


Mila et Relation Therapeutics ont engagé une collaboration fructueuse grâce au projet RECOVER, financé en partie par la Fondation Bill et Melinda Gates. Lancé en 2020, le projet initial visait à découvrir un traitement contre la COVID-19 en identifiant des associations de médicaments repositionnés qui, ensemble, peuvent limiter la pénétration du virus dans les cellules humaines et ralentir sa réplication. Pour découvrir rapidement un nouveau traitement, nous avons proposé d’explorer efficacement l’espace des associations médicamenteuses à l’aide d’un pipeline d’apprentissage actif et d’optimisation séquentielle de modèles. Afin de démontrer la faisabilité de notre approche, nous l’avons appliquée à la découverte de nouvelles associations médicamenteuses efficaces contre le cancer, en raison de la disponibilité de données publiques dans ce domaine.
La combinaison des expertises en apprentissage automatique et en conception expérimentale a été essentielle pour élaborer et mettre en œuvre notre nouvelle méthodologie. Le pipeline d’apprentissage automatique prédit la réponse des cellules cancéreuses à des associations de médicaments et propose des expériences à effectuer en laboratoire dans l’objectif de découvrir de nouvelles associations qui présentent des synergies entre les différents médicaments. Une telle approche constitue un outil puissant qui pourrait permettre de réagir rapidement lors de futures crises de santé publique.
Explorer l’espace des associations médicamenteuses
Les associations de médicaments constituent une stratégie thérapeutique de choix pour traiter les maladies soumises à une dynamique évolutive, en particulier les cancers et les maladies infectieuses [1, 2]. D’un point de vue conceptuel, les tumeurs et les virus peuvent évoluer ou muter au fil du temps et développer une résistance à un médicament unique [3]. Les multithérapies pourraient jouer un rôle important dans l’issue de la maladie en augmentant l’efficacité des médicaments et en réduisant leur toxicité, tout en ciblant simultanément plusieurs mécanismes biologiques [4]. Cela réduit le risque de mutation par un agent pathogène qui serait simultanément résistant à tous les médicaments présents dans l’association. Cependant, l’espace des associations médicamenteuses est encore largement inexploré en raison du grand nombre d’expériences possibles, qui est une fonction exponentielle du nombre de médicaments pris en compte. Ceci limite la capacité des ensembles de données actuels à couvrir toutes les régions de cet espace et, en fin de compte, impacte la qualité des prédictions reposant sur l’apprentissage automatique. Une solution rentable est d’avoir recours à l’optimisation séquentielle de modèles (OSM), qui consiste à réaliser à la fois des expériences informatives (« exploration ») et des expériences s’appuyant sur une hypothèse prometteuse (« exploitation ») [5], le compromis classique de l’apprentissage par renforcement. La mise en œuvre d’une telle approche pourrait accélérer la découverte d’associations prometteuses pour un ensemble donné de médicaments tout en nécessitant beaucoup moins d’expérimentation.
Dans le cadre de ce travail, nous nous concentrons sur les indices de synergie entre paires de médicaments, et plus précisément sur l’indice de Bliss, qui compare l’effet conjugué des deux médicaments au résultat attendu étant donné l’effet individuel de chaque médicament. Notre objectif est de découvrir des associations médicamenteuses hautement synergiques capables d’activer le programme de mort cellulaire dans des cellules cancéreuses humaines cultivées in vitro. Bien que l’OSM ait déjà été appliquée aux levures [6] et aux bactéries [7], le fait de se concentrer sur les cellules humaines présentait des défis techniques majeurs, comme la variabilité d’un lot d’expériences à l’autre.
RECOVER : une plateforme d’optimisation séquentielle de modèles
Notre outil d’OSM (voir la figure 1) génère des recommandations d’associations médicamenteuses qui sont testées in vitro à intervalles réguliers. À chaque étape, notre modèle est entraîné sur toutes les données déjà acquises. Une fonction d’acquisition prend en entrée les prédictions et les incertitudes du modèle et calcule un score favorisant les associations candidates qui devraient bien fonctionner et pour lesquelles une expérience serait instructive (le modèle est incertain du résultat). Les associations présentant les scores les plus élevés, selon la fonction d’acquisition, sont ensuite envoyées en tant que recommandations pour être testées in vitro. Les résultats des expériences sont ensuite ajoutés aux données d’entraînement pour la prochaine série d’expériences, et tout le processus se répète.
