Editor's Note: Based on work presented at ICML 2022. This blog post was originally published on April 26, 2022.
Main Findings from This Work
Our paper, Learning Transferable Policies By Inferring Agent Morphology, delivers state-of-the-art generalization and robustness for controlling large collections of reinforcement learning agents with diverse morphologies and designs.
Our method eliminates the need for an engineer to provide information about the morphology and design of the agent that is difficult to acquire in the real world, making our method more flexible and simpler to deploy in practice than prior works.

Why Use Morphology-Agnostic Learning?
Many situations encountered in our daily lives can be expressed as morphology-agnostic learning, where skills we already have make it easier to learn future skills. When first learning how to ride a bicycle, for example, we obtain skills that can be applied to other activities. Balancing while riding a bicycle is initially quite challenging because it requires the coordination of steering and pedaling to avoid falling. After mastering balance on a bicycle, however, it becomes significantly easier to balance on a scooter even though the scooter requires different movements such as pushing off the ground to move rather than pedaling. Our muscle memory helps us quickly pick up new skills, sometimes without any practice.
Reinforcement Learning (RL), a popular framework for training agents to perform tasks by maximizing returns, often involves agents with different morphologies and designs performing similar tasks. Many of these settings can benefit from morphology-agnostic learning to improve efficiency. Suppose you have a robot in your home to help with household chores, and RL is deployed on this robot. When that robot breaks down or is due for an upgrade, you might want to replace only the malfunctioning part, such as the manipulator arm. If the replacement part is different enough from the original, this may change your robot’s morphology. When this happens, standard RL agents have to be retrained from scratch, which is time-consuming and expensive for an end-user who may not be an expert.
This arduous process of retraining your agent from scratch can be avoided if your agent uses morphology-agnostic RL. Prior works have started to investigate the creation of agents that generalize effectively to new morphologies and designs. These methods typically impose strict design criteria, including Huang et al. 2020 and Kurin et al. 2021, which assume the agent is comprised of identically-designed rigid limbs. However, many real-world systems have designs that do not easily fit such criteria, including robotic systems. Investigating methods that generalize effectively without restricting the class of agent they can accurately model has the potential to unlock the promise of morphology-agnostic RL in the real world.
Our Approach
Taking the first step toward general-purpose morphology-agnostic RL, we develop an algorithm for learning morphology-agnostic policies without specifying the agent’s design in advance. Our key innovation is to represent the agent’s design by a sequence of learnable vector embeddings, and let the algorithm infer the agent’s morphology automatically. We refer to these embeddings as morphology tokens because they are inspired by word tokens in language modeling. Processing morphology tokens requires our policy to handle input and output sequences of varying sizes, which makes the Transformer a natural choice. The Transformer is a sequence-to-sequence neural network widespread in sequence-modelling due to its success and flexibility in modelling long sequences.

