Cognitive science has shown that humans often learn in a disproportional way from early experiences when they deal with something new (Shteingart, Neiman & Loewenstein, 2012). Consider the following example from social psychology pioneer Solomon Asch’s seminal work:
Participants received one of two sentences: “Steve is smart, diligent, critical, impulsive, and jealous.” and “Steve is jealous, impulsive, critical, diligent, and smart.” These two sentences contain the same information[…] Researchers found that the subjects evaluated Steve more positively when given the first sentence, compared with the second one.
This phenomenon is known as the primacy effect, where individuals recall primary information better than information they receive later on. This cognitive bias could lead to behaviors that are suboptimal and difficult to unlearn or improve upon when presented with further knowledge. In our new work—to be presented this July at ICML 2022—we find that deep reinforcement learning (RL) agents are susceptible to similar issues during their training. In this blog post, we dive deeper into this phenomenon and present a simple but surprisingly effective strategy to address it.
The Role of Early Experiences in Reinforcement Learning
Every deep RL agent faces a trade-off between training more aggressively on the data available so far, incurring the risk of overfitting, and being more conservative, potentially giving up on being sample-efficient. If an agent overfits earlier interactions with the environment, it enters a vicious circle of poor performance where it will collect low-quality data, making it difficult to improve the learning process and likely leading to less promising behaviors.
During learning, the agent executes actions in a given environment, collects new data from it and uses that data for training, as illustrated in the following diagram:
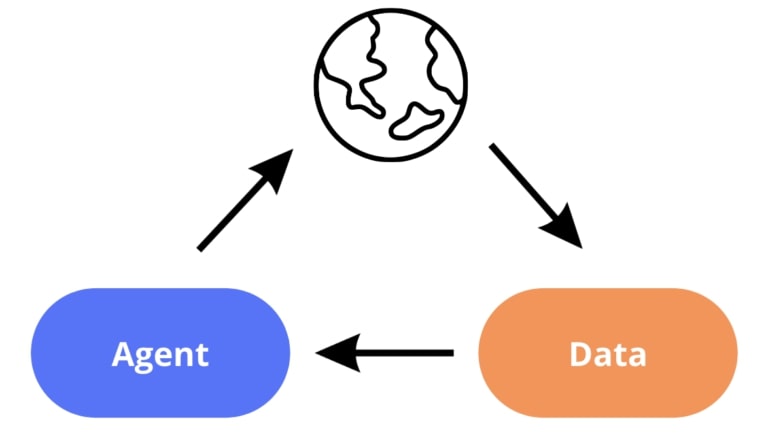
We broadly define the primary bias in deep RL as a tendency to overfit early experiences that damage the rest of the learning process. To better understand the effects of the primacy bias, let us ask two questions relating to experimental interventions on the agent and on the data. What happens if:
- An agent heavily affected by the primacy bias tries to learn from further interactions with the environment?
- The data from a heavily primed agent is used for learning by an untrained agent?
We can answer these two questions in the context of the Soft Actor-Critic algorithm (Haarnoja et al., 2018). For the agent intervention, we let the agent be primed by the early interactions it gets from the environment by updating it 100k times on the first 100 interactions, as shown in Figure 1. For the data intervention, we allow a randomly initialized agent to leverage the data collected by another primed agent as a starting point (Figure 2).
