



Based on the work published at NeurIPS 2023.
The Problem
Across various domains, a primary goal is to design objects with specific desired properties. For example, we want to design a new robot to make it run faster.

However, in real-world scenarios, evaluating the objective function can be expensive or risky. In this case, imagine that we may have to design and create many new robots and test their running speed, in order to find an optimal design, which is very costly and time-consuming. As a result, it is often more practical to assume access only to an offline dataset of designs and their property scores, i.e. the pair of robot size and running speed. This type of problem is referred to as offline model-based optimization (MBO). The goal of MBO is to find a design that maximizes the unknown objective function using solely the offline dataset. Our discussion ahead will focus on this issue.
Related Work and Motivation
To address the offline MBO problem, a proxy function is commonly used, which is an approximation of the unknown objective function.
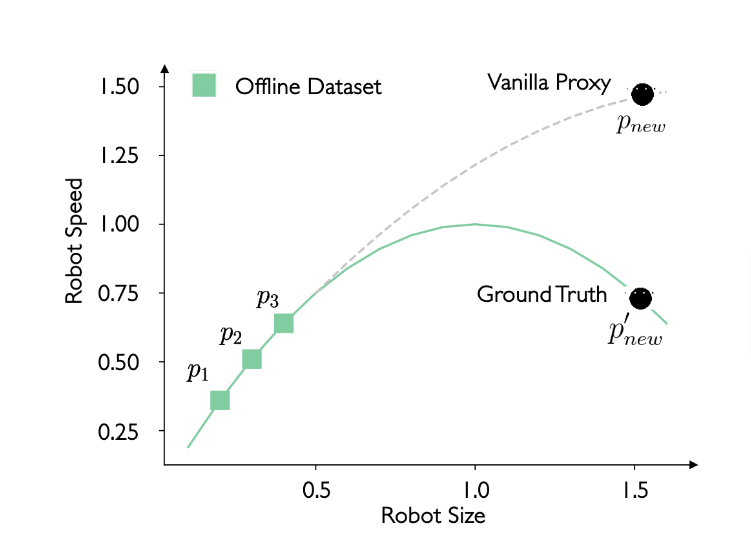
For example, as illustrated above, the offline dataset may consist of three robot size and robot speed pairs p1, p2, and p3. A simple DNN model (e.g., a 3-layer MLP (MultiLayer Perceptron)), referred to as the vanilla proxy, is trained to fit these three pairs, which then can predict the robot’s running speed given its size. However, there might be a gap between the vanilla proxy and the ground-truth objective function. In this research, one primary goal is to reduce this gap and make our proxy function more accurate.
Importance-Aware Co-teaching
We explore a method which aims to train a better proxy closer to the ground-truth function and thus mitigate the out-of-distribution issue.
Imagine a better situation: What if we have more data points?
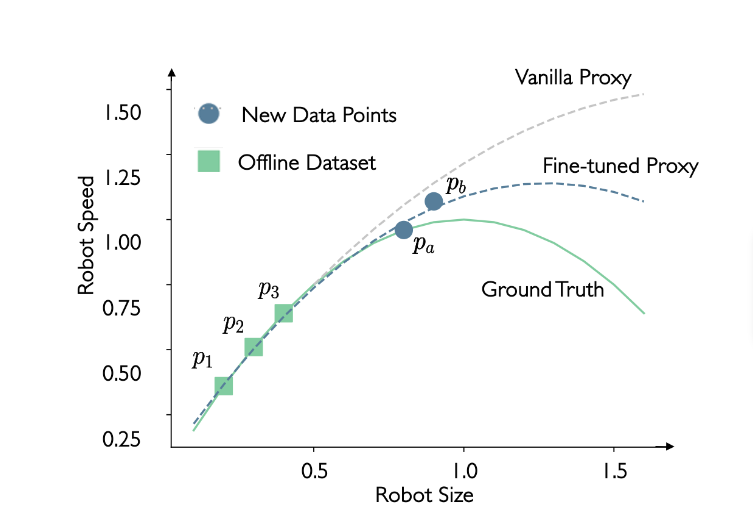
As shown in the figure above, with the new data points pa and pb, we might be able to fine-tune our vanilla proxy and get a better proxy, which is closer to the ground-truth function. However, two new questions arise. (1) How do we obtain these new data points? (2) How can we identify the more accurate (closer to the ground-truth) ones?
To address these two challenges, we introduce a new method: importance-aware co-teaching (ICT). This approach maintains three proxies simultaneously and consists of two main steps.
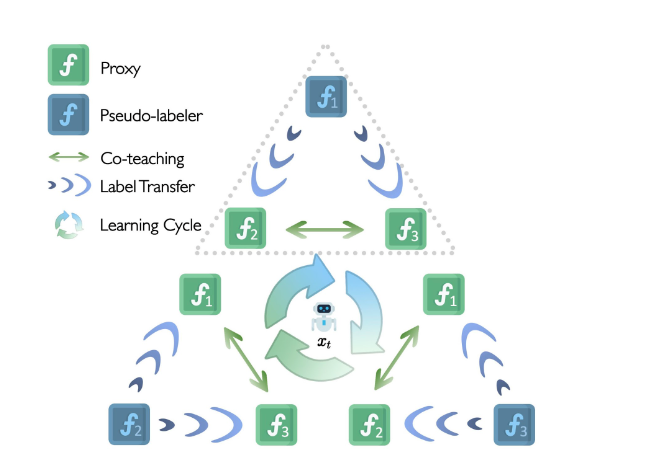
The first step is pseudo-label-drive co-teaching.
