Editor's Note: This blog post was originally published on the author’s personal website and has been reviewed and adapted for the Mila blog with the author’s consent. The following is a summary and Q&A of a recent paper of the same name co-authored by Zhao and other Mila researchers. This paper was accepted at NeurIPS 2021.
We introduce inductive biases into reinforcement learning inspired by higher-order cognitive functions in humans. These architectural constraints enable planning to direct attention dynamically to the interesting parts of the state at each step of imagined future trajectories.
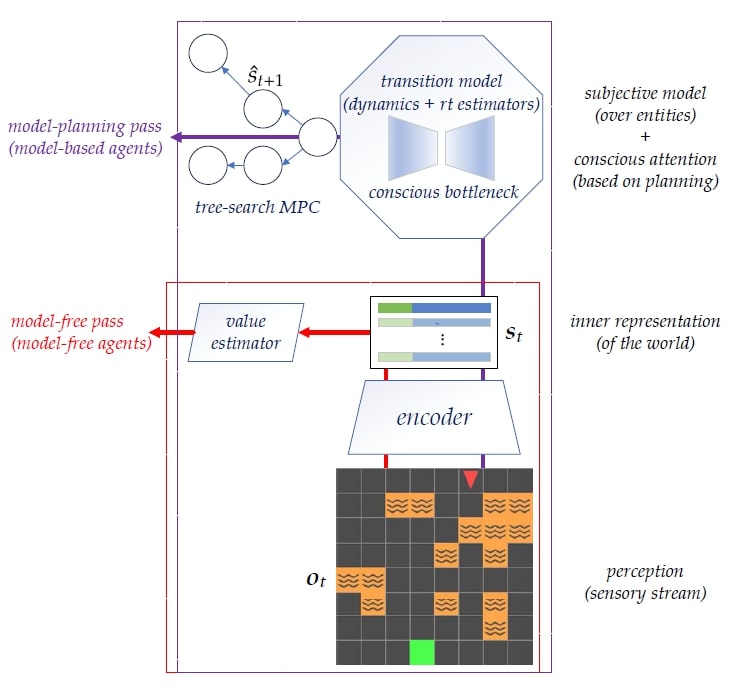
Whether when planning our paths home from the office or a hotel to an airport in an unfamiliar city, we typically focus on a small subset of relevant variables, e.g., the change in position or the presence of traffic. An interesting hypothesis of how this path planning skill generalizes across scenarios supposes that it may be due to computation associated with the conscious processing of information. Conscious attention focuses on a few necessary environment elements, with the help of an internal abstract representation of the world. This pattern, also known as consciousness in the first sense (C1), has been theorized to enable humans’ exceptional adaptability and learning efficiency. A central characterization of conscious processing is that it involves a bottleneck, which forces one to handle dependencies between very few characteristics of the environment at a time. Although this focus on a small subset of the available information is seemingly limiting, it may facilitate Out-Of-Distribution (OOD) and systematic generalization to other situations where the ignored variables are different yet still irrelevant. In this paper, we propose an architecture that allows us to encode some of these ideas into reinforcement learning agents.
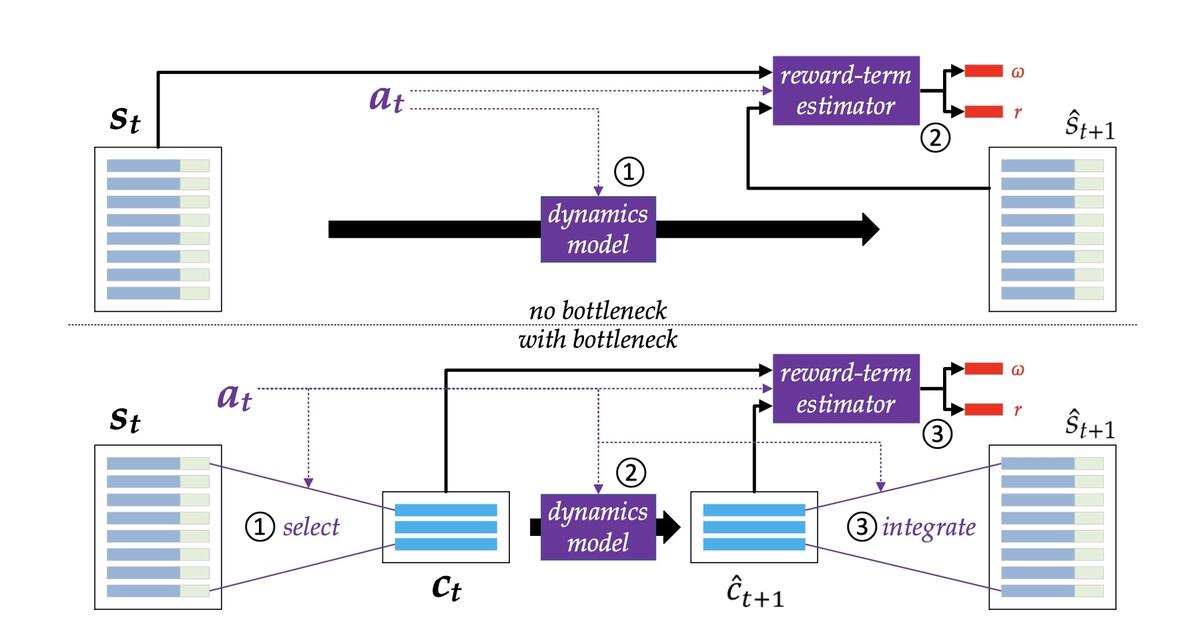
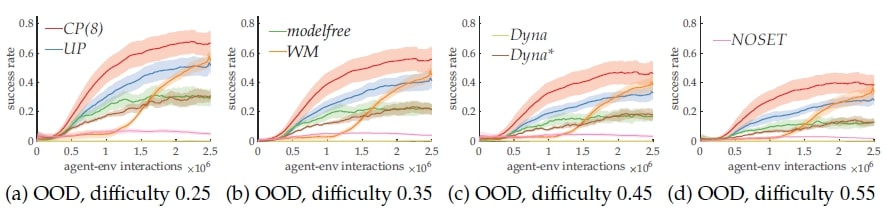
We propose to take inspiration from human consciousness to build an architecture that learns a useful state space and focuses attention on a small set of variables at any time. This idea of “partial planning” is enabled by modern deep RL techniques. Specifically, we propose an end-to-end latent-space MBRL agent which does not require reconstructing the observations, as in most existing works, and uses Model Predictive Control (MPC) for decision-time planning. From an observation, the agent encodes a set of objects as a state, with a selective attention bottleneck mechanism to plan over selected subsets of the state (Sec. 4). Our experiments show that the inductive biases improve a specific form of OOD generalization, where consistent dynamics are preserved across seemingly different environment settings (Sec. 5).