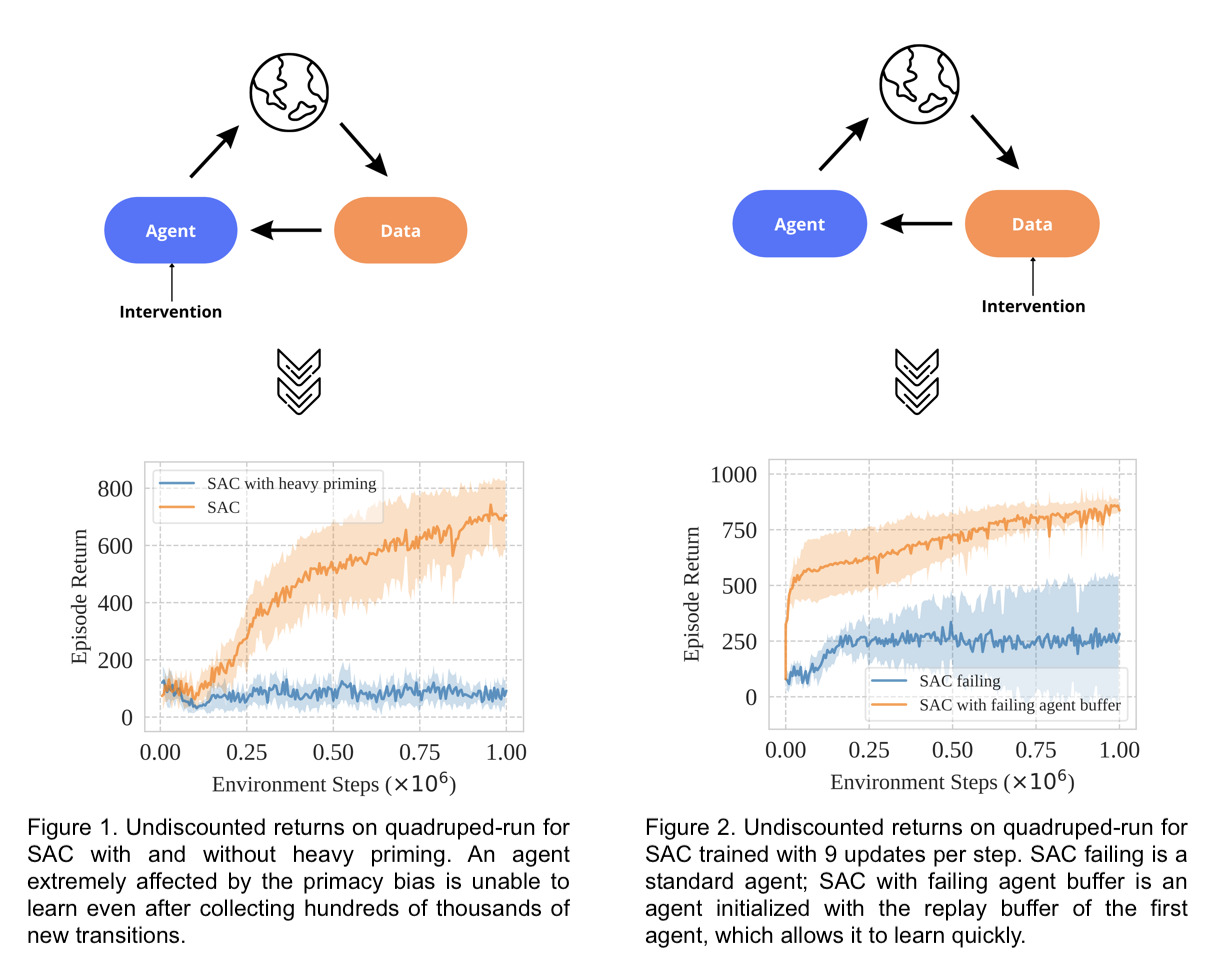
The results suggest that an agent affected by the primacy bias is unable to learn even after collecting an abundance of data. However, a newly initialized agent can learn from the collected data collected from an agent heavily affected by the primacy bias.
The combination of current behavior and learning algorithms prevents further learning when using experience that would be otherwise sufficient. What if an agent could forget part of its behavior while conserving its experience?
Have You Tried Resetting It?
In many deep RL algorithms, the dichotomy between an agent’s behavior and experience is implemented via one or more neural network approximators (responsible for a value function and/or a control policy) and a replay buffer (to store the data collected so far).
If forgetting behaviors is the key to more effective learning, overcoming the primacy bias can be achieved by a surprisingly simple strategy: given an agent’s neural network, periodically re-initialize the parameters of its last few layers while preserving the replay buffer. We refer to this strategy as resetting.
We experimented with this idea in both discrete control, benchmarking on Atari 100k with the SPR algorithm, and continuous control, testing on DeepMind Control Suite from proprioceptive observations (with the SAC algorithm) and image observations (with the DrQ algorithm). This network resetting strategy achieves substantial performance improvements, as evaluated under the guidelines of the RLiable protocol (Agarwal et al., 2021).
