



Lorsqu’il aborde une nouvelle tâche, l’humain s’appuie sur le bon sens qu’il a acquis au cours de sa vie. Si on lui présente une clé, il sait qu’elle peut être utilisée pour ouvrir une porte; s’il se retrouve devant une porte, il sait que de nouvelles informations peuvent être trouvées derrière. Nous savons naturellement ce qui est bon ou intéressant dans une nouvelle situation avant même d’avoir interagi directement avec cette situation. Comment doter un agent d’intelligence artificielle d’une capacité similaire? Dans notre nouvelle recherche, nous montrons qu’il est possible d’y parvenir en permettant aux agents d’apprendre à partir de la rétroaction de l’intelligence artificielle. Dans ce billet de blogue, nous allons expliquer pourquoi il peut être important de tirer parti de ce bon sens, et nous allons décrire une méthode pour entraîner un agent à l’aide de la rétroaction d’un grand modèle de langage. Nous présenterons ensuite notre évaluation de cette méthode sur le jeu vidéo NetHack.
Les grands modèles de langage comme source de bon sens
En écrivant sur le monde qu’ils observent ou imaginent, les êtres humains ont cristallisé une quantité importante de bon sens sous forme de texte écrit sur l’internet. Les grands modèles de langage (LLM) entraînés sur des ensembles de données à l’échelle de l’internet rendent ces connaissances facilement accessibles, mais cela n’est pas suffisant en soi pour les exploiter dans le cadre d’une prise de décision séquentielle.
Les LLM opèrent dans un espace linguistique de haut niveau, mais la prise de décision doit souvent se faire à un niveau d’abstraction différent : un agent interagissant avec l’environnement a besoin de voir le monde et d’exécuter des actions précises par l’intermédiaire de ses actionneurs. Pour tirer parti du bon sens d’un LLM, il faut combler le fossé entre ses connaissances de haut niveau et la réalité sensorimotrice de bas niveau dans laquelle l’agent opère.
Heureusement, évaluer est souvent plus facile que générer : au lieu de comprendre tous les détails que contiennent les observations ou les actions d’un environnement en particulier, un LLM pourrait à la place guider un agent agissant dans ce domaine en disant simplement si un événement est perçu comme bon ou mauvais, sans avoir besoin d’une interface linguistique directe avec le monde. C’est le principe de base de notre méthode.
NetHack, un banc d’essai exigeant du bon sens
NetHack est un jeu vidéo de type “rogue”, dans lequel un joueur doit parcourir les différents niveaux d’un donjon, vaincre des monstres, rassembler des objets et surmonter d’importantes difficultés. Pour jouer efficacement à NetHack, un joueur doit explorer un donjon complexe généré de manière aléatoire en planifiant des milliers de tours et en collectant des informations cruciales en cours de route. Étant donné que le bon sens humain peut être très utile dans la collecte d’informations, pour l’exploration et lors des interactions fructueuses avec les entités que l’on peut trouver dans le jeu, NetHack offre une plateforme idéale pour démontrer l’utilité des connaissances de bon sens provenant d’un LLM. Traiter un problème aussi difficile sans faire appel au bon sens serait extrêmement compliqué, puisqu’un agent doit tout apprendre à partir de zéro en utilisant un signal de récompense (par exemple, le score du jeu) provenant de l’environnement.
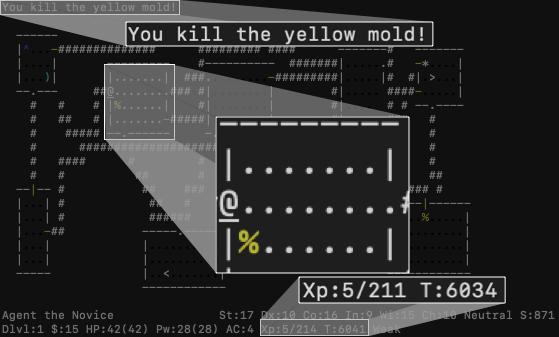
NetHack est un domaine naturel pour vérifier si la rétroaction des LLM sur les événements se produisant dans l’environnement est suffisante pour créer un pont entre les niveaux d’abstraction du LLM et de l’agent : il présente des descriptions (appelées messages) qui présentent des événements positifs, négatifs ou neutres dans le jeu, apparaissant par exemple lorsqu’un monstre attaque ou que l’agent atteint un niveau de donjon plus avancé.
Motif : Motivation intrinsèque issue de la rétroaction d’une intelligence artificielle
Nous proposons Motif, un algorithme qui dote un agent de bon sens en extrayant une fonction de récompense (un signal scalaire indiquant la désirabilité d’une certaine situation dans le jeu) d’un LLM et en la donnant à l’agent qui interagit avec l’environnement. Motif exploite des idées récentes sur l’apprentissage par renforcement à partir de la rétroaction de l’IA, en demandant à un LLM de fournir des préférences sur les descriptions de différents événements, puis en distillant ces préférences dans une fonction de récompense.
