Les sciences cognitives révèlent qu’en matière d’apprentissage, les premières expériences des humains ont des effets disproportionnés sur leurs actions ultérieures (Shteingart, Neiman et Loewenstein, 2012), comme en témoigne l’exemple suivant, tiré des travaux précurseurs de Solomon Asch, pionnier de la psychologie sociale :
Les participants ont reçu l’une des deux phrases suivantes : « Steve est intelligent, assidu, critique, impulsif et jaloux » et « Steve est jaloux, impulsif, critique, assidu et intelligent ». Ces deux phrases contiennent les mêmes informations […] Les chercheurs ont constaté que les participants à qui on donnait la première phrase évaluaient Steve plus positivement que ceux à qui on donnait la seconde phrase.
Ce phénomène, appelé « effet de primauté », amène les individus à se souvenir davantage des premières informations obtenues que des informations suivantes. Ce biais cognitif est susceptible d’entraîner des comportements peu efficaces qui sont difficiles à désapprendre ou à améliorer lorsque de nouvelles informations sont présentées. Dans notre récente étude, présentée en juillet à l’ICML 2022, nous constatons que les agents entraînés par apprentissage par renforcement profond peuvent expérimenter des situations similaires lors de leur entraînement. Dans cet article de blogue, nous examinons ce phénomène de manière plus détaillée et nous présentons une stratégie à la fois simple et efficace pour y remédier.
Le rôle des premières expériences dans l’apprentissage par renforcement
Pour entraîner des agents par apprentissage par renforcement profond, il faut généralement faire un compromis entre un entraînement plus agressif sur les données disponibles, qui a pour effet d’augmenter le risque de surapprentissage (« overfitting »), et un apprentissage plus modéré, obtenu généralement en réduisant l’efficacité de l’échantillon. Le surapprentissage, ou la généralisation des premières interactions avec l’environnement, instaure un cercle vicieux à l’origine du mauvais rendement : l’agent recueille des données de moins bonne qualité, ce qui rend difficile l’amélioration du processus d’apprentissage et introduit souvent des comportements moins efficaces.
Lors de l’apprentissage, l’agent exécute des actions dans un environnement déterminé, recueille de nouvelles données et les utilise pour son entraînement, comme l’illustre le schéma suivant:
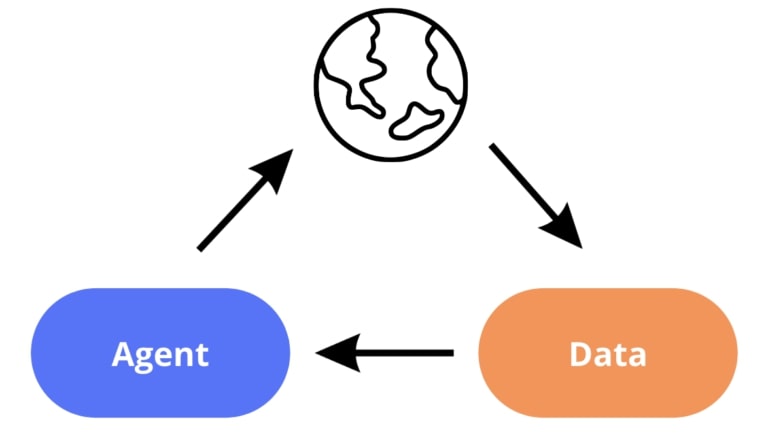
Nous définissons de manière générale le biais de primauté en apprentissage par renforcement profond par la tendance à se baser principalement sur les premières expériences, ce qui nuit au reste du processus d’apprentissage. Pour mieux comprendre les conséquences du biais de primauté, il convient de se poser deux questions relatives aux interventions expérimentales sur l’agent et sur les données. Que se passe-t-il si :
- Un agent fortement affecté par le biais de primauté tente d’apprendre de ses interactions ultérieures avec l’environnement?
- Les données recueillies par un agent fortement affecté par le biais de primauté sont reprises par un agent non entraîné pour son apprentissage?
Nous pouvons répondre à ces questions au moyen de l’algorithme Soft Actor-Critic ou SAC (Haarnoja et coll., 2018). Pour l’intervention sur l’agent, nous laissons l’agent être affecté par ses premières interactions avec l’environnement en le mettant à jour 100 000 fois pendant les 100 premières interactions avec l’environnement, comme l’illustre la figure 1. Pour l’intervention sur les données, nous permettons à un agent initialisé de manière aléatoire d’exploiter comme point de départ les données recueillies par un agent affecté par le biais de primauté (figure 2).