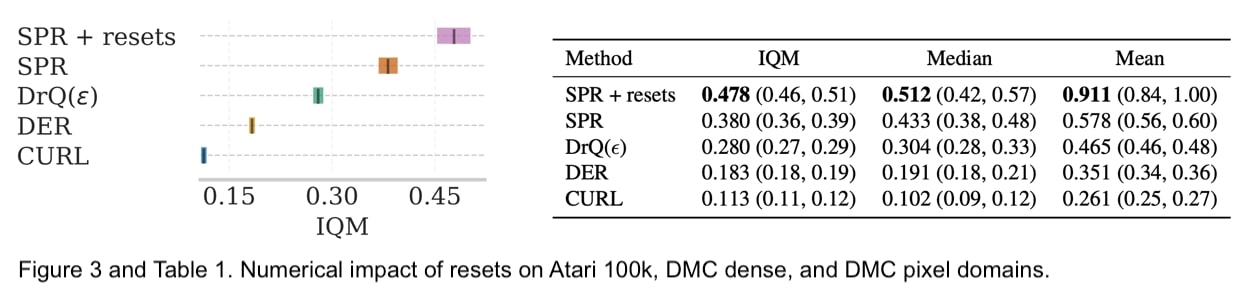
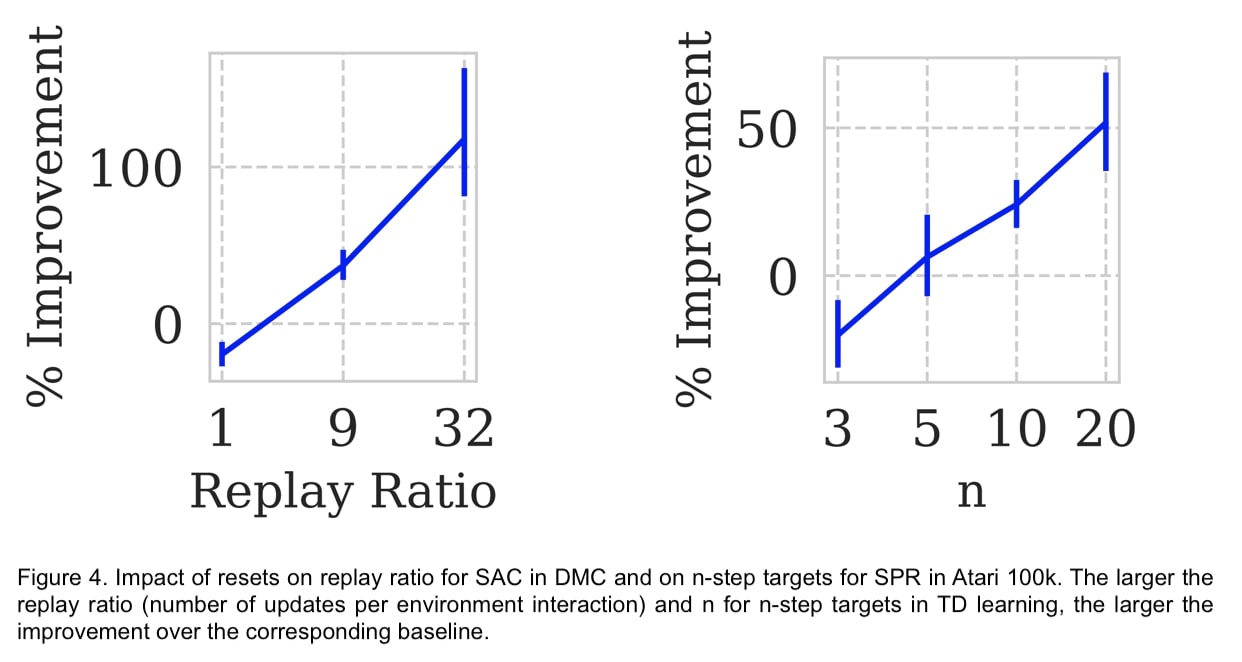
Moreover, resets allow not only overcoming the primacy bias but also boosting sample efficiency by doing more optimization per each data point and learning from noisier targets.
