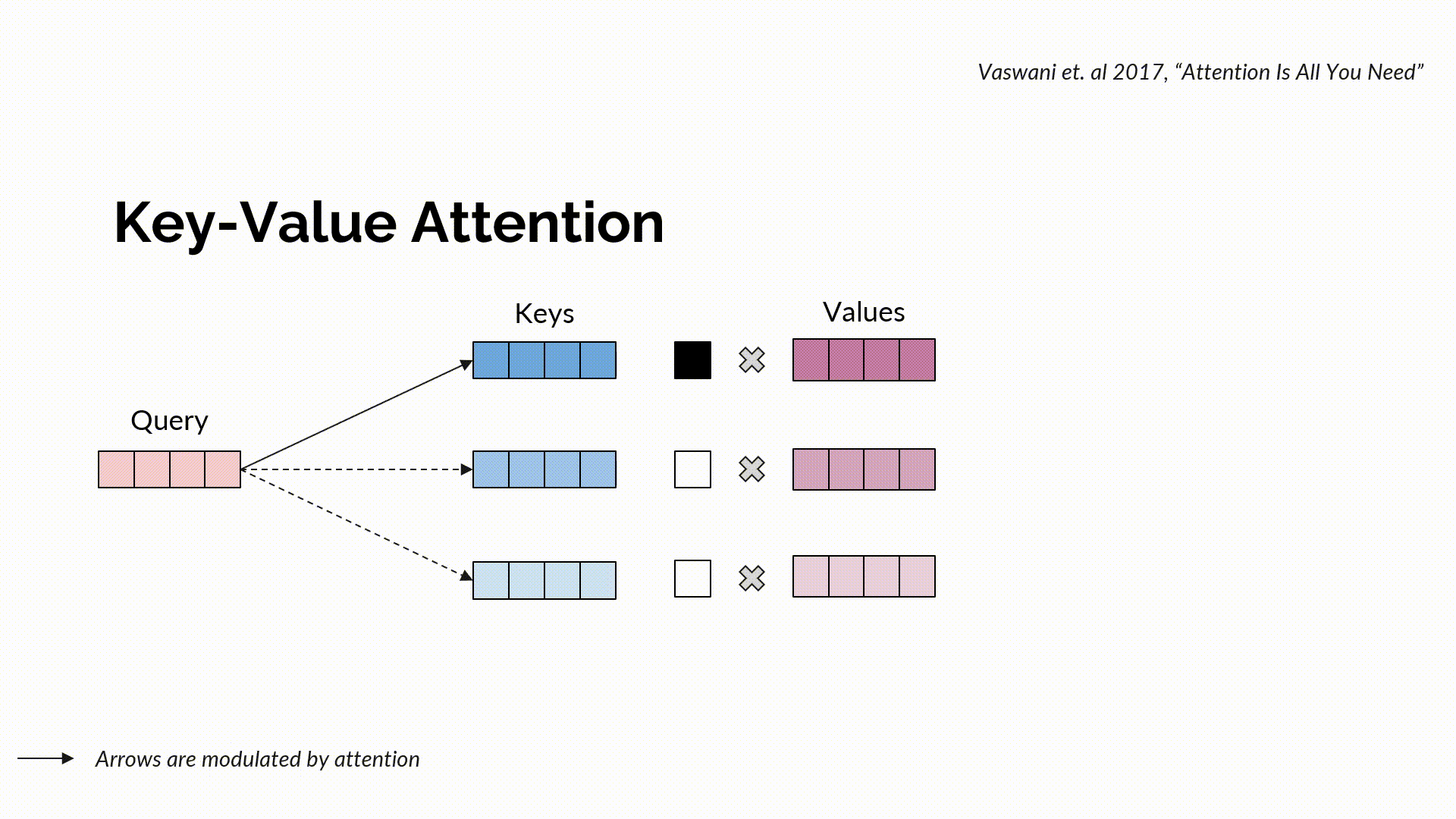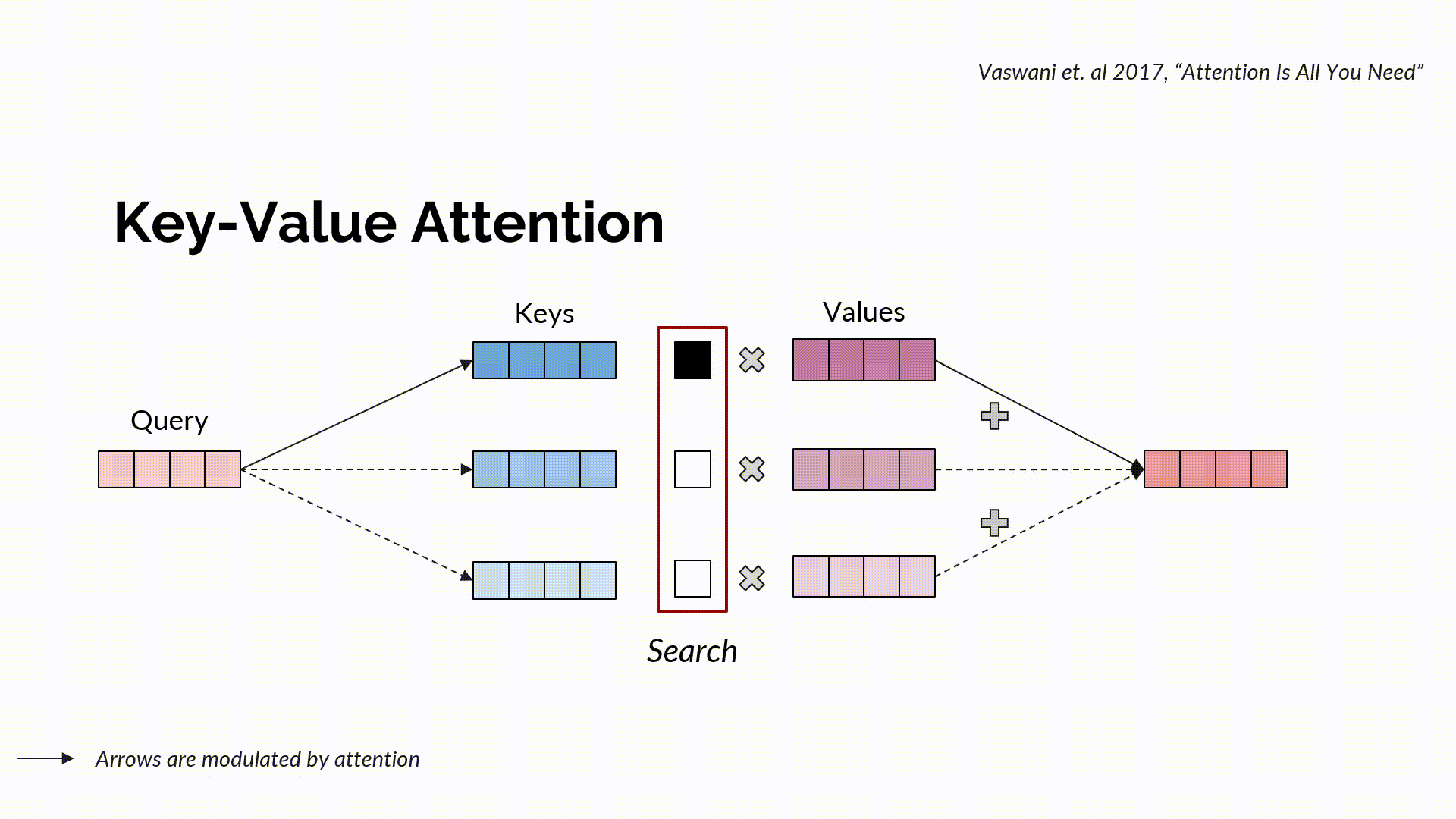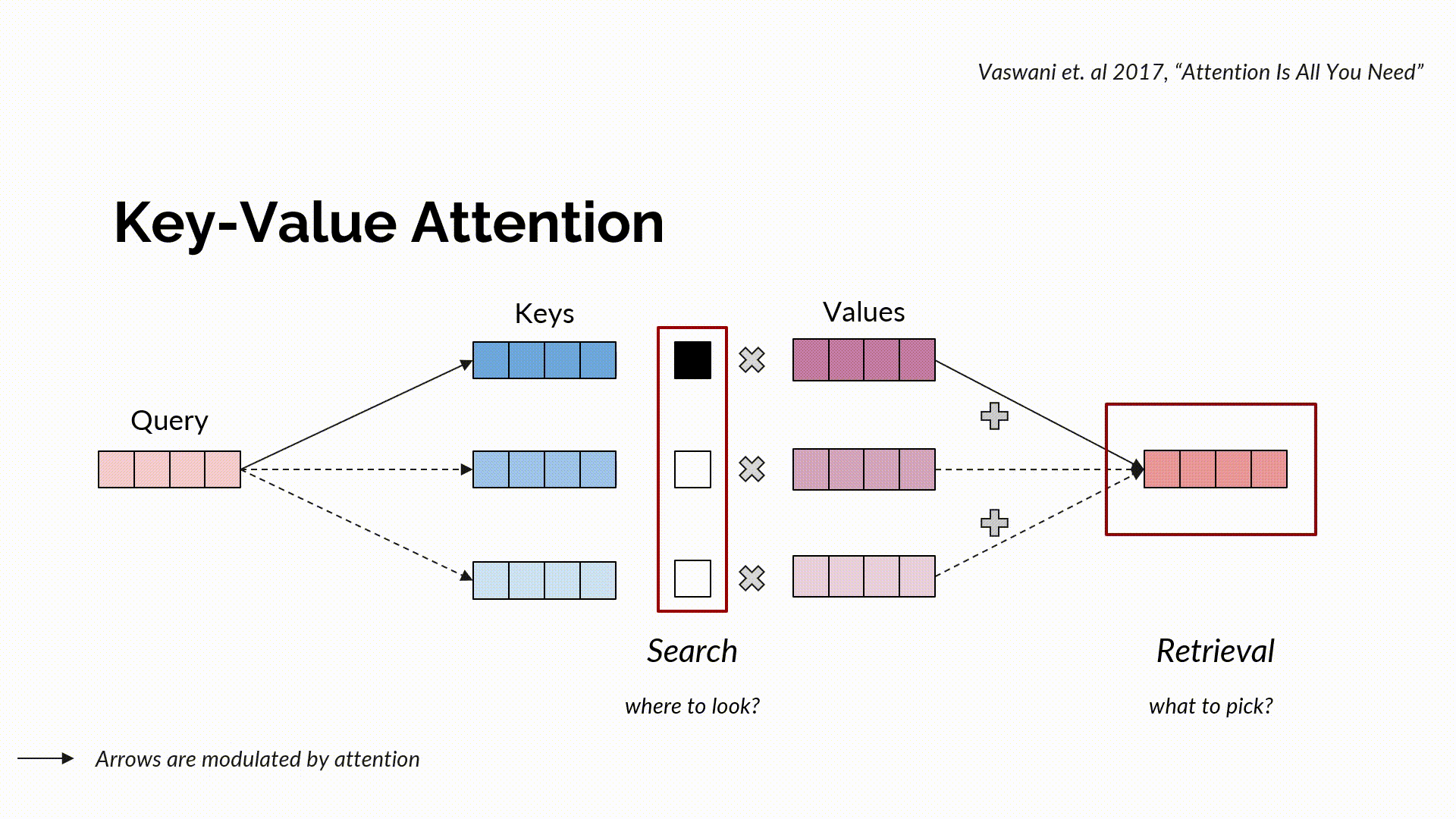
Multi-Head Attention can be seen as multiple parallel compositions of search and retrieval (each of which is called a head), where a search is defined using query-key parameterizations and retrieval using value parameterization. Intuitively, a “Search” function tells us where to look, through the similarity score of a given query with the keys. The keys that are well aligned with the queries get higher attention scores than others. Normally, Search is a function of queries and keys that calculates the scaled-dot product of the query matrix with that of the key matrix, normalized via softmax to get the attention scores. Given the output of the search function, the retrieval function intuitively tells us what to pick. More formally, it performs a weighted combination of the attention with the values and returns the required information.
Since different heads do not share any information, the search-retrieval pairings in MHA are fairly rigid. To solve this rigidity, we propose Compositional Attention which allows a plug-and-play choice of retrievals for different searches in a very flexible, dynamic, and context-dependent manner. Not only is this a more general family of attention mechanisms, but it can also allow for more search-retrieval pairings than MHA.
Illustration
Imagine an object-centric world where each object is composed of multiple features like shape, color, and location. The task aims to provide reasonable answers to the questions based on this world. This can be seen as a Visual Question Answering (VQA) task, which has gained in popularity over the past years in the machine learning community.
We aim to get an abstract high-level understanding of what the different heads of a multi-head attention mechanism should learn when exposed to different types of questions in this setup. Through the language of search and retrieval, we see that corresponding to each type of question, a certain pattern of search-retrieval is learned in the heads. In the standard multi-head attention mechanism, this leads to redundant parameters being learned.

Through the above illustration, we see that the knowledge possessed by head-3 is completely redundant as the individual parts already exist in head-1 and head-2, but the correspondence does not exist. To solve this redundancy, we propose Compositional Attention, aimed at flexible search-retrieval compositions.
