



Note de la rédaction : Ce billet a été publié à l’origine le 26 avril 2022 d’après cet article publié récemment à l’occasion de l’International Conference on Machine Learning 2022.
Principales conclusions
Notre article, Apprentissage de politiques transférables par inférence de la morphologie des agents, propose une généralisation et une robustesse sans précédent pour le contrôle de grandes collections d’agents d’apprentissage par renforcement aux morphologies et aux conceptions variées.
Notre méthode ne contraint pas l’ingénieur·e à fournir des renseignements sur la morphologie et la conception de l’agent, qui sont difficiles à obtenir dans des conditions réelles. Cela rend notre méthode plus flexible et plus simple à déployer concrètement par rapport aux méthodes issues des travaux antérieurs.

Pourquoi avoir recours à l’apprentissage morphologique agnostique?
De nombreuses situations de la vie quotidienne peuvent être comparées à un apprentissage morphologique agnostique, où les compétences que nous possédons déjà facilitent le développement de nouvelles compétences. Lorsque nous apprenons à faire du vélo, par exemple, nous acquérons des compétences qui peuvent être appliquées à d’autres activités. Maintenir sonéquilibre sur un vélo est ardu au début, car il faut coordonner la direction et le mouvement des pédales pour éviter de tomber. Cependant, après avoir maîtrisé l’équilibre sur un vélo, il devient beaucoup plus facile de se tenir en équilibre sur un scooter, même si ce dernier nécessite des mouvements différents, comme pousser le sol pour se déplacer plutôt que de pédaler. Notre mémoire musculaire nous aide à développer rapidement de nouvelles compétences, parfois sans aucun entraînement.
L’apprentissage par renforcement (« reinforcement learning » ou RL), un cadre populaire pour entraîner des agents à effectuer des tâches en maximisant les résultats, implique souvent des agents de morphologies et de conceptions différentes effectuant des tâches similaires. L’efficacité de plusieurs de ces paramètres peut être optimisée par un apprentissage morphologique agnostique. Supposons que vous ayez un robot dans votre maison pour vous aider à accomplir les tâches ménagères, et que le RL soit utilisé sur ce robot. Si ce robot tombe en panne ou qu’il doit être mis à niveau, vous pourriez choisir de remplacer uniquement la pièce défectueuse, comme le bras manipulateur. Si la pièce de remplacement est trop différente de la pièce d’origine, cela peut modifier la morphologie de votre robot. En pareil cas, les agents de RL standards doivent être entraînés à nouveau à partir de zéro, ce qui est long et coûteux pour un· utilisateur·trice final·e qui n’est pas forcément spécialiste en la matière.
Ce processus ardu de réentraînement depuis le début peut être évité si votre agent utilise le RL morphologique agnostique. Des travaux antérieurs se sont penchés sur la création d’agents dont la généralisation à de nouvelles morphologies et conceptions est efficace. Ces méthodes imposent généralement des critères de conception stricts, notamment Huang et al. 2020 et Kurin et al. 2021, qui supposent que l’agent est composé de membres rigides de conception identique. Cependant, la conception de nombreux systèmes du monde réel ne correspond pas à ces critères, notamment les systèmes robotiques. L’étude de méthodes qui permettent une généralisation efficace sans restreindre la classe d’agents qu’elles peuvent modéliser avec précision pourrait concrétiser les promesses d’un RL morphologique agnostique dans le monde réel.
Notre approche
Nous faisons le premier pas vers un RL morphologique agnostique polyvalent en développant un algorithme pour l’apprentissage de politiques morphologiques agnostiques sans préciser à l’avance la conception de l’agent. Notre principale innovation consiste à représenter la conception de l’agent par une séquence de plongements vectoriels pouvant être appris puist à laisser l’algorithme déduire automatiquement la morphologie de l’agent. Nous appelons ces plongements des entités lexicales de morphologie, car ils sont inspirés des unités lexicales dans la modélisation du langage. Le traitement des entités lexicales de morphologie exige que notre politique traite des séquences d’entrée et de sortie de tailles diverses, ce qui fait du Transformeur un choix logique. Ce dernier est un réseau neuronal séquence à séquence très répandu dans le domaine de la modélisation des séquences en raison de son succès et de sa polyvalence dans la modélisation de longues séquences.

Nous présentons une architecture de politique fondée sur un modèle Transformeur pour un RL morphologique agnostique, décrite dans la figure 2. Cette architecture contrôle efficacement de grandes collections d’agents ayant des morphologies et des conceptions différentes. Notre méthode comporte moins de restrictions que les travaux antérieurs, ce qui augmente la flexibilité et la simplicité du déploiement dans la pratique. Nous évaluons ensuite les gains obtenus par notre méthode dans la généralisation à partir de zéro à des morphologies inconnues, ainsi que la robustesse en cas de panne des capteurs de l’agent.
Résultats
Nous avons observé la performance de notre méthode lors du contrôle d’agents présentant des morphologies pour lesquelles elle n’avait pas été préalablement entraînée. Nous avons mesuré le résultat moyen obtenu par notre méthode par rapport à la base de référence la plus récente dans la littérature et avons observé une amélioration de 32 % de la performance lors du test de généralisation aux morphologies pour lesquelles notre méthode n’avait pas été entraînée à l’origine. Un résultat moyen plus élevé indique que notre méthode résout ces tâches avec plus de succès que celles des travaux antérieurs. Dans les deux tâches ci-dessous, l’objectif de l’agent est d’avancer le plus rapidement possible. La plus difficile de ces tâches, « Guépard, marcheur, humanoïde sauteur », exige que notre méthode puisse contrôler avec succès 32 morphologies différentes. Nos gains de performance suggèrent que notre méthode s’adapte à des tâches plus difficiles de façon plus efficace que celles des travaux antérieurs et qu’elle n’encourt aucune pénalité malgré l’assouplissement des hypothèses sur la conception de l’agent que celles des travaux antérieurs exigeaient.

