



Note de la rédaction : Cette publication est basée sur l’article ‘Deep Reinforcement Learning Policies Learn Shared Adversarial Features across MDPs’ présenté à l’AAAI 2022.
Le recours aux réseaux de neurones profonds comme approximateurs de fonctions a permis de réaliser des progrès exceptionnels dans les applications et les algorithmes d’apprentissage par renforcement. Néanmoins, nos connaissances sur la géométrie des frontières décisionnelles et sur le paysage des fonctions de perte relatives aux stratégies d’actions apprises restent assez limitées. Dans ce document, nous proposons un cadre pour enquêter sur les similarités des frontières décisionnelles et du paysage de fonctions de perte à travers les états, les PDM et les algorithmes via des directions antagonistes.
Cadre antagoniste de l’apprentissage par renforcement profond
Le cadre antagoniste repose sur une forte motivation théorique qui englobe différents niveaux de difficultés antagonistes afin de souligner les similarités du paysage de fonctions de perte entre les stratégies d’actions apprises par renforcement profond dans plusieurs PDM et avec différents algorithmes. Les résultats dans notre article soutiennent l’hypothèse selon laquelle les caractéristiques non robustes sont partagées à travers différents environnements d’entraînement de stratégies d’actions par apprentissage par renforcement profond.
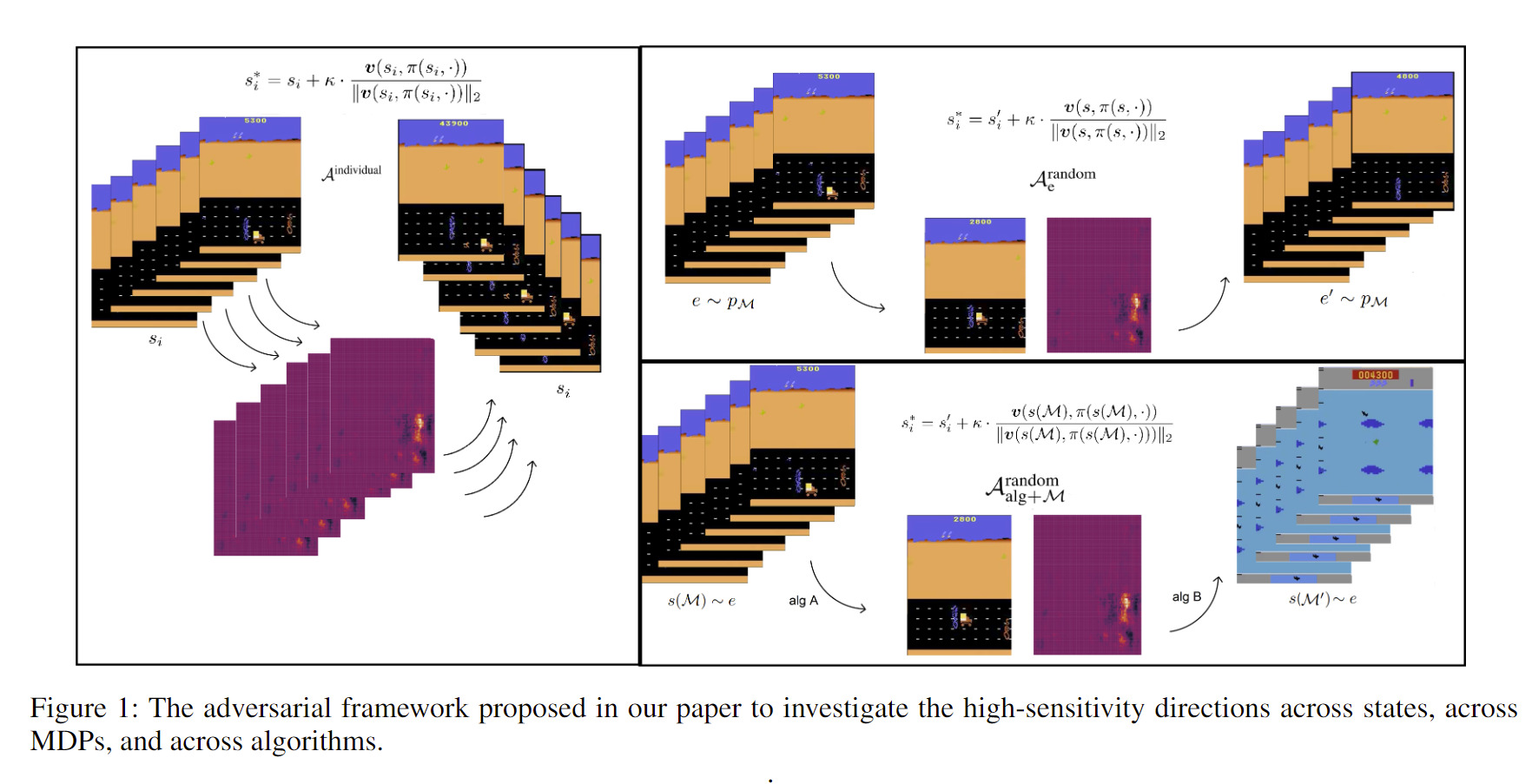
Nous recherchons avant tout les réponses aux questions suivantes:
(i) Existe-t-il une corrélation entre les directions à haute sensibilité des stratégies d’actions entraînées au sein des divers PDM?