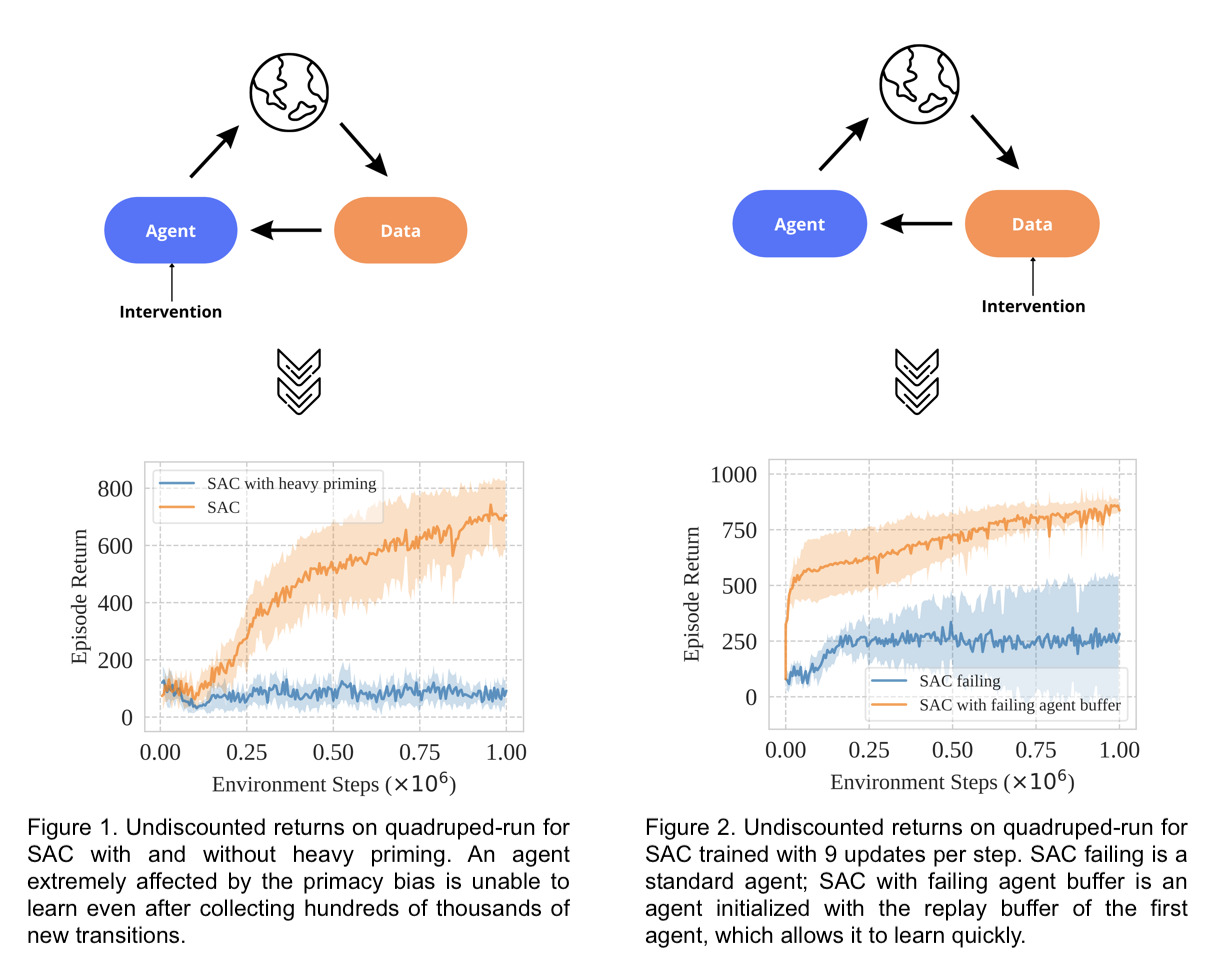
Les résultats suggèrent qu’un agent affecté par le biais de primauté est incapable d’apprendre même après avoir recueilli de nombreuses données. Cependant, un agent nouvellement initialisé peut apprendre en utilisant les données recueillies par un agent fortement affecté par le biais de primauté.
La combinaison du comportement actuel et des algorithmes d’apprentissage empêche tout apprentissage supplémentaire lors du recours à une expérience qui serait autrement suffisante. Et si un agent pouvait oublier une partie de son comportement tout en conservant son expérience?
Avez-vous essayé de le réinitialiser?
Pour plusieurs algorithmes d’apprentissage par renforcement profond, la dichotomie entre le comportement et l’expérience d’un agent est mise en œuvre par le biais d’un ou de plusieurs approximateurs de réseaux neuronaux (pour établir une fonction de valeur et/ou une politique de contrôle) et dans la mémoire de reprise (pour stocker les données recueillies).
Si l’oubli des comportements est la clé d’un apprentissage plus efficace, une stratégie étonnamment simple permet de surmonter le biais de primauté: il suffit de réinitialiser périodiquement les paramètres des dernières couches du réseau neuronal d’un agent, tout en préservant la mémoire de reprise. Nous qualifions cette stratégie de réinitialisation.
