


Note de la rédaction : Texte publié en tant que communication à l’ICLR 2022.
Introduction
Bien qu’ils soient largement utilisés, les modèles de reconnaissance faciale comportent un biais important: le risque d’obtenir un faux positif (c.-à-d. une correspondance faciale erronée) dépend grandement d’attributs sensibles comme les origines ethniques de la personne. Aussi, ces modèles peuvent avoir une incidence négative et disproportionnée sur les membres de groupes minoritaires, surtout quand ils sont utilisés par les forces de l’ordre.
La plupart des méthodes de réduction des biais comportent plusieurs inconvénients: elles requièrent un nouvel entraînement de bout en bout, elles posent des problèmes de confidentialité qui les rendent peu pratiques, et elles diminuent souvent l’exactitude de la reconnaissance. Une autre approche réside dans les méthodes de post-traitement qui consistent à développer des classificateurs permettant d’obtenir des décisions plus équitables à partir de caractéristiques obtenues de modèles déjà entraînés, ce qui permet d’éviter les coûts associés à un nouvel entraînement. Cette approche comporte elle aussi des désavantages: des méthodes existantes comme AGENDA (Dhar et coll., 2020), PASS (Dhar et coll., 2021) et FTC (Terhörst et coll., 2020) réduisent l’exactitude, tandis que la méthode FSN (Terhörst et coll., 2021) requiert des ajustements en raison des différents taux de faux positifs.
Dans ce texte, nous présentons la méthode FairCal, ou Fairness Calibration (calibration de l’équité), une nouvelle approche de réduction des biais post-entraînement qui peut tout à la fois:
- accroître l’exactitude du modèle (et améliorer les méthodes actuelles);
- générer des probabilités calibrées en fonction de l’équité;
- réduire considérablement l’écart entre les taux de faux positifs;
- éviter le recours aux renseignements sur les attributs sensibles (race, origines ethniques, etc.);
- éviter tout nouvel entraînement, l’entraînement d’un modèle supplémentaire, ou d’autres ajustements du modèle.
En appliquant la méthode FairCal à des tâches de vérification faciale, nous obtenons d’excellents résultats qui présentent tous les avantages que nous venons d’énumérer. Pour ce faire, nous appliquons une méthode de calibration post-hoc à des pseudo-groupes formés par regroupement non supervisé.
Biais et équité des résultats de la vérification faciale
Le principe de la vérification faciale consiste à établir si deux images données forment une paire authentique ou une paire erronée. Chaque cas est illustré par les exemples suivants:




Comme l’a montré Chouldechova (2017), le développement de solutions de vérification faciale permet de remplir tout au plus deux des trois conditions suivantes:
- La calibration de l’équité: la solution est calibrée pour chaque sous-groupe, si bien que la probabilité d’une correspondance exacte est égale au niveau de confiance du modèle;
- L’égalité prédictive: les taux de faux positifs obtenus par la solution sont similaires d’un sous-groupe à l’autre;
- L’égalité des chances: les taux de faux négatifs obtenus par la solution sont similaires d’un sous-groupe à l’autre.