We introduce a Transformer-based policy architecture for morphology-agnostic RL, depicted in Figure 2, that effectively controls large collections of agents with different morphologies and designs. Our method has fewer restrictions than prior work, increasing the flexibility and simplicity of deployment in practice. Next, we evaluate the gains achieved by our method in zero-shot generalization to unseen morphologies, and robustness when sensors on the agent break.
Results
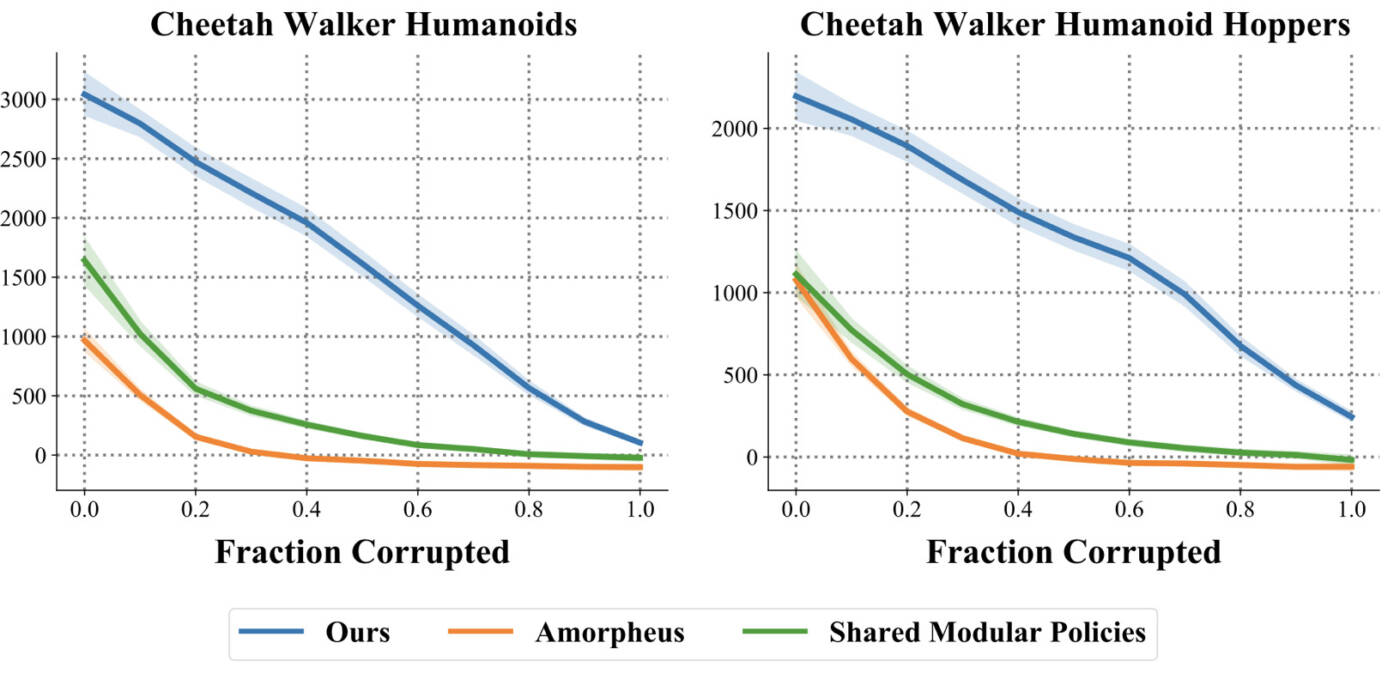
We examined the performance of our method when controlling agents with morphologies it was not originally trained to handle. We measured the average return achieved by our method compared to state-of-the-art baselines in literature and observed a 32% improvement in performance when testing generalization to morphologies our method was not originally trained for. A higher average return indicates that our method solves these tasks with more success than prior works. In the two tasks below, the agent’s goal is to run forward as quickly as possible. The harder of these tasks, “Cheetah Walker Humanoid Hoppers,” requires our method to successfully control 32 different morphologies. Our performance gains suggest our method scales to harder tasks more effectively than prior works and incurs no penalty despite relaxing assumptions about the agent’s design that prior works require.

We also evaluated our method’s robustness to sensor noise introduced by sensor breakage, a common occurrence in the real world. We systematically measured the average return attained by our method against baselines when an increasing fraction of the agent’s sensors break. We model sensor breakage by replacing corresponding sensor readings with random noise. Our method demonstrates a consistent significant improvement in robustness, illustrated by higher area-under-the-curve. We explore this phenomenon in our paper, finding that our method automatically discovers which sensors to ignore, despite not being trained with sensor noise, or any other model of sensor breakage.
Concluding Remarks
We introduced a method for training morphology-agnostic policies that delivers state-of-the-art generalization and robustness, and eliminates the need for an engineer to provide information about the morphology and design of the agent that is difficult to acquire in the real world. Given the promising results our method demonstrates, we plan to investigate training morphology-agnostic RL with image observations next. Images are straightforward to obtain in the real world, and learning from images is a crucial ability that can facilitate morphology-agnostic RL in real-world robotic systems, where exact poses can be hard to acquire.
Citation Info (BibTex)
If you found this blog post useful, please consider citing it as:
@misc{Trabucco2022AnyMorph,
title={AnyMorph: Learning Transferable Policies By Inferring Agent Morphology},
author={Trabucco Brandon and Phielipp Mariano and Glen Berseth},
journal={International Conference on Machine Learning},
year={2022}
}