Nous avons expérimenté cette idée sur un domaine à variable discrète, en effectuant un étalonnage sur Atari 100k avec l’algorithme SPR, et sur un domaine à variable continue, en réalisant des tests sur DeepMind Control Suite (DMC) à partir d’observations proprioceptives (avec l’algorithme SAC) et d’observations d’images (avec l’algorithme DrQ). Cette stratégie de réinitialisation du réseau permet d’obtenir des améliorations substantielles des performances, évaluées selon les directives du protocole RLiable (Agarwal et coll., 2021).
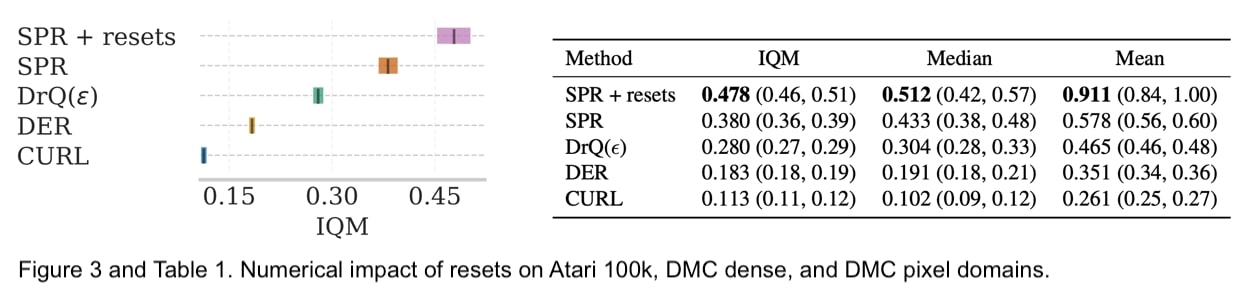
De plus, les réinitialisations permettent non seulement de surmonter le biais de primauté, mais aussi d’augmenter l’efficacité de l’échantillon en effectuant plus d’optimisations pour chaque point de données et en apprenant à partir de cibles plus bruyantes.
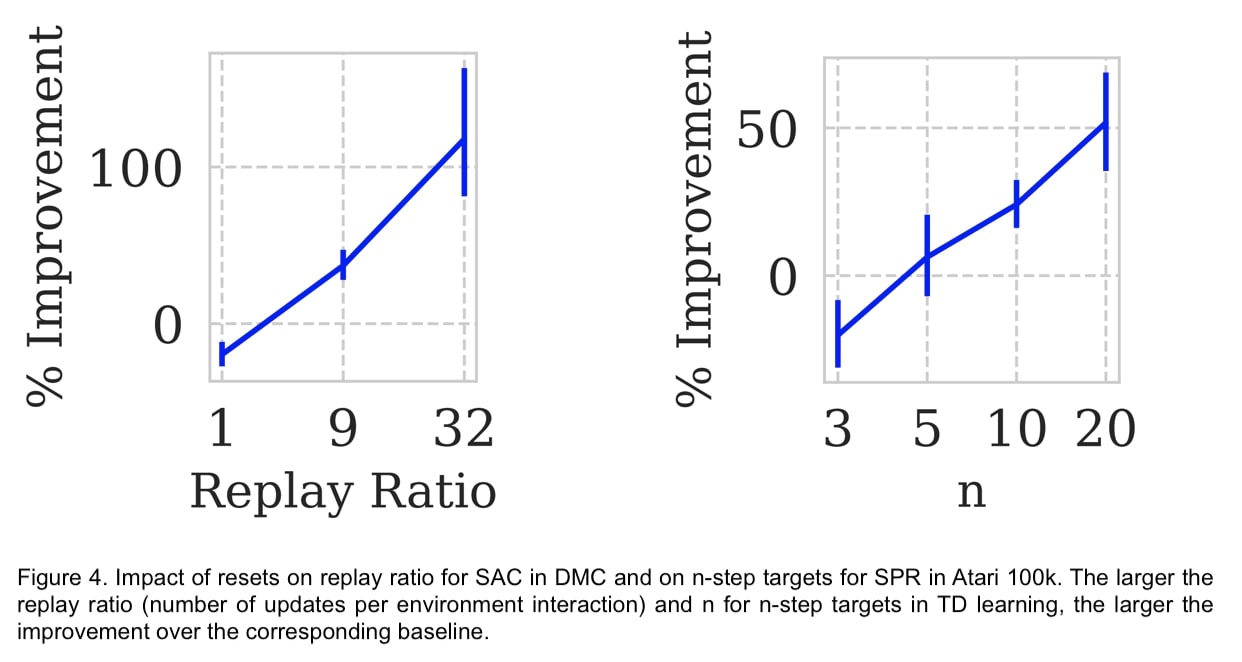
Examinons maintenant quelques exemples typiques des dynamiques d’apprentissage générées par les réinitialisations. Avec l’algorithme SAC, nous réinitialisons entièrement les réseaux à tous les 200 000 pas et analysons les performances avec 32 mises à jour des gradients à chaque pas dans l’environnement.