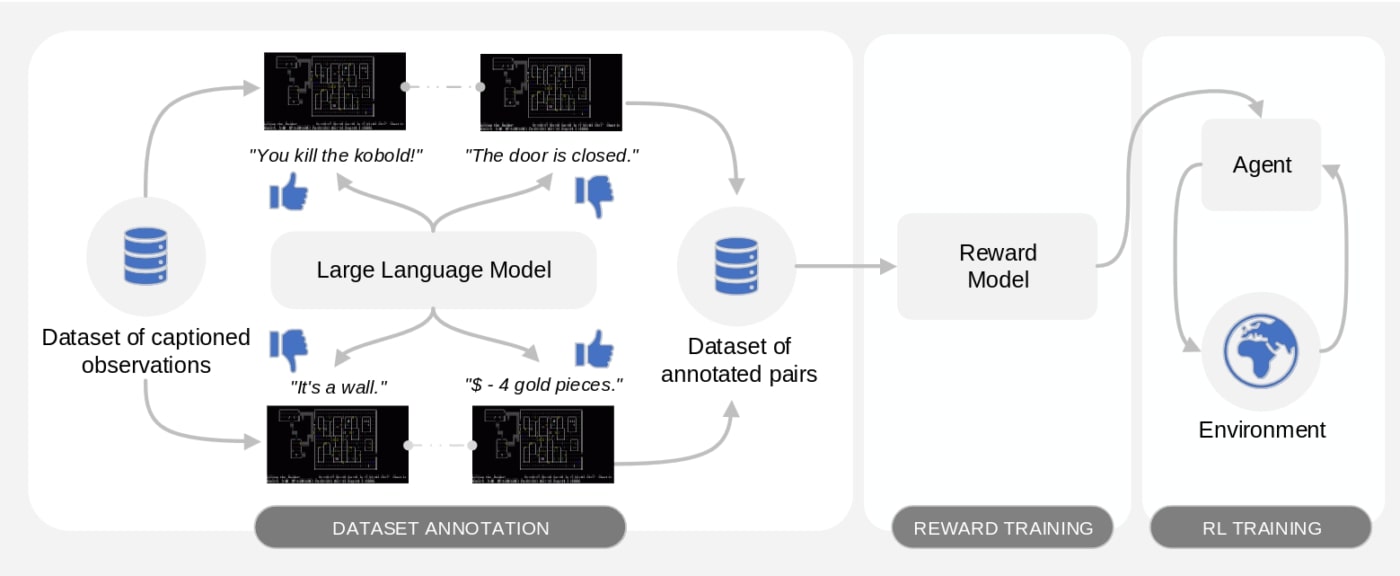
Notre méthode comporte trois phases. Dans la première phase, nous échantillonnons une collection d’observations contenant des descriptions d’événements (dans notre cas, des messages de jeu dans NetHack), et nous classifions des paires de descriptions en fonction des préférences d’un LLM, ce qui nous indique les événements les plus favorables. Dans la deuxième phase, l’ensemble de données résultant des paires annotées est utilisé pour apprendre un modèle de récompense à partir des préférences du LLM. Dans la troisième phase, cette fonction de récompense est donnée à un agent interagissant avec l’environnement et utilisée pour l’entraîner grâce à une approche d’apprentissage par renforcement, possiblement avec les récompenses venant de l’environnement lui-même.

Nous demandons à un modèle Llama 2 de donner des préférences sur des paires aléatoires de descriptions, en utilisant une requête inspirée de la chaîne de pensée.
Performance de Motif
Nous testons la performance de Motif sur un ensemble de tâches de l’environnement d’apprentissage NetHack. Nous testons le cas où l’agent utilise uniquement la récompense issue des préférences du LLM (appelée intrinsèque) et la combinaison de celle-ci avec celle de l’environnement (appelée extrinsèque).