Method
Since MHA systems can only model a one-to-one correspondence between search and retrieval, it would need to allocate a completely new head to answer the third question even though the individual pieces of knowledge already exist in the first two heads, thereby leading to redundancies. To remove this redundancy, we need a notion of information sharing between heads. We do this through a dynamic and context-dependent selection of retrieval for each search, thus allowing retrievals to be shared among searches.
In compositional attention, we share the retrieval parameterizations across all searches and then perform dynamic context-dependent retrievals. By doing this, we relax the static search-retrieval pairing which is typically seen in MHA and hence promote more flexibility. We achieve this in the following steps:
- We first perform \(S\) parallel searches (similar to MHA) by linearly transforming the embeddings into queries and keys and computing their dot-products.
- Once the search operations are done, we perform \(R\) possible retrievals per search by combining each search with all the sets of values obtained.
- To perform context-dependent retrievals, we use a secondary attention mechanism that combines the \(R\) different retrievals per search, in a soft manner.

Experiments
We test our proposed model on various tasks ranging from synthetic set-to-set prediction and visual question answering to image classification and language modeling settings. We generally see that Compositional Attention outperforms Multi-Head Attention across these different settings, often even with fewer retrievals and in out-of-distribution (OoD) settings.
Contextual Retrieval Task
This task consists of a set of low-dimensional objects with multiple features. Each object is required to access other objects and retrieve some features from them to solve a simple downstream task. The choice of which objects to access and what features to retrieve is provided through contextual information, in the form of one-hot signals.
This suite of tasks is defined by the number of searches (i.e., the number of objects each object has to access data from) and the number of retrievals (i.e., the number of features that can be queried from each object). Not only do we see that compositional attention outperforms multi-head attention, but we also see that it can generalize better in OoD settings where certain combinations of search-retrievals are removed from the training distribution.
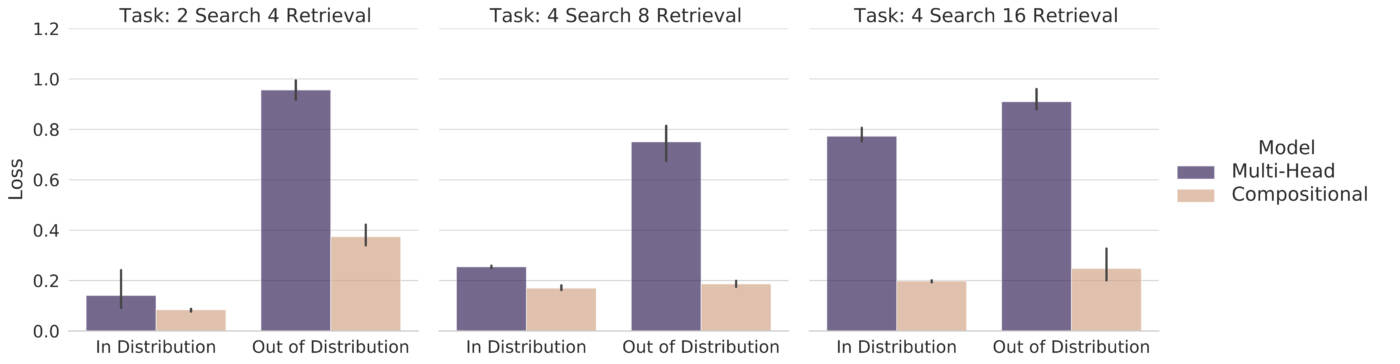
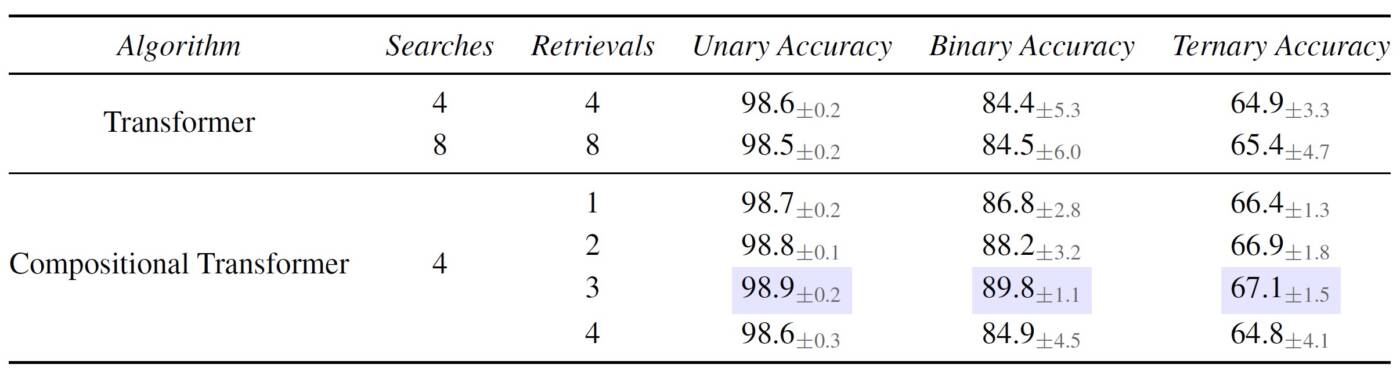
Sort-of-CLEVR Task
We experiment with a reasoning-based visual question-answering task which consists of a visual scene of multiple objects and a question pertaining to this visual context. The task consists of three types of questions: (a) Unary, based on properties of single objects, (b) Binary, based on the relationship between two objects, and (c) Ternary, based on the relationship between three objects. We generally see that compositional attention outperforms multi-head attention across all question types, and often so with a fewer number of retrievals.
