Note de la rédaction : Basé sur des travaux publiés à NeurIPS 2021.
Contexte
Les tâches de classification souffrent de deux problèmes courants dans le monde réel: le bruit d’étiquette et le déséquilibre des classes. Par exemple, un « chat » peut être mal étiqueté comme un « chien » (bruit d’étiquette), et le nombre de « chat » dans l’ensemble d’entraînement peut être beaucoup plus petit que celui de « chien » (déséquilibre des classes). Ces deux problèmes peuvent induire en erreur l’entraînement du modèle et faire croire au modèle que l’image du « chat » est « chien », ou qu’il y a beaucoup plus de « chien » que de « chat » dans la réalité, ce qui nuit au rendement du modèle.

De la pondération des instances à la pondération au niveau de la classe
Des travaux antérieurs ont adopté la pondération des instances (où une instance est définie comme une paire image-étiquette) pour résoudre ces deux problèmes. Leurs auteurs s’attendaient à ce que l’utilisation de petites pondérations pour les instances bruitées ou les classes majeures puisse rééquilibrer la distribution des données. Pourtant, dans les méthodes de pondération des instances, les renseignements au niveau de la classe dans les instances sont ignorés, comme illustré ci-dessous.
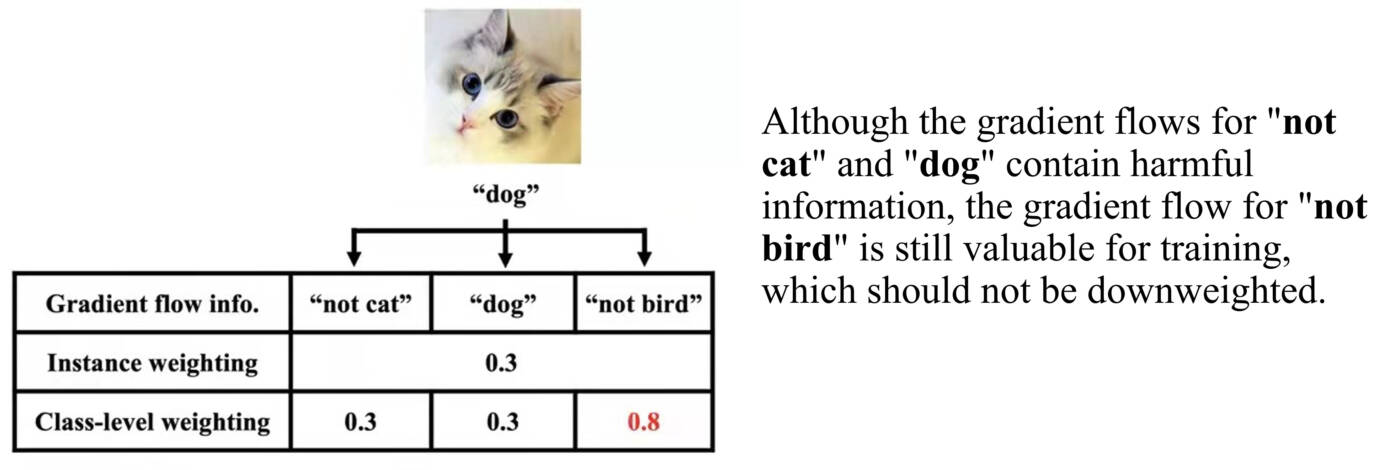
Dans cet exemple, il s’agit d’une tâche de classification à trois classes: chaque instance comprend trois logits qui correspondent à trois types de renseignements : « pas chat », « chien » et « pas oiseau ». Les méthodes de pondération des instances réduisent le bruit d’étiquette en éliminant simultanément les trois types de renseignements. Pourtant, l’élimination de « pas oiseau » est un gaspillage de renseignements utiles. De même, dans les scénarios de déséquilibre des classes, l’utilisation de divers renseignements au niveau de la catégorie améliorera l’entraînement du modèle. Par conséquent, il est nécessaire de repondérer les instances au niveau de la classe pour une meilleure utilisation des renseignements.
À cette fin, nous proposons la pondération des données généralisée (Generalized Data Weighting, GDW) pour lutter contre le bruit d’étiquette et le déséquilibre des classes par la manipulation des renseignements au niveau de la classe. Nous utiliserons le bruit d’étiquette ci-dessus comme exemple. Notre proposition de GDW peut pondérer les renseignements au niveau de la classe et ainsi mieux utiliser les renseignements. Cela comprend les étapes suivantes :
- Nous introduisons trois pondérations au niveau de la classe initialisées chacune à une valeur de 0,5 pour représenter l’importance de trois types de renseignements : « pas chat », « chien » et « pas oiseau ». Ceci est accompli grâce à la dérivation des fonctions composées.