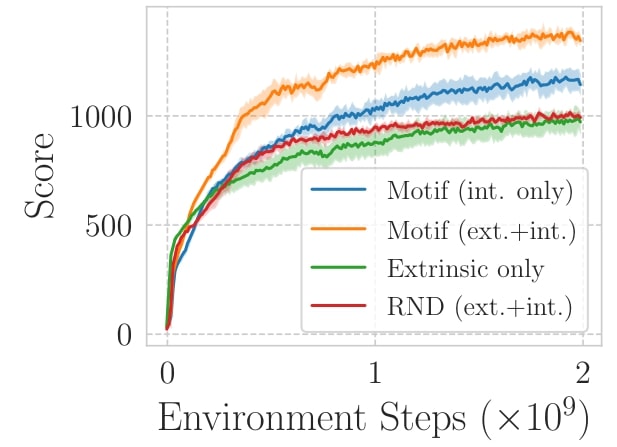
Maximiser le score de NetHack est l’une des tâches les plus naturelles auxquelles il est possible d’être confronté. Le jeu attribue un score lorsque certains événements se produisent, comme le passage au niveau suivant ou la mort d’un monstre. Dans cette tâche, nous avons montré que les agents formés exclusivement avec la récompense intrinsèque de Motif surpassent étonnamment les agents entraînés à l’aide du score lui-même, et les agents sont encore plus performants lorsqu’ils sont entraînés avec une combinaison des deux fonctions de récompense.
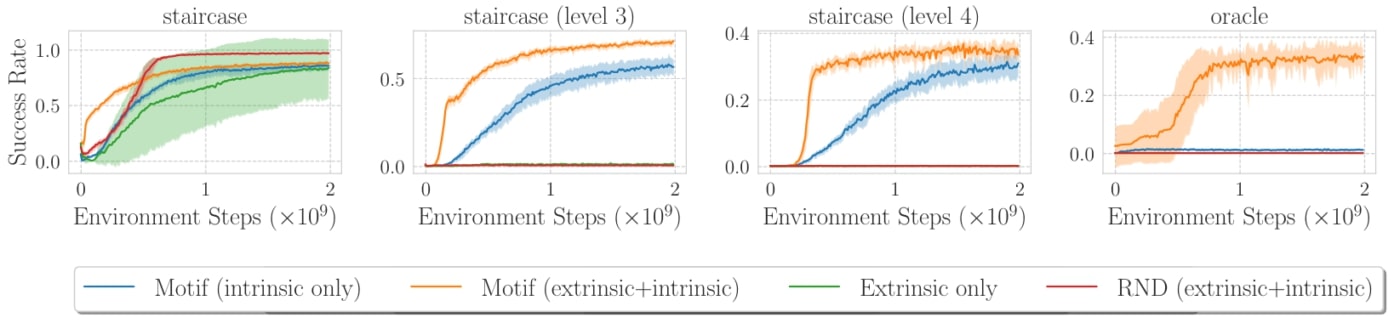
La maximisation du score est une tâche relativement dense en récompense, puisqu’un certain nombre d’événements apportent un score non nul dans le jeu. Nous avons montré que Motif surpasse également les méthodes existantes dans un contexte de récompense clairsemée, dans lequel une récompense n’est accordée que lorsqu’un certain niveau de donjon ou un certain personnage est atteint. Motif obtient de bonnes performances dans la tâche oracle, dans laquelle aucune autre approche n’a été capable d’obtenir des progrès significatifs sans imiter les joueurs experts.
Alignement des agents formés avec Motif
Pour comprendre l’origine des gains en performance de Motif, nous avons analysé le comportement des agents entraînés avec Motif et la fonction de récompense extrinsèque.
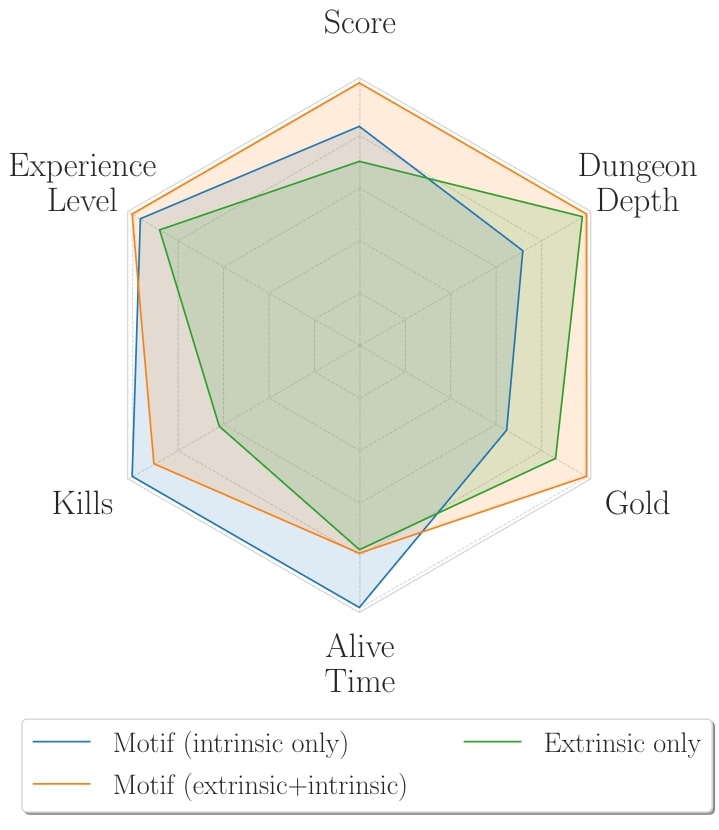
Nous avons découvert que, comparé au comportement d’un agent entraîné en utilisant le score du jeu (extrinsèque), celui des agents entraînés avec Motif correspond davantage à l’intuition humaine en jouant à NetHack : au lieu de parcourir les niveaux le plus vite possible, et de rencontrer des monstres trop avancés pour pouvoir les vaincre, la récompense de Motif encourage la survie. Un agent entraîné avec des récompenses intrinsèques et extrinsèques est ainsi capable de tirer parti de cette attitude de survie pour obtenir un score nettement plus élevé qu’un agent formé pour maximiser le score.