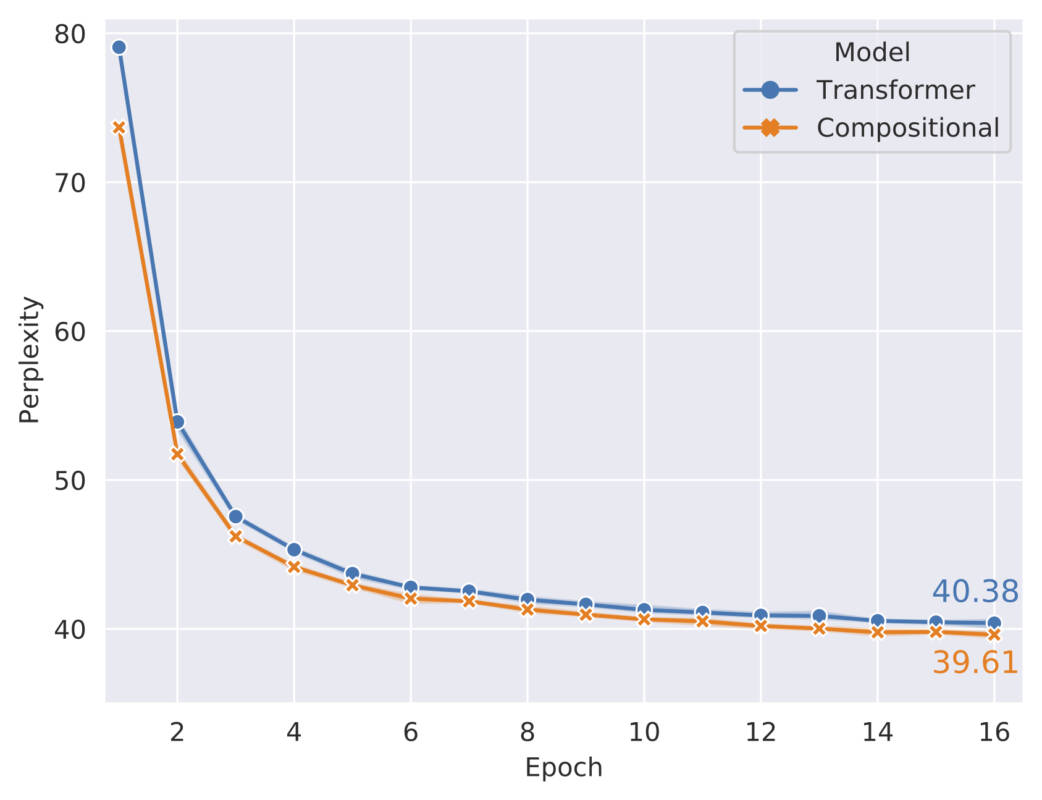
Language Modelling Task
We also perform language-modelling experiments on the WikiText-103 dataset. We see that with the same number of searches and retrievals, compositional attention surpasses multi-head attention.
For more information, please consult our arXiv paper and code.
To visit my personal website: https://sarthmit.github.io/
Paper Authors
Sarthak Mittal
Sharath Chandra Raparthy
Irina Rish
Yoshua Bengio
Guillaume Lajoie