(ii) Les stratégies d’actions obtenues grâce à des méthodes d’apprentissage par renforcement profond combinées à des méthodes d’apprentissage antagoniste de pointe héritent-elles de directions à haute sensibilité similaires aux stratégies obtenues à l’aide de méthodes standard?
(iii) Les caractéristiques non robustes existent-elles intrinsèquement dans les environnements d’apprentissage par renforcement profond?
Vulnérabilités des techniques d’apprentissage antagonistes certifiées
Nos expériences montrent que les stratégies d’actions apprises par renforcement profond et de manière antagoniste mènent à l’utilisation de caractéristiques non robustes qui sont très sensibles dans certaines directions. Ainsi, les caractéristiques non robustes ne sont pas seulement partagées à travers les états et les PDM, mais aussi à travers différents algorithmes d’apprentissage. Il est assez préoccupant de constater que les algorithmes destinés à résoudre des problèmes de vulnérabilités et qui fonctionnent de manière antagoniste continuent de mener à l’utilisation de caractéristiques non robustes similaires à celles obtenues par apprentissage par renforcement profond standard. Cette réalité soulève non seulement de sérieuses inquiétudes en matière de sécurité pour les modèles antagonistes certifiés, mais aussi un nouveau problème de recherche dans les environnements d’apprentissage.
Similarités perceptives et directions antagonistes à travers les PDM
Des similarités perceptives des observations d’états aux mesures prises compte tenu des directions antagonistes introduites dans les observations des stratégies d’actions apprises par renforcement profond, nous consacrons plusieurs sections pour enquêter sur les raisons sous-jacentes et les incidences du phénomène de directions antagonistes dans le cadre des stratégies d’apprentissage par renforcement profond utilisées dans plusieurs PDM et avec différents algorithmes.
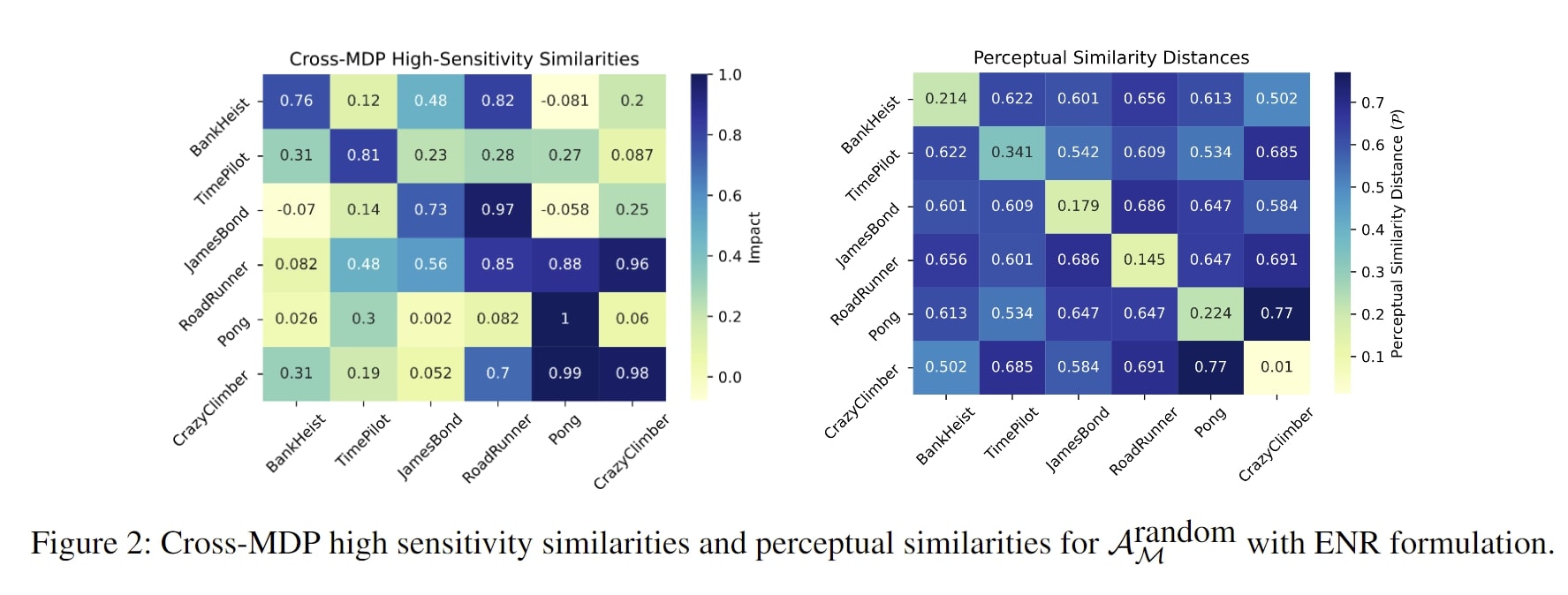
Dans l’une des sections de notre document dédiées à ces raisons sous-jacentes, la Figure 2 signale notamment les impacts des directions à haute sensibilité à travers les PDM et les distances de similarités perceptives entre plusieurs observations d’état de PDM. D’après ces conclusions, la similarité perceptive des observations d’état pour deux PDM n’est pas liée au niveau de dommages que les directions antagonistes (spécialement calculées pour un PDM) peuvent occasionner sur la performance de la stratégie d’actions lors des transferts entre les PDM.