- Ensuite, la question est de savoir comment déterminer un bon ensemble de pondérations au niveau de la classe. En apprentissage automatique, nous maintenons généralement un ensemble de validation distinct de l’ensemble d’entraînement et nous pouvons choisir certains hyperparamètres comme le taux d’apprentissage en fonction de la performance de validation.
- Si nous entraînons le modèle avec de bonnes pondérations au niveau de la classe, nous pouvons nous attendre à ce que le modèle fonctionne bien sur un ensemble de validation et donne de bonnes performances de validation. Nous pouvons traiter ces pondérations au niveau de la classe comme des hyperparamètres et les ajuster en fonction des performances de validation.
- Dans le processus ci-dessus, supposons que les pondérations au niveau de la classe d’origine pour « pas chat », « chien » et « pas oiseau » sont de 0,5, 0,5 et 0,5. Les renseignements « pas chat » et « chien » sont erronés et méritent donc des pondérations faibles comme 0,3 alors que les renseignements « pas oiseau » sont exacts et méritent donc une pondération plus élevée comme 0,8.
- Nous découvrirons que si nous entraînons un modèle avec des pondérations de 0,3, 0,3 et 0,8 au niveau de la classe pour cette image, nous pouvons obtenir un meilleur modèle, qui fonctionne mieux sur l’ensemble de validation. Par conséquent, nous choisirons 0,3, 0,3 et 0,8 comme pondérations au niveau de la classe.
- Le processus ci-dessus formule un problème d’optimisation à deux niveaux tel que décrit dans l’article original. Avec les pondérations à jour au niveau de la catégorie, nous pouvons atténuer l’effet de bruit d’étiquette de l’image pour entraîner un meilleur modèle.
De cette façon, la GDW obtient une amélioration impressionnante de la performance dans divers contextes, car la GDW peut utiliser les renseignements « pas oiseau », qui ont été ignorés dans les travaux antérieurs.
Résultats expérimentaux
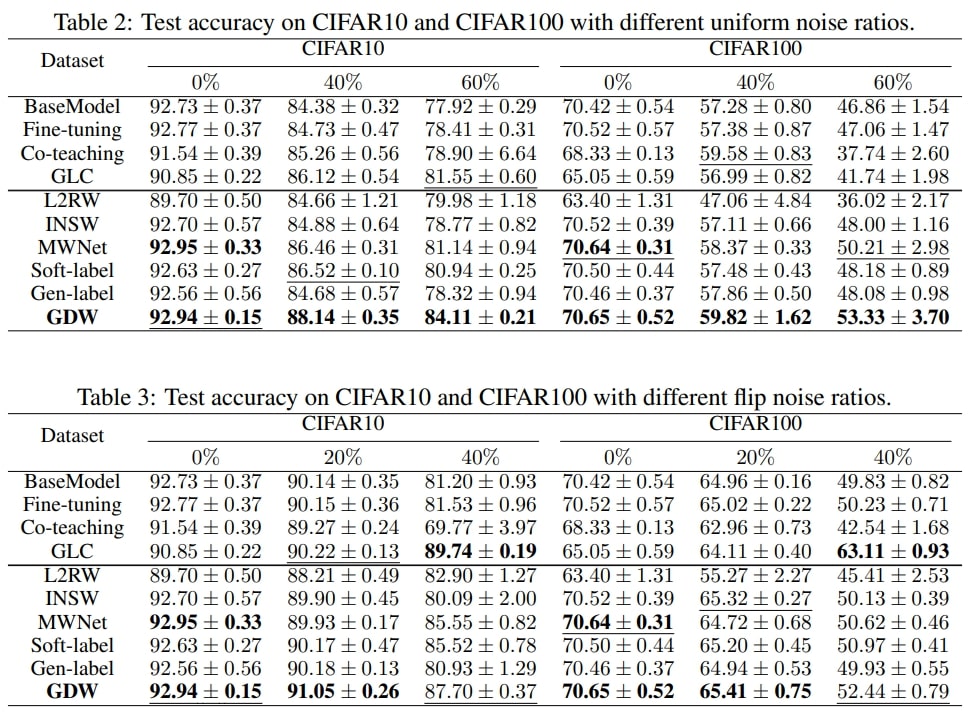
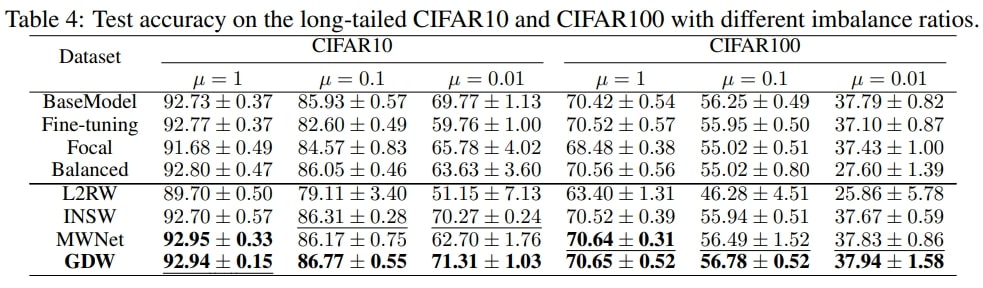
Nous effectuons des expériences sous des conditions de bruit d’étiquette comme indiqué dans le tableau 2 et le tableau 3, et de déséquilibre dans les classes comme indiqué dans le tableau 4 pour vérifier l’efficacité de notre méthode. La mesure d’évaluation ou le nombre indiqué dans les trois tableaux est l’exactitude moyenne de la classification, et nous rapportons la moyenne et l’écart type sur cinq exécutions. La colonne du tableau 2 ou du tableau 3 chapeautant les résultats représente le ratio de bruit. Par exemple, la colonne intitulée 20 % indique que 20 % des images sont bruitées. Voici la différence entre les