



When approaching a new task, humans leverage the common sense acquired during their lifetime. If they encounter a key, they know that it could be used to open a door; if they encounter a door, they know new information could be found behind it. They have a sense of what is good, or interesting, in a new situation even before having directly interacted with that situation. How can we empower an artificial intelligence agent with a similar capability? In our new work, we show that it is possible to do so by enabling agents to learn from artificial intelligence feedback, where feedback is given by an LLM as preferences over pairs of events in an environment. In this blog post, we are going to discuss why leveraging such common sense can be important, and we are going to describe a method for training an agent with a Large Language Model’s feedback. We will then present our evaluation of this method on NetHack that requires complex planning skills to be successful.
Large Language Models as a source of common sense
By writing about the world they see or imagine, humans have crystallized a significant amount of common sense as written text stored on the Internet. Large Language Models (LLMs) trained on Internet-scale datasets make that knowledge easily accessible, but that is per se not enough to leverage it for sequential decision-making.
LLMs operate at a high-level language space, but decision-making often needs to happen at a different level of abstraction: an agent interacting with the environment needs to see the world and to execute fine-grained actions through its actuators. To leverage an LLM’s common sense, the gap between its high-level knowledge and the low-level sensorimotor reality in which the agent operates needs to be bridged.
Fortunately, evaluating is often easier than generating: instead of understanding every detail of the observations or actions, an LLM could inform an agent by just saying whether an event is good or bad, without requiring any complete language interface with the world. This will be the basic principle behind our method.
NetHack as a challenging testbed that requires common sense
NetHack is a rogue-like videogame, in which a player has to go through different levels of a dungeon, killing monsters, gathering objects and overcoming significant difficulties. Since human common sense can go a long way for information gathering, exploration and fruitful interactions with the kind of entities that can be found in the game, NetHack offers an ideal testbed for demonstrating how useful the common sense knowledge coming from an LLM can be.
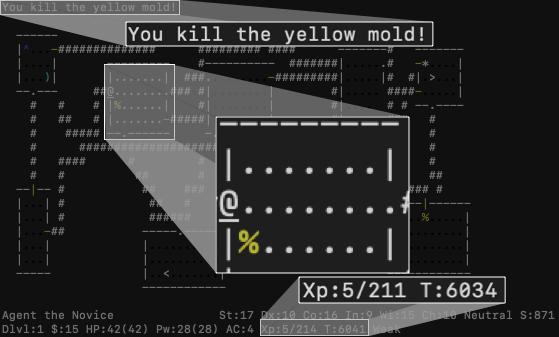