Discussion
Notre article souligne que les vulnérabilités des stratégies d’actions obtenues par apprentissage par renforcement énoncé ne représentent que la partie visible de l’iceberg. Ce pouvoir antagoniste, susceptible de faire émerger ces vulnérabilités et ce manque de robustesse, est considérablement plus faible que les hypothèses et anticipations énoncées à ce stade. Qui plus est, notre document révèle les propriétés fondamentales de la dynamique d’apprentissage et des environnements utilisés dans l’apprentissage par renforcement profond. Il pose également des questions directes à élucider pour élaborer des stratégies d’apprentissage par renforcement profond, fiables et robustes.
Pour en savoir plus
Si l’apprentissage antagoniste par renforcement profond vous intéresse, reportez-vous à [1,2,3,4] pour plus d’informations sur les vulnérabilités de l’apprentissage antagoniste et sur les moyens d’identifier le manque de robustesse dans les stratégies d’apprentissage par renforcement profond.
Références
[1] Adversarial Robust Deep Reinforcement Learning Requires Redefining Robustness. AAAI Conference on Artificial Intelligence, 2023.
[2] Ezgi Korkmaz. Investigating Vulnerabilities of Deep Neural Policies. Conference on Uncertainty in Artificial Intelligence (UAI), Proceedings of Machine Learning Research (PMLR), 2021.
[3] Ezgi Korkmaz. Deep Reinforcement Learning Policies Learn Shared Adversarial Features Across MDPs. AAAI Conference on Artificial Intelligence, 2022.
[4] Ezgi Korkmaz. Inaccuracy of State-Action Value Function For Non-Optimal Actions in Adversarially Trained Deep Neural Policies. IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPR) 2021. [Présentation orale]
[5] Ezgi Korkmaz. Nesterov Momentum Adversarial Perturbations in the Deep Reinforcement Learning Domain. International Conference on Machine Learning (ICML) Inductive Biases, Invariances and Generalization in Reinforcement Learning Workshop, 2020.
Site Web: https://adversarialreinforcementlearning.github.io/
Publication officielle: https://ojs.aaai.org/index.php/AAAI/article/view/20684
Informations sur l'auteur: https://ezgikorkmaz.github.io/
Citation(BibTex)
@article{korkmaz22aaai,
title={Deep Reinforcement Learning Policies Learn Shared Adversarial Features Across MDPs},
author={Ezgi Korkmaz},
journal={AAAI Conference on Artificial Intelligence},
year={2022}
}