Interesting Q&A
Q: Can you define what you mean by OOD in this work?
A: We focus on skills transferable to totally different environments with consistent dynamics, meaning the environmental dynamics that are sufficient for solving the in-distribution training tasks and the OOD evaluation tasks are consistently preserved. At the same time, the rest can be very different. Intuitively, we want to train our agent to be able to plan routes in the home city and expect this ability to be generalized to other municipalities. The places can be very different, but the route planning skill depends on the knowledge that is quite universal.
Q: Why do you employ a non-static setting where environments change every episode?
A: Intuitively, the agent does not need to understand the dynamics of the task if the environment is fixed: learning to memorize where to go and where not to is far easier than reasoning about what may happen. With the challenges, it became necessary for the agent to learn and understand the environment dynamics, which is crucial for OOD evaluation.
Q: How do you avoid collapse in the state representation?
A: Apart from the training signal for dynamics, whose exclusive existence might cause collapse, all other training signals go through the common bottleneck of the encoder, which leads the representation to be also shaped by the TD signals–the reward-termination prediction signals. We also want to mention that the regularizations participate in this as well.
Q: Why not use richer architectures for experiments?
A: Since there are already many components in the proposed agent, we use the minimal architecture sizes that marginally enable good RL performance on our test settings to isolate possible factors influencing agent behaviors.
Q: Why not use MCTS as the search method for decision-time planning?
A: Unlike AlphaGo, which employs MCTS, our architecture is based on the simplest baseline DQN. DQN uses a value-estimator-based greedy policy instead of a parameterized one as the actor-critic architecture used in AlphaGo. The DQN policy is deterministic w.r.t. the estimated values; therefore, the planning cannot sufficiently take advantage of the sample-based MCTS.
To read the paper on arXiv, click here.
To view the original blog post, click here.
To view our GitHub, click here.
Paper co-authors
Mingde Zhao, PhD Student, McGill University/Mila
Zhen Liu, PhD Student, Université de Montréal/Mila
Sitao Luan, PhD Student, McGill University/Mila
Shuyuan Zhang, PhD Student, McGill University/Mila
Doina Precup, Associate Professor, McGill University/Mila
Yoshua Bengio, Full Professor, Université de Montréal/Mila