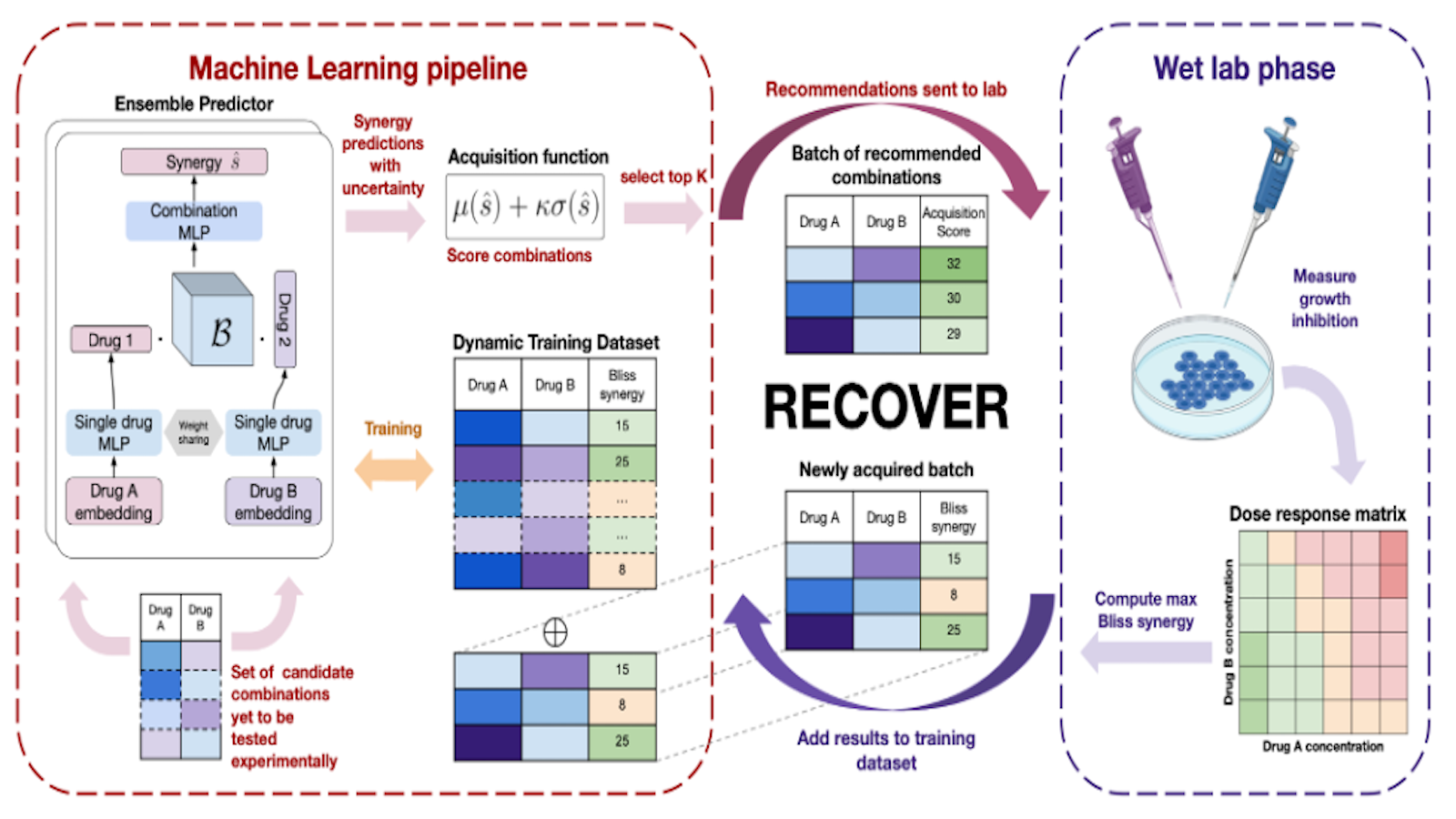
Bien que nous ayons d’abord travaillé sur des modèles avancés reposant sur des bases de données d’interactions protéiques et des signatures transcriptionnelles, nous avons finalement privilégié un modèle plus simple offrant une performance très semblable en vue de de faciliter l’adoption du pipeline par d’autres praticien(ne)s. Les paires de vecteurs d’attributs des médicaments sont présentées à un réseau de neurones profond, qui sert à prédire l’indice de synergie. Ces vecteurs d’attributs comprennent des empreintes de structure moléculaires et des encodages one-hot (avec une entrée à 1 et les autres à 0) des médicaments.