- As depicted in the figure above, we maintain three symmetric proxies f1, f2, and f3 at the same time, computing their mean ensemble as the final proxy function.
- We select f1 as the pseudo-labeler to generate pseudo labels for a set of points in the neighborhood of the current optimization point xt. The other two proxies, f2 and f3, then receive the pseudo-labeled dataset. They compute the sample loss and exchange small-loss samples between them for fine-tuning.
- The symmetric nature of the three proxies allows the above process to repeat three times, with each proxy taking turns as the pseudo-label generator.
This co-teaching process encourages knowledge transfer between the two proxies, as small losses are typically indicative of valuable knowledge, allowing them to collaboratively improve the ensemble performance in handling out-of-distribution designs.
Furthermore, we introduce the meta-learning-based sample reweighting as the second step of ICT, which aims to assign higher weights to more accurate points and lower weights to less accurate ones in the pseudo-labeled dataset. This is achieved as follows:
- We assign an importance weight for every sample yielded by the first step.
- To update these importance weights, we leverage the supervision signals from the offline dataset. If the sample weights are accurate, the proxy fine-tuned on the weighted samples is expected to perform well on the offline dataset.
- When updating the importance weights, we fix the model and calculate the gradients with respect to the importance weights, then use gradient descent to update the importance weights.
Experimental Results
In this study, we conduct experiments on four continuous tasks and three discrete tasks. The continuous tasks include:
(a) Superconductor (SuperC), where the objective is to develop a superconductor with several continuous components to maximize critical temperature;
(b) Ant Morphology (Ant) and D'Kitty Morphology (D'Kitty), where the aim is to design a quadrupedal Ant or D'Kitty with continuous components to improve crawling speed;
(c) Hopper Controller (Hopper), where the aim is to identify a neural network policy with thousands of weights to optimize return.
Additionally, our discrete tasks include:
(d) TF Bind 8 (TF8) and TF Bind 10 (TF10), where the goal is to discover an 8-unit/10-unit DNA sequence that maximizes binding activity score;
(e) NAS, where the objective is to find the optimal neural network architecture to enhance test accuracy on the CIFAR-10 dataset.
In summary, we aim to identify the optimal designs or sequences for every task, targeting the maximum potential of the subject, whether that's a robot, DNA sequence, or superconductor. To assess the performance of our method, we report the normalized score of the top-performing design for each task. This score offers a uniform way to gauge the performance of each design against its peers, ensuring a straightforward metric for fair comparison.
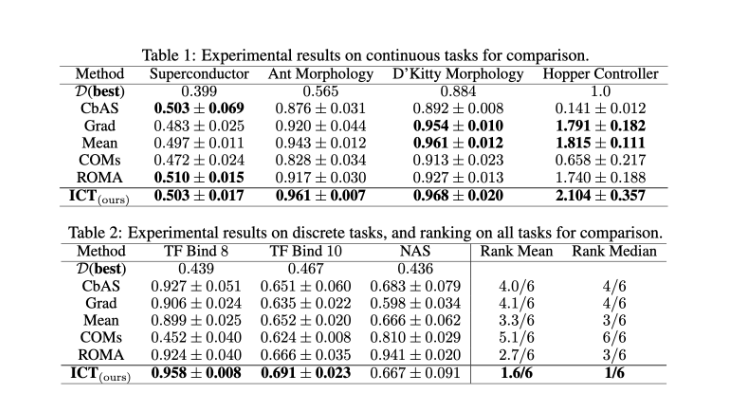
We observe the following key points based on our experimental results:
- In all four continuous tasks, our ICT method achieves the top performance. Notably, it surpasses the basic gradient ascent, Grad, demonstrating its ability to mitigate the out-of-distribution issue.
- Furthermore, ICT generally outperforms the mean ensemble methods (Mean) and other gradient-based techniques such as COMs and ROMA, demonstrating the effectiveness of our strategy.
- Generative model-based methods, such as CbAS, however, struggle with the high-dimensional task Hopper Controller. Interestingly, ICT necessitates only three standard proxies and avoids the need for training a generative model, which can often be a challenging task.
- ICT attains top performances in two out of the three discrete tasks, TF Bind 8 and TF Bind 10.
- ICT attains the highest rankings with a mean of 1.6/6 and median of 1/6 among many baseline methods as shown in the tables above, and also secures top performances in 6 out of the 7 tasks. These results indicate that ICT is a simple yet potent baseline for offline MBO.
Conclusion
We present the ICT (Importance-aware Co-Teaching) approach, a solution to the pervasive out-of-distribution issue in offline model-based optimization. This method demonstrates the effectiveness of the knowledge transfer among the three proxies and improves the ensemble performance accordingly, which can mitigate the issue of out-of-distribution in MBO. Our experimental findings demonstrate the success of ICT.


