Note de la rédaction : Basé sur des travaux présentés à NeurIPS 2022. Ce billet de blogue a été publié à l’origine sur le Google AI Blog le 3 novembre 2022.
L’apprentissage par renforcement (« RL », reinforced learning) est un domaine de l’apprentissage automatique qui se concentre sur l’entraînement d’agents intelligents en utilisant des expériences liées pour leur apprendre à résoudre des tâches impliquant une prise de décision, comme jouer à des jeux vidéo, piloter des ballons stratosphériques et concevoir des puces électroniques. En raison du caractère général de la RL, les recherches se concentrent sur le développement d’agents pouvant apprendre efficacement en mode « tabula rasa », à savoir, de zéro sans utiliser de connaissances préalablement acquises sur le problème. Cependant, en pratique, les systèmes de RL « tabula rasa » sont plus souvent l’exception que la norme pour résoudre des problèmes de RL de grande amplitude. Les systèmes de RL à grande échelle comme OpenAI Five, qui permettent d’atteindre des performances égales à l’homme sur Dota 2, passent par de nombreuses modifications de conception (ex. : modifications algorithmiques ou architecturales) pendant leur cycle de développement. Ce processus de modification peut durer des mois et exige d’intégrer ces changements sans avoir à reprendre de zéro l’apprentissage de la machine, car cela aurait un coût exorbitant.
De plus, l’inefficacité des recherches en RL « tabula rasa » peut détourner de nombreux chercheurs de la résolution de problèmes demandant des ressources informatiques importantes. Par exemple, la référence ultime pour l’entraînement d’un agent d’apprentissage par renforcement profond (« deep RL ») sur les 50 jeux ou plus d’Atari 2600 dans ALE pour 200 millions d’images (le protocole standard) nécessite plus de 1 000 jours GPU. À mesure que la deep RL se tourne vers des problèmes de plus en plus complexes et difficiles à résoudre, la barrière informatique pour se lancer dans des recherches en RL devrait devenir plus difficile à franchir.
Pour répondre aux inefficacités de la RL tabula rasa, nous présentons « l’apprentissage par renforcement réincarné : réutiliser les calculs pour accélérer le progrès » pendant la conférence NeurIPS 2022. Ici, nous proposons une autre approche à la recherche en RL, selon laquelle l’ancien travail de calcul, comme les modèles appris, les politiques, les données enregistrées, etc., sont réutilisés ou transmis entre les cycles de conception d’un agent RL ou d’un agent à l’autre. Même si certains sous-domaines de la RL exploitent les anciens calculs, la plupart des agents de RL suivent surtout un mode d’apprentissage de zéro. Jusqu’ici, il n’y a pas eu d’effort important pour mettre à profit le travail de calcul dans le flux de travail d’entraînement dans la recherche en RL. Nous avons aussi publié notre code et nos agents entraînés pour permettre aux chercheurs de capitaliser sur ce travail.

Pourquoi la RRL?
La RRL est un flux de travail plus efficace en matière de calculs et d’échantillons que l’apprentissage de zéro (RL). La RRL peut démocratiser la recherche en permettant à la communauté au sens large de s’attaquer à des problèmes de RL complexes sans disposer de grosses ressources informatiques. De plus, la RRL permet un paradigme de référence où les chercheurs peuvent améliorer et actualiser sans cesse les agents entraînés actuels, en particulier sur des problèmes où l’amélioration des performances a un impact réel, comme le pilotage des ballons ou la conception de puces électroniques. Enfin, les cas d’utilisation pratique de la RL suivront probablement des scénarios dans lesquels des travaux de calcul sont déjà disponibles (ex. : politiques de RL déjà déployées).
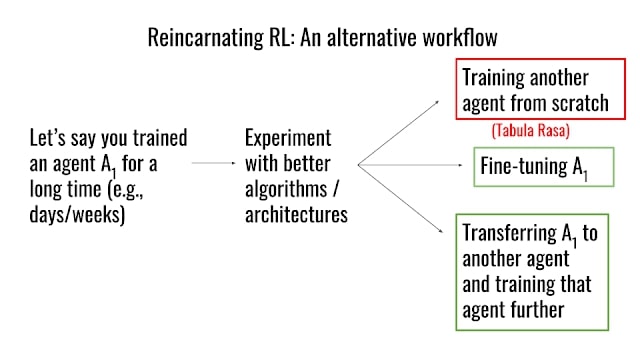
Même s’il existe ponctuellement des efforts de réincarnation à grande échelle avec un domaine d’application limité, ex.: chirurgie modèle dans Dota 2, distillation de politique dans le Rubik’s cube, PBT dans AlphaStar, affinement par la RL d’une politique comportementale clonée dans AlphaGo/Minecraft, la RRL n’a pas fait l’objet en soi d’un thème de recherche. C’est pourquoi nous plaidons pour le développement d’approches de RRL d’ordre général plutôt que de solutions ponctuelles, comme jusqu’ici.