Let’s now look at some typical examples of learning dynamics induced by resets. With the SAC algorithm, we reset the networks entirely every 200k steps and examine the performance with 32 gradient updates per each step in the environment.
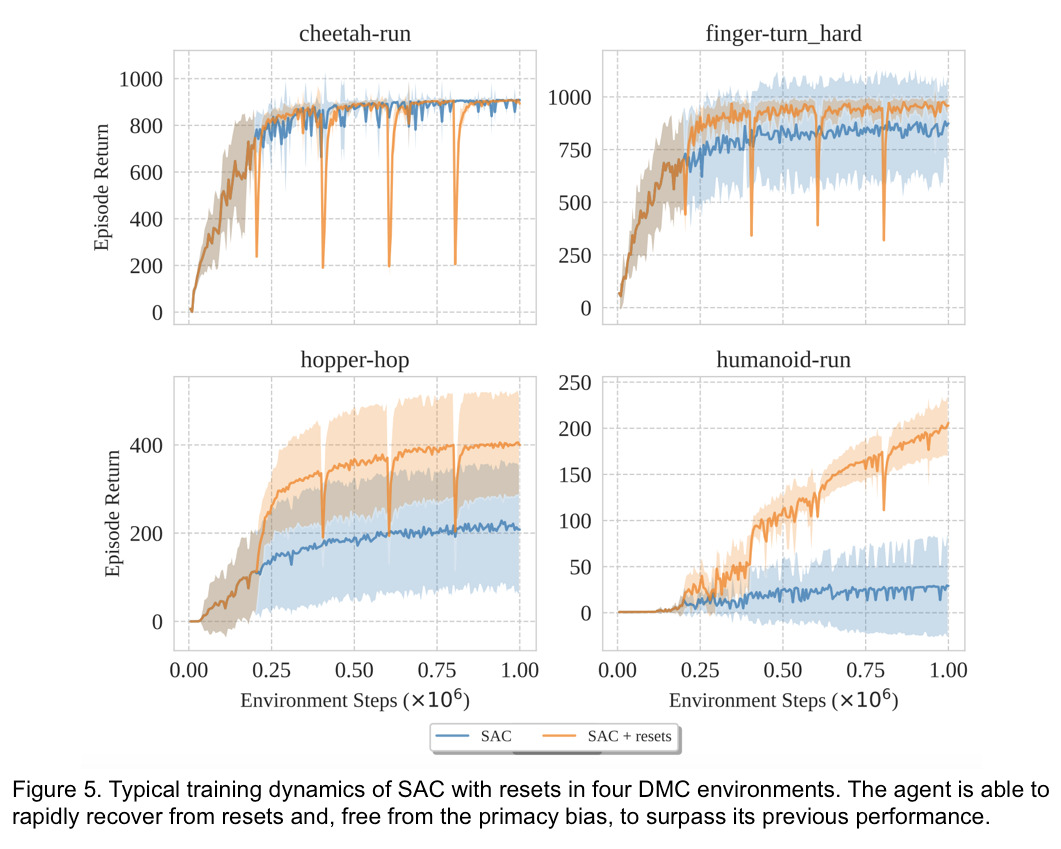
Notice how quickly the agent reaches and surpasses the previous performance. In environments like cheetah-run, in which there is no prominent effect of the primacy bias, resets provide no benefit. In other environments more susceptible to the effects of the primacy bias, resets allow the agent to exploit the available data in a better way, improving both sample efficiency and final performance.
Conclusion
We made a step towards addressing one particular overfitting challenge that deep RL agents encounter, drawing connections with cognitive science and leveraging an intuitive and effective mitigation strategy. The research community has recently become increasingly aware of the delicate relationship between neural networks and RL and has started discussing how to train agents on non-stationary distributions (Igl et al., 2020), how to deal with the decrease of expressivity in neural networks (Kumar et al., 2020, Lyle et al., 2022), and how to holistically treat the sequence of prediction problems in RL (Dabney et al., 2020). We hope that our findings will open possibilities for further studies to improve both the understanding and performance of deep reinforcement learning algorithms.