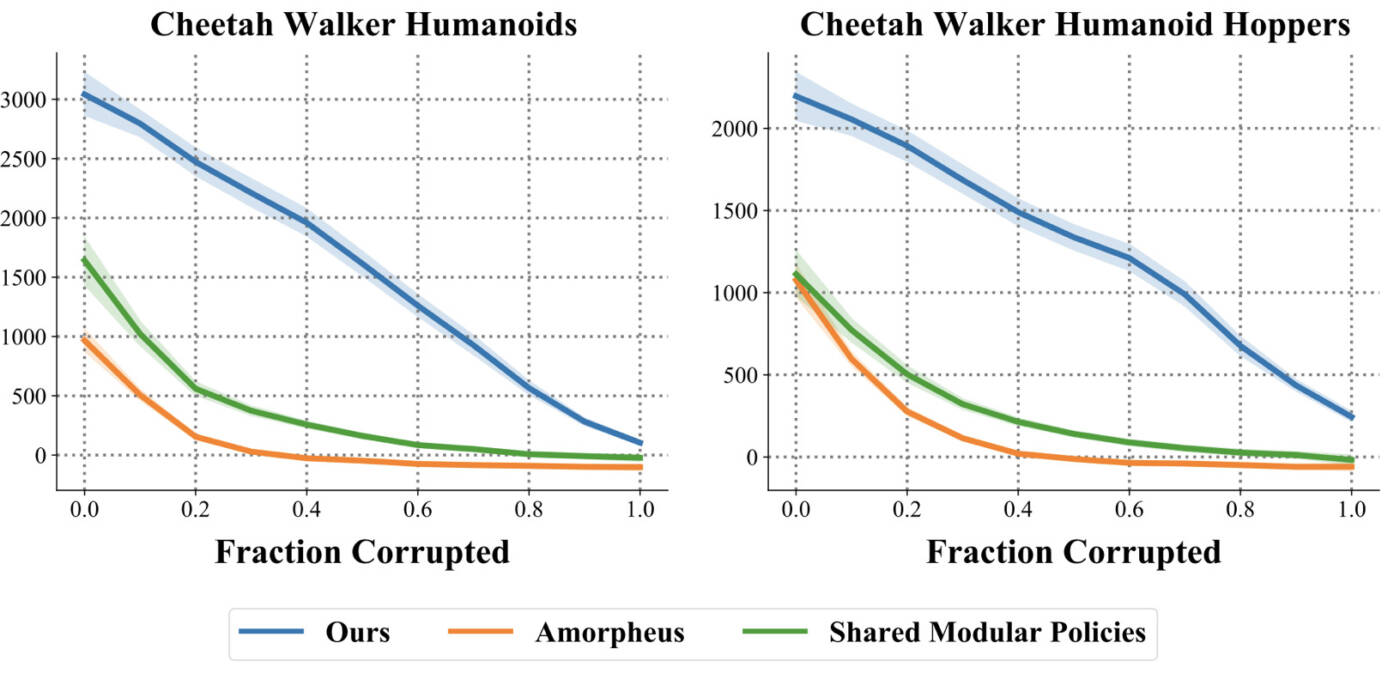
Nous avons également évalué la robustesse de notre méthode au bruit des capteurs introduit par leur rupture, un phénomène courant dans le monde réel. Nous avons systématiquement mesuré le résultat moyen obtenu par notre méthode par rapport aux bases de référence lorsqu’une fraction croissante des capteurs de l’agent tombe en panne. Nous modélisons la rupture des capteurs en remplaçant les lectures des capteurs correspondants par un bruit aléatoire. Notre méthode démontre une amélioration considérable et constante de la robustesse, illustrée par une plus grande aire sous la courbe. Nous explorons ce phénomène dans notre article et nous constatons que notre méthode détecte automatiquement les capteurs à ignorer, bien qu’elle n’ait pas été entraînée avec le bruit des capteurs ou tout autre modèle de rupture des capteurs.
Observations finales
Nous avons présenté une méthode d’apprentissage de politiques morphologiques agnostiques qui offre une généralisation et une robustesse inégalées. Cette méthode ne contraint pas l’ingénieur·e à fournir des renseignements sur la morphologie et la conception de l’agent, qui sont difficiles à obtenir dans des conditions réelles. Compte tenu des résultats prometteurs de notre méthode, nous prévoyons étudier l’entraînement morphologique agnostique du RL à partir d’observations d’images. Les images sont faciles à obtenir dans le monde réel, et apprendre à partir d’elles constitue une capacité fondamentale qui peut faciliter le RL morphologique agnostique dans les systèmes robotiques du monde réel, où la pose exacte peut être difficile à obtenir.
Informations sur la citation (BibTex)
Si vous avez trouvé cet article de blog utile, pensez à le citer comme suit :
@misc{Trabucco2022AnyMorph,
title={AnyMorph: Learning Transferable Policies By Inferring Agent Morphology},
author={Trabucco Brandon and Phielipp Mariano and Glen Berseth},
journal={International Conference on Machine Learning},
year={2022}
}