Cas d’étude : RRL policy to value
Différents problèmes de RRL peuvent être instanciés en fonction du type de travail de calcul préalablement fourni. Comme avancée dans le développement d’approches de RRL applicables au sens large, nous présentons un cas d’étude sur la configuration de la RRL Policy to Value (PVRL) pour transférer efficacement une politique sous-optimale (professeur) à un agent autonome de RL basé sur la valeur (élève). Même si une politique associe directement un état environnemental donné (ex. : un écran de jeu dans Atari) à une action, les agents basés sur la valeur estiment l’efficacité d’une action à un état donné en fonction de la récompense future qu’ils peuvent obtenir, ce qui leur permet d’apprendre à partir de données déjà recueillies.
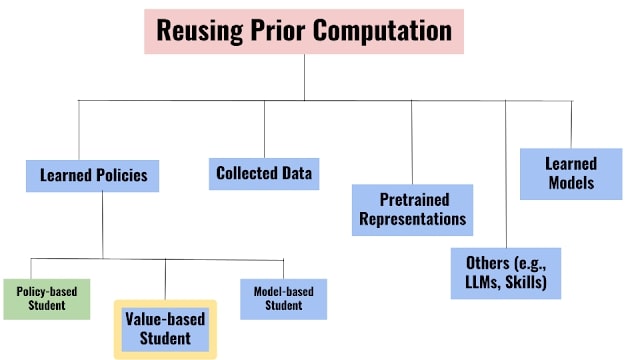
Pour qu’un algorithme de PVRL soit utile au sens large, il doit satisfaire les exigences suivantes :
- Être indépendant du professeur: L’élève ne doit pas être contraint par l’architecture de la politique du professeur ou par l’algorithme d’entraînement.
- Sevrage du professeur: Il n’est pas souhaitable de maintenir la dépendance aux anciens professeurs sous-optimaux pour les réincarnations successives.
- Efficacité en matière de calcul/d’échantillon: La réincarnation n’est utile que si elle est moins chère que l’apprentissage de zéro.
Compte tenu des exigences d’algorithme PVRL, nous évaluons si les approches actuelles, conçues avec des objectifs très proches, seront suffisantes. Nous trouvons que ces approches entraînent de petites améliorations de la RL tabula rasa ou diminuent les performances lors du sevrage du professeur.
Pour répondre à ces limitations, nous introduisons une méthode simple, QDagger, à travers laquelle l’agent distille la connaissance du professeur sous-optimal à travers un algorithme d’imitation tout en utilisant simultanément ses interactions avec l’environnement pour la RL. Nous commençons avec un agent de réseau Q profond (« DQN ») entraîné sur 400 millions d’images de l’environnement (une semaine d’entraînement avec une seule GPU) et l’utilisons comme professeur pour réincarner des agents-élèves entraînés sur 10 millions d’images (quelques heures d’entraînement) seulement, où le professeur est sevré sur les 6 premiers millions d’images. Pour l’évaluation de référence, nous analysons la moyenne interquartile de la bibliothèque RLiable. Comme indiqué ci-dessous pour le paramètre PVRL sur les jeux Atari, nous trouvons que la méthode de RRL QDagger dépasse les approches précédentes.