NetHack is a natural domain to test whether feedback on events happening in the environment is enough to create the bridge between the LLM’s and the agent’s levels of abstractions: it presents some captions (called messages) which describe positive, negative or neutral happenings in the game, appearing e.g., when a monster attacks or the agent reaches a new dungeon level.
Motif: Intrinsic Motivation from Artificial Intelligence Feedback
We propose Motif, an algorithm that empowers an agent with common sense by extracting a reward function (i.e., a scalar signal indicating the desirability of a certain situation in the game) from an LLM and giving it to the agent interacting with the environment. Motif leverages recent ideas from reinforcement learning from AI feedback, asking an LLM to rank event captions and then distilling those preferences into a reward function.
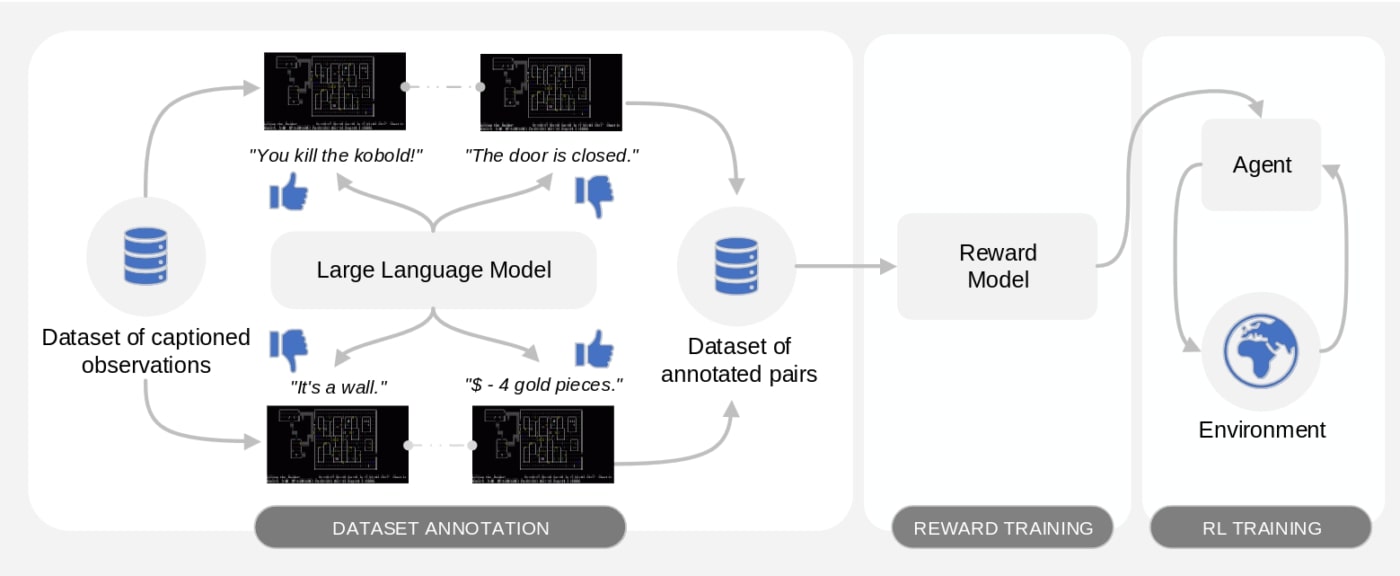
Our method features three phases. In the first phase, given a dataset of observations with event captions (e.g., game messages in NetHack), it samples and ranks pairs based on the preferences given by an LLM according to its perception of how good and promising they are in the environment. In the second phase, the resulting dataset of annotated pairs is used to learn a reward model from preferences. In the third phase, this reward function is given to an agent interacting with the environment and used to train it with reinforcement learning, possibly alongside a reward coming from the environment.

We prompt a Llama 2 model asking it to give preferences on random pairs of messages, using a prompting style inspired by chain-of-thought.
Performance of Motif
We test the performance of Motif on a set of tasks from the NetHack Learning Environment. We both test the cases in which the agent only uses the reward from the LLM’s preferences (called intrinsic) and the combination of that with the one from the environment (called extrinsic).
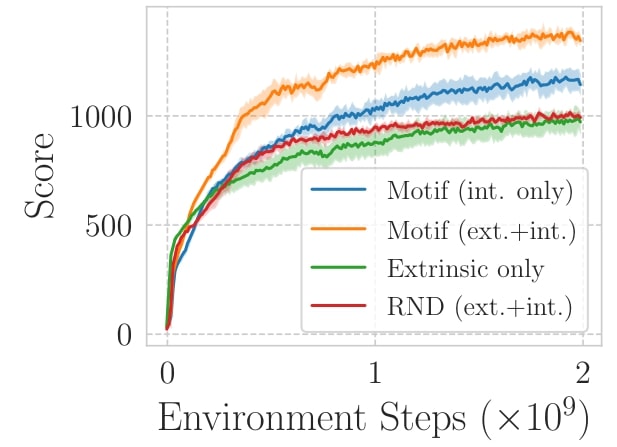
Maximizing the score of NetHack is one of the most natural tasks to be confronted with in the game. The game gives a score when certain events happen, such as getting to the next level or killing a monster. In this task, we showed that agents trained exclusively with Motif’s intrinsic reward surprisingly outperform agents trained using the score itself, and perform even better when trained with a combination of the two reward functions.
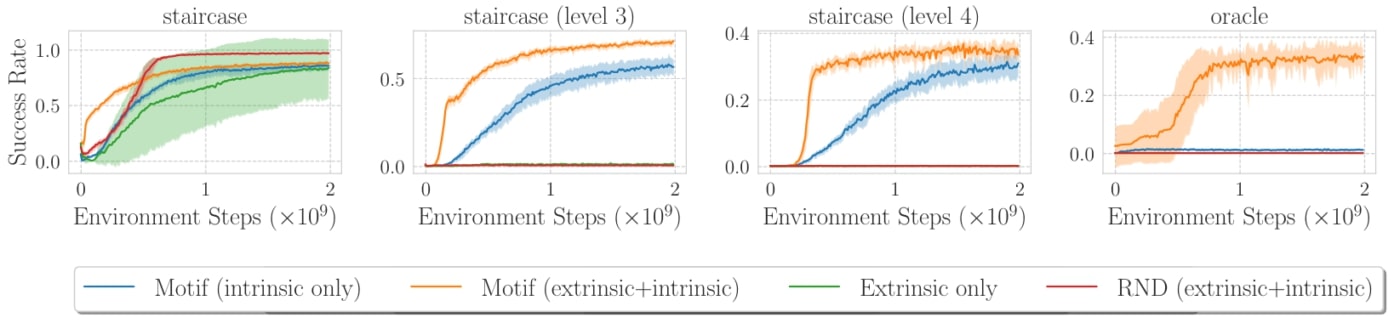
We showed that Motif outperforms existing methods also in a sparse-reward setting, in which a reward is only given when a certain dungeon level or character is reached. Motif obtains good performance in the oracle task, in which no other approach has been able to obtain any meaningful progress without imitating expert players.