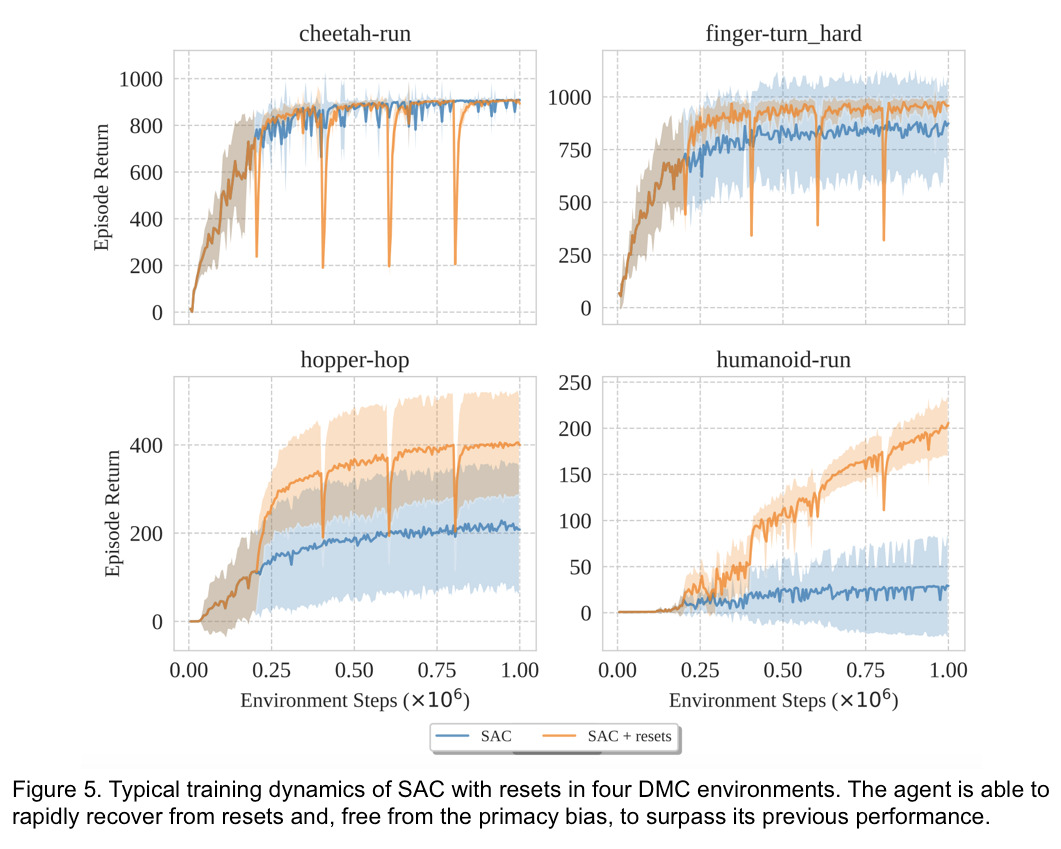
Remarquez la rapidité avec laquelle l’agent atteint et dépasse la performance précédente. Dans des environnements comme « cheetah-run » où le biais de primauté ne joue aucun rôle majeur, les réinitialisations ne présentent aucun avantage. Dans d’autres environnements plus sensibles au biais de primauté, les réinitialisations permettent à l’agent d’exploiter davantage les données disponibles, ce qui améliore à la fois l’efficacité de l’échantillon et les performances finales.
Conclusion
En établissant des liens avec les sciences cognitives et en exploitant une stratégie d’atténuation intuitive et efficace, nous avons fait un pas de plus vers la résolution du problème particulier de surapprentissage que rencontrent les agents entraînés par apprentissage par renforcement profond. Certains travaux ont récemment sensibilisé la communauté de recherche à la relation délicate entre les réseaux neuronaux et l’apprentissage par renforcement. On peut notamment mentionner les recherches sur l’entraînement des agents sur des distributions de données non stationnaires (Igl et coll., 2020), le traitement de la diminution de l’expressivité dans les réseaux neuronaux (Kumar et coll., 2020, Lyle et coll., 2022) et la gestion holistique de la séquence des problèmes de prévision en apprentissage par renforcement (Dabney et coll., 2020). Nous espérons que nos résultats paveront la voie à d’autres études visant à améliorer la compréhension et les performances des algorithmes d’apprentissage par renforcement profond.