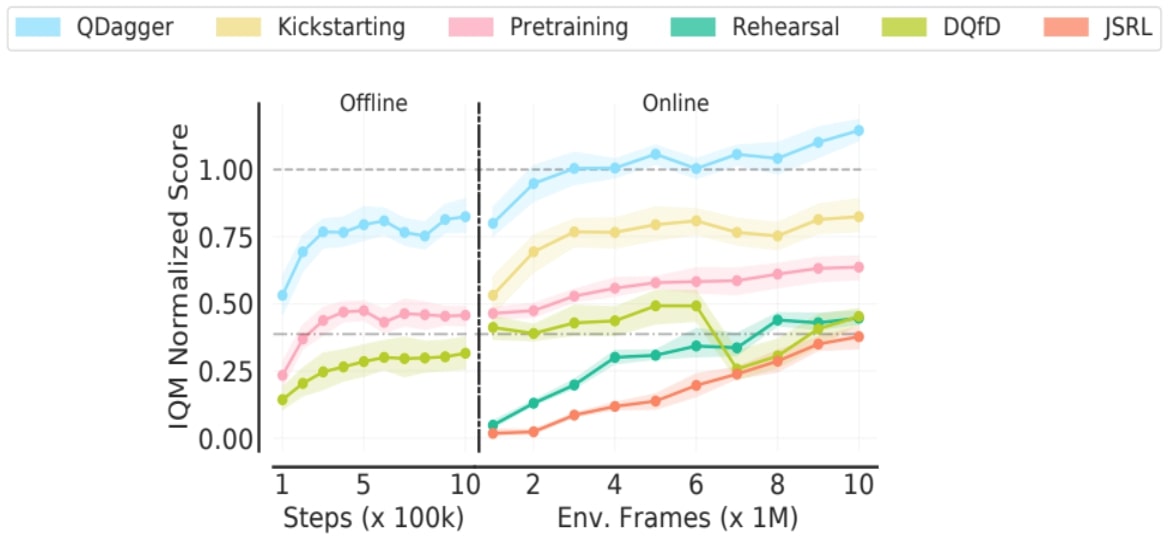
RRL en pratique
Nous examinons l’approche RRL sur l’environnement d’apprentissage des jeux d’arcade, une référence d’apprentissage par renforcement profond très populaire. D’abord, nous prenons un agent DQN Nature qui utilise l’optimisateur RMSProp et l’affinons avec l’optimisateur Adam pour créer un agent DQN (Adam). Même s’il est possible d’entraîner un agent DQN (Adam) de zéro, nous prouvons que l’affinage du DQN Nature avec l’optimisateur Adam atteint les mêmes performances que l’entraînement de zéro en utilisant 40x moins de données et de calculs.
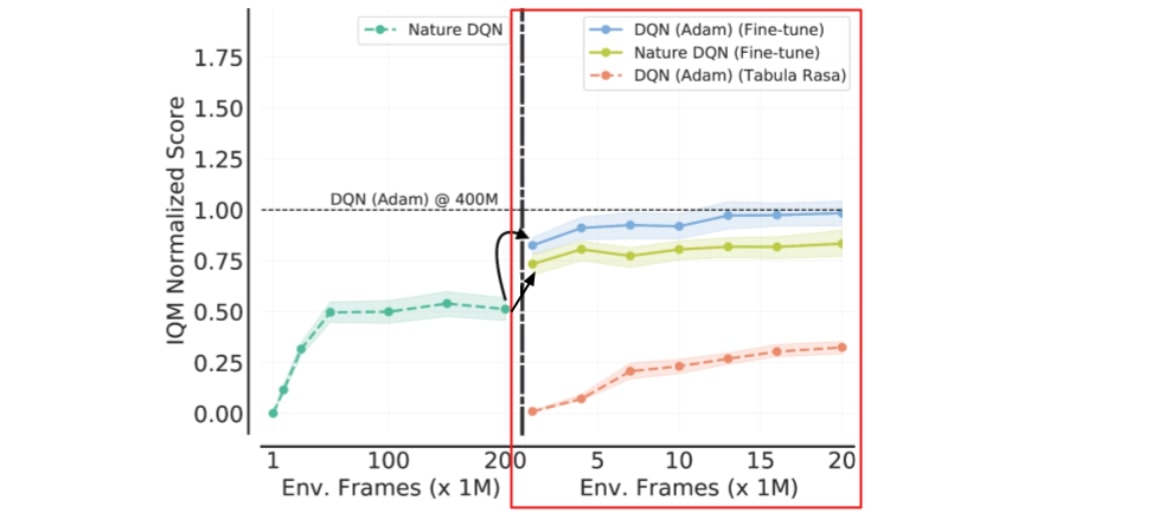
En utilisant l’agent DQN (Adam) comme point de départ, l’affinage est limité à l’architecture convolutive en trois couches. Nous considérons donc une approche de réincarnation plus générale qui met à profit les avancées architecturelles et algorithmiques récentes sans réaliser l’entraînement de zéro. En particulier, nous utilisons QDagger pour réincarner un autre agent RL qui utilise un algorithme RL plus avancé (Rainbow) et une meilleure architecture de réseau de neurones (Impala-CNN ResNet) que l’agent DQN (Adam) affiné.