Alignment of agents trained with Motif
To understand where the performance of Motif is coming from, we analyzed the behavior of agents trained with Motif’s and the extrinsic reward function.
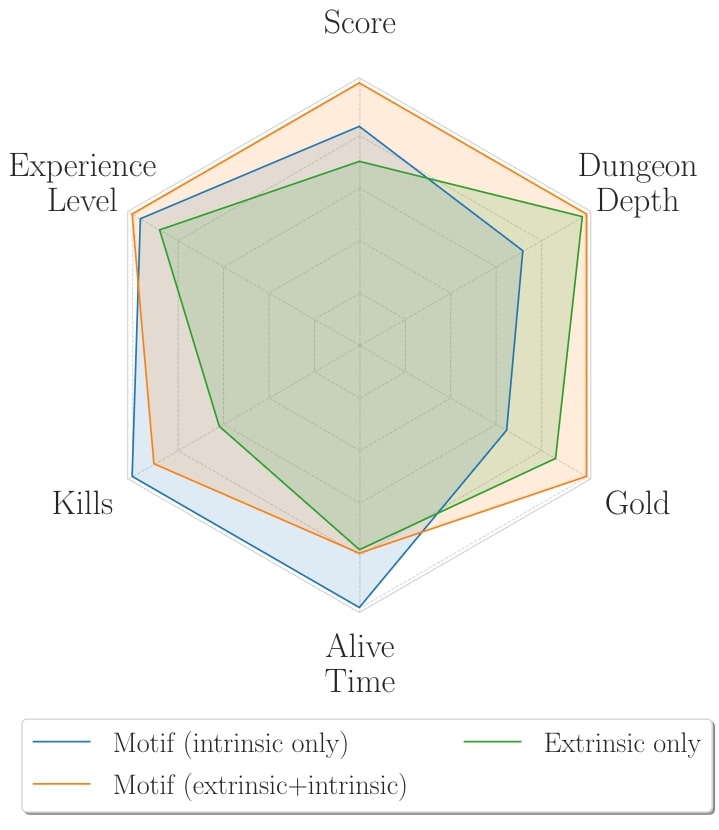
We discovered that, when compared to an agent just trained using the score from the game, the behavior of agents trained with Motif is more aligned with human intuitions on playing NetHack: instead of going to the levels as fast as possible, encountering monsters too strong for its experience level, Motif’s reward encourages survival. An agent trained with both the intrinsic and extrinsic rewards is thus able to leverage this survival attitude to get significantly more score than an agent trained to maximize the score.
However, we uncovered that, despite being generally aligned with human intuition, the behavior of an agent trained with Motif can sometimes be surprisingly misaligned. To solve the oracle task, the agent has to get near the oracle, a special character typically encountered in an advanced level of the dungeon, only reachable by defeating a large number of monsters and overcoming many difficulties in the game. An agent only trained with the extrinsic reward never finds the oracle. We discovered that, instead of solving the task in the expected manner, an agent trained with a combination of intrinsic and extrinsic reward discovers a very sophisticated strategy to hack the reward. The strategy leverages one of the complex features of NetHack: in summary, the agent learns to find hallucinogens to dream of the goal state, instead of actually going there. We name the underlying general phenomenon misalignment by composition, the emergence of misaligned behaviors from optimizing the composition of rewards that otherwise lead to aligned behaviors when optimized individually. We believe that this phenomenon deserves particular attention, since it could emerge even in more alignment-critical applications (e.g., for chat agents).
Steering towards diverse behaviors via prompting
In our paper, we also showed how the behavior of the agent can be steered by modifying the prompt given to the LLM and thus its preferences. We used a modifier of the prompt to encourage three different behaviors (the gold-oriented The Gold Collector, the descent-oriented The Descender, and the monster-killing-oriented The Monster Slayer), and measured how much of an increase to the metric of interest it is possible to obtain with simple prompt modifiers.



Indeed, we found it is surprisingly easy to steer the agent to a particular behavior, and that it is possible to obtain remarkable improvements in the metric of interest with just a minimal modification to an LLM’s prompt and no other modification to Motif.
Conclusion
We showed with our work that it is possible to build an algorithm, that we called Motif, distilling the feedback from a Large Language Model into an intrinsic reward that an agent can use to perform effective sequential decision-making. We analyzed the alignment properties of the resulting agents and we showed how it is possible to steer their behavior by adding simple instructions in natural language to the prompt.
Motif bridges the high-level abstract space in which an LLM lives with the low-level reality in which an agent needs to act. If you are curious about other aspects of Motif, such as its scaling behavior or its sensitivity to changes in the prompt, read our paper or get in touch with us.