deux tableaux : le tableau 2 change aléatoirement l’étiquette de l’image (bruit uniforme) avec une certaine probabilité (p. ex., 20 %) tandis que le tableau 3 remplace l’étiquette de l’image (p. ex., chat) par une autre étiquette (p. ex., chien) avec une certaine probabilité (p. ex., 20 %). La colonne du tableau 4 chapeautant les résultats indique le ratio de déséquilibre. Un ratio de 1 indique que toutes les classes de ce jeu de données ont le même nombre d’images, tandis qu’un ratio de 0,01 indique que le nombre de la classe majeure est de 1/0,01 = 100 fois celui de la classe mineure.
Nous avons les observations principales suivantes :
- Tout d’abord, nous pouvons observer que la GDW surpasse presque toutes les méthodes concurrentes sous toutes les conditions de bruit. Cela vérifie l’efficacité de la méthode.
- En outre, sous toutes les conditions de bruit, la GDW a un gain de performance constant par rapport à MWNet, ce qui s’aligne avec notre motivation de pondération au niveau de la classe par rapport à la pondération au niveau de l’instance. Contrairement à la pondération au niveau de l’instance qui élimine tous les renseignements, la pondération au niveau de la classe augmente le flux de gradient « pas oiseau »; ce qui améliore l’entraînement du modèle.
- De plus, à mesure que le ratio augmente en condition de bruit uniforme, l’écart entre la GSW et MWNet augmente également beaucoup dans CIFAR10 et CIFAR100. Même sous le bruit uniforme extrême, la GDW présente toujours de faibles erreurs de test dans les deux jeux de données et obtient des gains de performance expressifs par rapport à la deuxième meilleure méthode. Cela prouve la généralisation de la GDW.
- Enfin, la GDW fonctionne mieux sous presque toutes les conditions de déséquilibre. Cela prouve que la GDW peut bien gérer le déséquilibre des classes.
Conclusion
De nombreuses méthodes de pondération des instances ont récemment été proposées pour s’attaquer au bruit d’étiquette et au déséquilibre des classes, mais elles ne peuvent pas saisir des renseignements au niveau des classes. Ces méthodes éliminent les renseignements utiles au niveau de la classe : « pas oiseau » dans l’exemple ci-dessus. Pour une meilleure utilisation des renseignements lors du traitement des deux problèmes identifiés plus tôt, nous proposons la méthode GDW afin de généraliser la pondération des données du niveau de l’instance au niveau de la catégorie. De cette façon, cette méthode obtient une amélioration remarquable du rendement sous différentes conditions.
Auteurs de l'article original
Can Chen, Shuhao Zheng, Xi Chen, Erqun Dong, Xue (Steve) Liu, Hao Liu, Dejing Dou