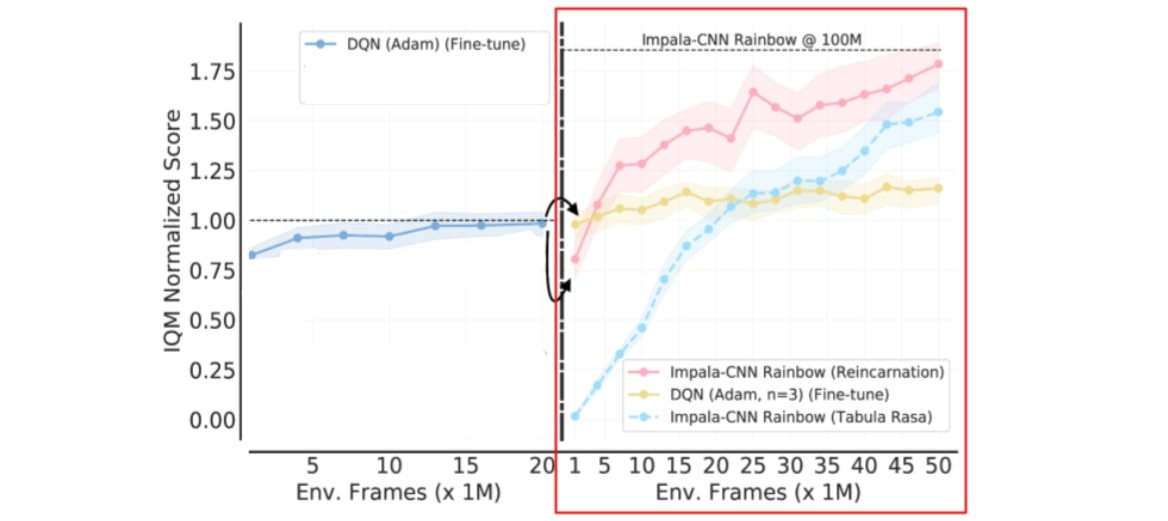
Dans l’ensemble, ces résultats indiquent que les recherches auraient pu être accélérées en intégrant une approche RRL dans la conception des agents, plutôt que de refaire leur apprentissage de zéro. Notre publication contient aussi des résultats sur l’environnement d’apprentissage du pilotage de ballons, où nous démontrons que la RRL nous permet d’avancer sur le problème du pilotage de ballons stratosphériques en n’utilisant que quelques heures de calcul TPU en réutilisant un agent de RL distribuée entraîné sur les TPU depuis plus d’un mois.
Discussion
Pour comparer la réincarnation avec justesse, il convient d’utiliser le même travail de calcul et le même processus de travail. De plus, les résultats de recherches en RRL qui généralisent largement portent sur l’efficacité avec laquelle un algorithme accède à du travail de calcul existant, ex. : nous avons réussi à appliquer QDagger développé en utilisant Atari pour la réincarnation sur l’environnement d’apprentissage du pilotage de ballons. Ainsi, nous spéculons que la recherche sur la RRL peut s’orienter dans deux directions :
- Références standardisées avec un travail de calcul en source ouverte: De manière semblable à NLP et à vision, où un petit ensemble de modèles préentraînés est courant, les recherches en RRL pourront aussi converger vers un petit ensemble de travail informatique en source ouverte (ex. : politiques professeur préentraîné) sur un référentiel donné.
- Domaines réels: Comme l’obtention de meilleures performances a un impact réel dans certains domaines, cela encourage la communauté à réutiliser des agents de premier plan et à essayer d’améliorer leurs performances.
Voir notre publication pour une discussion plus ample sur les comparaisons scientifiques, le caractère général et reproductible en RRL. Dans l’ensemble, nous espérons que ce travail motivera les chercheurs à publier des travaux de calcul (ex. : points de contrôle de modèle) sur lesquels d’autres pourront directement s’appuyer. À cet égard, nous avons mis notre code et nos agents entraînés en source ouverte avec leurs tampons de jeu définitif. Nous croyons que la RRL peut accélérer fortement la progression de la recherche en s’appuyant sur du travail de calcul existant, plutôt que de toujours repartir de zéro.
Remerciements
Ce travail a été réalisé en collaboration avec Pablo Samuel Castro, Aaron Courville et Marc Bellemare. Nous aimerions remercier Tom Small pour l’animation utilisée dans cette publication. Nous sommes aussi reconnaissants des commentaires des analystes anonymes de NeurIPS et de plusieurs membres de l’équipe de recherche de Google, DeepMind et Mila.