La nécessité d’une approche séquentielle est confirmée par une évaluation in silico
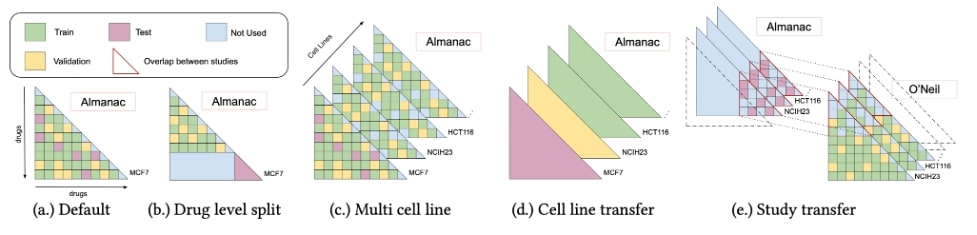
Notre modèle a été évalué sur différentes tâches, présentées dans la figure 2, afin d’évaluer ses capacités de généralisation. Bien que ses performances puissent sembler modestes, nous avons montré qu’elles sont raisonnablement proches du maximum hypothétique compte tenu de la quantité de bruit expérimental. Comme le montre le tableau 1, nous avons constaté une baisse considérable de la performance lorsque nous avons essayé de généraliser aux associations de nouveaux médicaments. Cependant, la performance est toujours supérieure à celle d’une sélection aléatoire. Deuxièmement, nous avons remarqué que la prise en compte de plusieurs populations distinctes de cellules cancéreuses (appelées lignées cellulaires) améliore les performances sur les cellules cancéreuses d’intérêt, en termes de R2. Enfin, nous avons remarqué que le modèle généralise mal à un nouveau cadre expérimental.
Concernant les expériences in vitro prospectives, cette analyse suggère qu’une approche séquentielle est nécessaire afin d’adapter notre modèle à un nouveau laboratoire, puis à de nouveaux composés chimiques. Il est ainsi possible de trouver une bonne association beaucoup plus rapidement que si nous avions suivi la pratique traditionnelle de l’apprentissage automatique consistant à collecter des données, à entraîner un modèle, puis à utiliser le modèle entraîné pour filtrer un grand nombre d’associations candidates.

Les tests in silico de RECOVER permettent de prédire et de redécouvrir rapidement des associations médicamenteuses synergiques
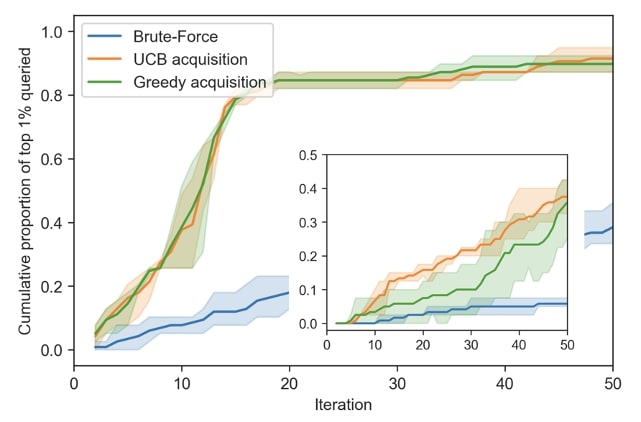
Nos expériences in silico ont tenté de reproduire aussi fidèlement que possible les paramètres des expériences in vitro. Nous comparons plusieurs stratégies de recherche en fonction de la vitesse à laquelle elles découvrent les associations qui sont parmi le 1% les plus synergiques au sein de notre ensemble de données. La proportion d’associations qui ont déjà été découvertes parmi le premier percentile est calculée à chaque cycle expérimental synthétique (ou itération). Comme le montre la figure 3, les fonctions d’acquisition de type glouton et de limite de confiance supérieure (Upper Confidence Bound abrégé UCB), deux stratégies s’appuyant sur les prédictions du modèle, affichent des performances comparables et qui surpassent de loin celles d’une recherche aléatoire.