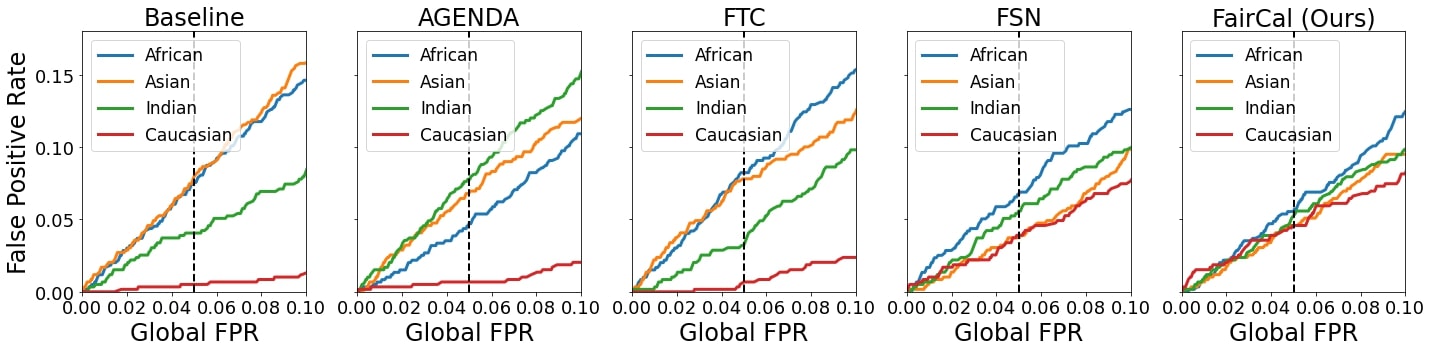
Dans le contexte particulier des activités policières, l’égalité prédictive est plus importante que l’égalité des chances, puisque les erreurs dues à un faux positif (c.-à-d. les arrestations arbitraires) peuvent entraîner de graves préjudices, surtout chez les membres de sous-groupes déjà exposés à un risque disproportionné de surveillance ou de violence policière. C’est pourquoi nous avons décidé d’omettre l’égalité des chances dans nos objectifs. Il est à noter qu’aucune méthode antérieure n’intègre la calibration de l’équité. On mesure l’égalité prédictive en comparant le taux de faux positifs de chaque sous-groupe à un taux global de faux positifs.
Méthode de base
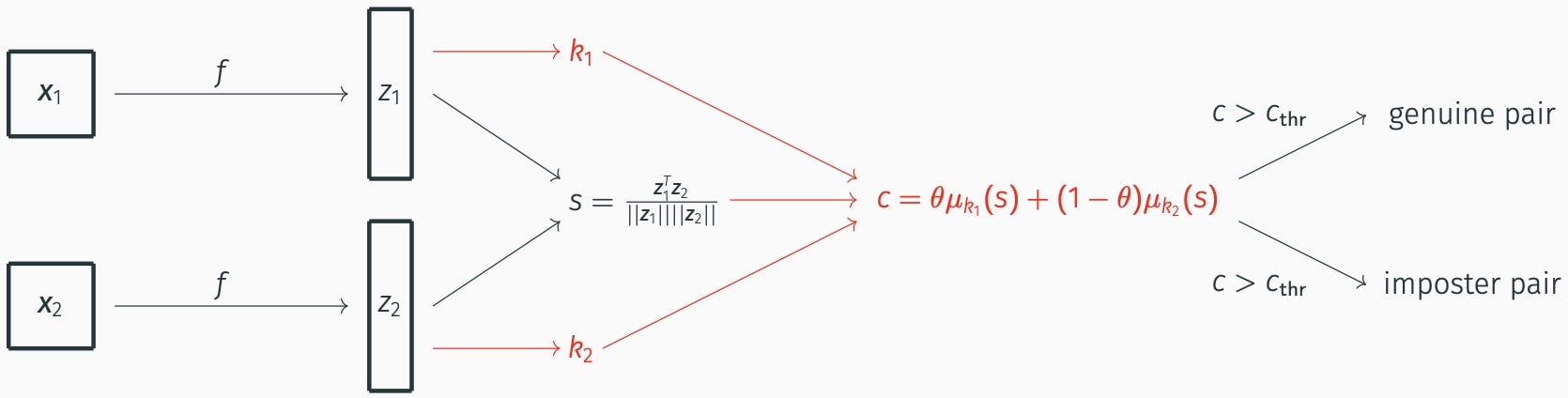
Considérant un réseau de neurones entraîné \(f\) qui encode une image \(x\) en une représentation compacte \(z=f(x)\), le classificateur de base retenu aux fins de la vérification faciale est défini de la manière suivante.
- À partir d’une paire d’images \((x_1, x_2)\): obtenir la paire de représentations \((z_1, z_2)\).
- Calculer le score de similarité cosinus pour \((x_1, x_2)\), \(s(x_1, x_2) = \frac{z_1^T z_2}{\left\Vert z_1 \right\Vert \left\Vert z_2 \right\Vert}\).
- Considérant un seuil prédéfini \(s_{thr}\), si \(s(x_1,x_2) > s_{thr}\), alors \((x_1, x_2)\) est étiqueté comme une paire authentique.