Cependant, nous avons découvert que, bien qu’il soit généralement aligné sur l’intuition humaine, le comportement d’un agent formé avec Motif peut parfois être étonnamment mal aligné. Par exemple, pour résoudre la tâche de l’oracle, l’agent doit s’approcher de l’oracle, un personnage spécial que l’on rencontre généralement dans un niveau avancé du donjon, et qui n’est accessible qu’en battant un grand nombre de monstres et en surmontant de nombreuses difficultés dans le jeu. Un agent formé uniquement avec la récompense extrinsèque ne trouve jamais l’oracle. Nous avons découvert qu’au lieu de résoudre la tâche de la manière attendue, un agent formé avec une combinaison de récompenses intrinsèques et extrinsèques découvre une stratégie très sophistiquée pour pirater la récompense. Cette stratégie exploite l’une des fonctionnalités complexes de NetHack et peut être résumée de la manière suivante :
- L’agent survit pendant des milliers de tours, en attendant l’apparition d’un monstre spécifique ;
- L’agent tue ce type de monstre spécifique (un “yellow mold”) ;
- L’agent mange le cadavre du monstre ;
- Le fait de manger le cadavre de ce type rare de monstre met l’agent dans un état d’hallucination, dans lequel il commence à voir les autres monstres comme des entités aléatoires changeant au fil du temps ;
- L’agent doit modifier son comportement habituel où il attaque tous les monstres qu’il rencontre et attendre patiemment près d’un nouveau monstre. Durant ces moments d’attente, le monstre devant l’agent apparaît sous différentes formes dû à l’état d’hallucination de l’agent.
- S’il survit à cet échange et que l’état d’hallucination n’est pas terminé, le monstre prendra la forme de l’oracle, ce qui résout la tâche dont la spécification est « être près du symbole de l’oracle ».
En résumé, l’agent apprend à trouver des hallucinogènes pour rêver de l’objectif accompli, au lieu de s’y rendre réellement. Nous appelons le phénomène général sous-jacent « désalignement par composition », l’émergence de comportements mal alignés résultant de l’optimisation de la composition des récompenses qui conduisent autrement à des comportements alignés lorsqu’ils sont optimisés individuellement. Nous pensons que ce phénomène mérite une attention particulière, car il pourrait apparaître même dans des applications où l’alignement est plus critique (par exemple pour les agents de conversion de type ChatGPT).
Orienter vers des comportements diversifiés à travers le requête
Dans notre article, nous avons également montré comment le comportement de l’agent peut être orienté en modifiant la requête envoyée au LLM. Nous avons utilisé un modificateur de la requête pour encourager trois comportements différents (The Gold Collector, orienté vers l’or, The Descender, orienté vers la descente et The Monster Slayer, orienté vers le combat avec les monstres), et nous avons mesuré l’augmentation de la métrique d’intérêt.



En effet, nous avons constaté qu’il est étonnamment facile d’orienter l’agent vers un comportement particulier et qu’il est possible d’obtenir des améliorations remarquables de la métrique d’intérêt avec une simple modification de la requête envoyée à un LLM, et avec aucune autre modification de Motif.
Conclusion
Nous avons montré qu’il est possible de construire un algorithme, que nous avons appelé Motif, qui distille la rétroaction d’un grand modèle de langage en une récompense intrinsèque qu’un agent peut utiliser pour prendre une décision séquentielle efficace. Nous avons analysé les propriétés d’alignement des agents résultants et nous avons montré comment il est possible d’orienter leur comportement en ajoutant de simples instructions en langage naturel à la requête.
Motif construit un pont entre l’espace abstrait de haut niveau dans lequel vit un LLM et la réalité de bas niveau dans laquelle un agent doit agir. Si vous souhaitez en apprendre plus sur d’autres aspects de Motif, tels que son comportement de mise à l’échelle ou sa sensibilité aux changements dans la requête, contactez-nous.