Dans d’autres expériences in silico (ne correspondant pas exactement à notre cadre in vitro), la fonction d’acquisition UCB surpasse celle de type glouton. Voir la figure 5 (encadré). Cela démontre que, dans certains cas, la prise en compte de l’incertitude pour guider les expériences peut augmenter la performance du pipeline par rapport à une stratégie d’acquisition élémentaire de type glouton.
L’utilisation prospective de RECOVER permet de découvrir et de redécouvrir de nouvelles associations synergiques
Après notre étude in silico, nous avons testé RECOVER de manière prospective avec le laboratoire Lairson au Scripps Research Institute. Nous avons effectué trois cycles d’expériences en laboratoire guidées par RECOVER et avons observé que les performances s’amélioraient à chaque itération. Alors que les deux premiers cycles étaient axés sur le calibrage du modèle et veillaient à s’assurer qu’une proportion raisonnable de l’espace des associations était observée, le dernier cycle de recommandations reflétait un cas d’utilisation réel presque entièrement automatisé.
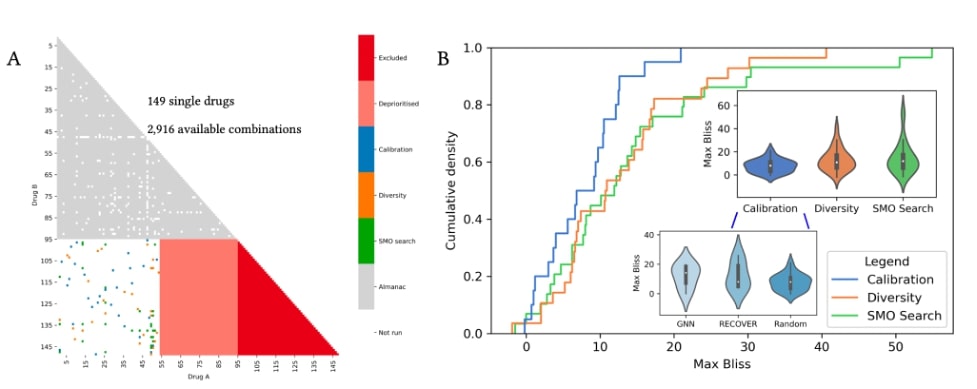
L’espace de recherche comprenait 2 916 associations médicamenteuses (voir figure 4A). À chaque itération, les synergies de 30 associations ont été évaluées. Dans la figure 4B, nous reportons la fonction de répartition pour chaque cycle expérimental. Nous remarquons que la distribution commence à développer une queue plus lourde dans les synergies positives. Cette queue lourde émergente apparaît significative lorsqu’on compare la distribution du dernier cycle expérimental à la distribution dans les données publiques (test de Kolmogorov-Smirnov, p < 0,025). Enfin, la plus haute synergie de Bliss observée augmente à chaque itération.
Conclusion
Nous avons présenté le pipeline d’optimisation séquentielle de modèles RECOVER pour la sélection d’associations médicamenteuses. Nous présentons une méthodologie générale, qui consiste à analyser minutieusement certaines propriétés du pipeline d’apprentissage automatique – comme ses capacités de généralisation hors distribution – pour nous aider à concevoir certains aspects des expériences in vitro, et en définitive assurer une interaction fluide et réussie entre le pipeline d’apprentissage automatique et le laboratoire.
Après seulement trois cycles d’expérimentations in vitro guidés par l’apprentissage automatique, nous avons constaté que l’ensemble des associations recommandées par notre modèle était enrichi en associations hautement synergiques. De façon remarquable, nous avons redécouvert une association synergique médicamenteuse dont il a été confirmé par la suite qu’elle était à l’étude dans le cadre d’essais cliniques [8].