Notre méthode FairCal
La méthode que nous proposons, FairCal, repose sur deux grands principes:
- Utiliser les représentations pour définir des sous-groupes de population;
- Appliquer des méthodes de calibration post-hoc qui convertissent les scores de similarité cosinus en probabilités de paires authentiques (ou erronées).
Étape de la calibration
À partir d’un jeu de calibration formé de paires d’images:
- Appliquer l’algorithme k-means aux représentations compactes \(z\) de chaque image du jeu de calibration;
- Définir pour chaque groupe k un autre jeu de calibration formé de toutes les paires d’images comportant au moins une image appartenant au groupe \(k\);
- Pour \(k=1,\ldots, K\), appliquer une méthode de calibration post-hoc pour établir la carte de calibration \(\mu_k\), qui permet de convertir le score de similarité cosinus des paires d’images en probabilités.
Pour FairCal, nous avons retenu la calibration bêta (Kull et coll., 2017) comme méthode de calibration post-hoc, mais les essais montrent que d’autres méthodes de calibration donnent des résultats comparables.
Étape de la mise à l'essai
Une fois la calibration effectuée, les paires d’images sont mises à l’essai de la façon suivante.
- À partir d’une paire d’images \((x_1,x_2)\), nous calculons \((z_1, z_2)\) et le groupe de chaque caractéristique de l’image: \(k_1\) and \(k_2\).
- Le niveau de confiance \(x\) dans l’authenticité de la paire est défini comme suit:
\(c(x_1,x_2) = \theta \mu_{k_1} \left(s(x_1,x_2)\right) + (1-\theta) \mu_{k_2} \left(s(x_1,x_2)\right).\)
où \(\theta\) est la portion relative de la population appartenant aux deux groupes.
- Considérant un seuil prédéfini \(c_{thr}\), si \(c(x_1,x_2) > c_{thr}\), alors \((x_1,x_2)\) est étiqueté comme une paire authentique.
Résultats
Nos résultats montrent qu’en comparaison avec les méthodes de calibration post-hoc,
- FairCal possède la meilleure calibration de l’équité;
- FairCal possède la meilleure égalité prédictive (c.-à-d. des taux de faux positifs égaux);
- FairCal possède la meilleure exactitude globale;
- FairCal ne repose sur aucun attribut sensible et surpasse les méthodes qui font appel à de tels renseignements;
- FairCal ne nécessite pas de nouvel entraînement du classificateur ni aucun entraînement supplémentaire.
Références
Chouldechova, Alexandra. “Fair prediction with disparate impact: A study of bias in recidivism prediction instruments.” Big data 5.2 (2017): 153-163.
Dhar, Prithviraj, et al. “An adversarial learning algorithm for mitigating gender bias in face recognition.” arXiv preprint arXiv:2006.07845 2 (2020).
Dhar, Prithviraj, et al. “PASS: protected attribute suppression system for mitigating bias in face recognition.” Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021.
Tim Esler. “Face Recognition Using Pytorch”. GitHub repository, accessed in July 2023, https://github.com/timesler/facenet-pytorch
Kull, Meelis, Telmo Silva Filho, and Peter Flach. “Beta calibration: A well-founded and easily implemented improvement on logistic calibration for binary classifiers.” Artificial Intelligence and Statistics. PMLR, 2017.
Terhörst, Philipp, et al. “Comparison-level mitigation of ethnic bias in face recognition.” 2020 8th international workshop on biometrics and forensics (iwbf). IEEE, 2020.
Terhörst, Philipp, et al. “Post-comparison mitigation of demographic bias in face recognition using fair score normalization.” Pattern Recognition Letters 140 (2020): 332-338.
Wang, Pingyu, et al. “Deep class-skewed learning for face recognition.” Neurocomputing 363 (2019): 35-45.
Pour consulter ou citer l'article
Vous pouvez lire l’article complet ici (en anglais). Pour le citer, veuillez utiliser l’inscription bibtex suivante:
@inproceedings{salvador2022faircal,
title={FairCal: Fairness Calibration for Face Verification},
author={Tiago Salvador and Stephanie Cairns and Vikram Voleti and Noah Marshall and Adam M Oberman},
booktitle={International Conference on Learning Representations},
year={2022},
url={https://openreview.net/forum?id=nRj0NcmSuxb}
}