Ce billet de blogue s’appuie sur notre récente prépublication (en anglais): https://arxiv.org/pdf/2202.04202.pdf
Code: https://github.com/RECOVERcoalition/Recover
Remerciements
Cette recherche est financée en partie par la Fondation Bill et Melinda Gates. Les résultats et les conclusions qu’il contient sont ceux des auteurs et ne reflètent pas nécessairement les positions ou les politiques de la Fondation Bill et Melinda Gates. Les auteurs tiennent également à remercier Isabelle Lacroix pour son soutien.
Auteur·trice·s de l’article
Paul Bertin, Mila
Jarrid Rector-Brooks, Mila
Deepak Sharma, Mila
Thomas Gaudelet, Relation Therapeutics
Andrew Anighoro, Relation Therapeutics
Torsten Gross, Relation Therapeutics
Francisco Martínez-Peña, Department of Chemistry, The Scripps Research Institute
Eileen Tang, Department de Chemistry, The Scripps Research Institute
Suraj M S, Relation Therapeutics
Christian Regep, Relation Therapeutics
Jeremy Hayter, Relation Therapeutics
Maksym Korablyov, Mila
Nicholas Valiante, Glyde Bio, Inc.
Almer van der Sloot, Institute for Research in Immunology and Cancer (IRIC)
Mike Tyers, Institute for Research in Immunology and Cancer (IRIC)
Charles Roberts, Relation Therapeutics
Michael Bronstein, Department of Computer Science, Université d’Oxford, Twitter
Luke Lairson, Department of Chemistry, The Scripps Research Institute
Jake Taylor-King, Relation Therapeutics
Yoshua Bengio, Mila
Références
[1] Adrian Schmid, Aline Wolfensberger, Johannes Nemeth, Peter W Schreiber, Hugo Sax, and Stefan P Kuster. Monotherapy versus combination therapy for multidrug-resistant gram-negative infections: Systematic review and meta-analysis. Scientific reports, 9(1):1–11, 2019.
[2] Reza Bayat Mokhtari,Tina S Homayouni, Narges Baluch, Evgeniya Morgatskaya, Sushil Kumar, Bikul Das, and Herman Yeger. Combination therapy in combating cancer. Oncotarget, 8(23):38022, 2017.
[3] João Delou, Alana SO Souza, Leonel Souza, and Helena L Borges. Highlights in resistance mechanism pathways for combination therapy. Cells, 8(9):1013, 2019.
[4] Bissan Al-Lazikani, Udai Banerji, and Paul Workman. Combinatorial drug therapy for cancer in the post-genomic era. Nature Biotechnology, 30(7):679-692, July 2012.
[5] Yuriy Sverchkov and Mark Craven. A review of active learning approaches to experimental design for uncovering biological networks. PLoS computational biology, 13(6):e1005466, 2017.
[6] Ross D. King, Kenneth E. Whelan, Ffion M. Jones, Philip G. K. Reiser, Christopher H. Bryant, Stephen H. Muggleton, Douglas B. Kell, and Stephen G. Oliver. Functional genomic hypothesis generation and experimentation by a robot scientist. Nature, 427(6971):247–252, Jan 2004.
[7] Pablo Carbonell, Adrian J. Jervis, Christopher J. Robinson, Cunyu Yan, Mark Dunstan, Neil Swainston, Maria Vinaixa, Katherine A. Hollywood, Andrew Currin, Nicholas J. W. Rattray, Sandra Taylor, Reynard Spiess, Rehana Sung, Alan R. Williams, Donal Fellows, Natalie J. Stanford, Paul Mulherin, Rosalind Le Feuvre, Perdita Barran, Royston Goodacre, Nicholas J. Turner, Carole Goble, George Guoqiang Chen, Douglas B. Kell, Jason Micklefield, Rainer Breitling, Eriko Takano, Jean-Loup Faulon, and Nigel S. Scrutton. An automated design-build-test-learn pipeline for enhanced microbial production of fine chemicals. Communications Biology, 1(1):66, Dec 2018.
[8] Hiral A Shah, James H Fischer, Neeta K Venepalli, Oana C Danciu, Sonia Christian, Meredith J Russell, Li C Liu, James P Zacny, and Arkadiusz Z Dudek. Phase i study of aurora a kinase inhibitor alisertib (mln8237) in combination with selective vegfr inhibitor pazopanib for therapy of advanced solid tumors. American journal of clinical oncology, 42(5):413–420, 2019.


