



Editor’s Note: This blog post is based on the paper ‘Deep Reinforcement Learning Policies Learn Shared Adversarial Features across MDPs’ presented in AAAI 2022.
The use of deep neural networks as function approximators has led to striking progress for reinforcement learning algorithms and applications. Yet the knowledge we have on decision boundary geometry and the loss landscape of neural policies is still quite limited. In this paper, we propose a framework dedicated to investigating the decision boundary and loss landscape similarities across states, across MDPs and across algorithms via adversarial directions.
Deep Reinforcement Learning Adversarial Framework
The adversarial framework is founded with strong theoretical motivation that encapsulates levels of varying adversarial difficulties to illuminate the loss landscape similarities between deep reinforcement learning policies trained in different MDPs and with different algorithms. The results in our paper support the hypothesis that non-robust features are shared across training environments of deep reinforcement learning policies.
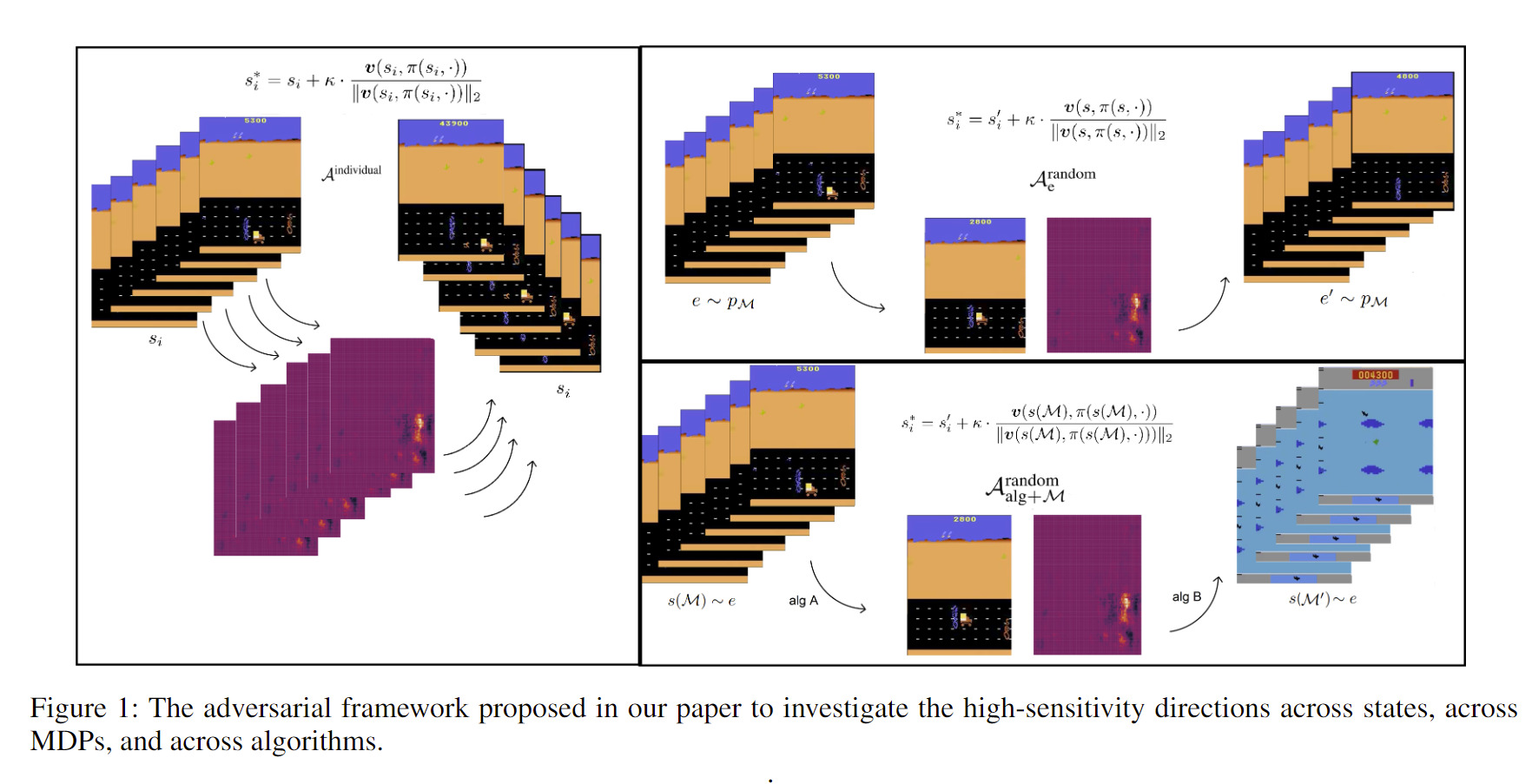
Mainly, in our paper we sought answers for the following questions:
(i) Is there any correlation between high-sensitivity directions of deep neural policies trained in different MDPs?
(ii) Do state-of-the-art adversarially trained deep reinforcement learning policies inherit similar high-sensitivity directions to vanilla trained deep reinforcement learning policies?
(iii) Do non-robust features intrinsically exist in the deep reinforcement learning training environments?
Revealing the Vulnerabilities of Certified Adversarial Training Techniques
In our experiments we show that the state-of-the-art adversarially trained deep reinforcement learning policies learn similar non-robust features which carry high sensitivity towards certain directions. This shows that non-robust features are not only shared across states and across MDPs, but also shared across different training algorithms. While this reveals the vulnerabilities of certified robust deep reinforcement learning policies towards black-box adversaries, it is quite concerning that algorithms specifically focused on solving adversarial vulnerability problems are still learning similar non-robust features as vanilla deep reinforcement learning training algorithms. This fact not only presents serious security concerns for certified adversarially trained models, but it posits a new research problem on the environments in which we train.
Perceptual Similarities and Cross-MDP Adversarial Directions
From perceptual similarities of the state observations, to the actions executed due to the adversarial directions introduced to the deep reinforcement learning policy’s observations, we dedicate multiple sections investigating the underlying reasons and implications of the phenomena of shared adversarial directions within deep reinforcement learning policies trained in different MDPs and with different algorithms.
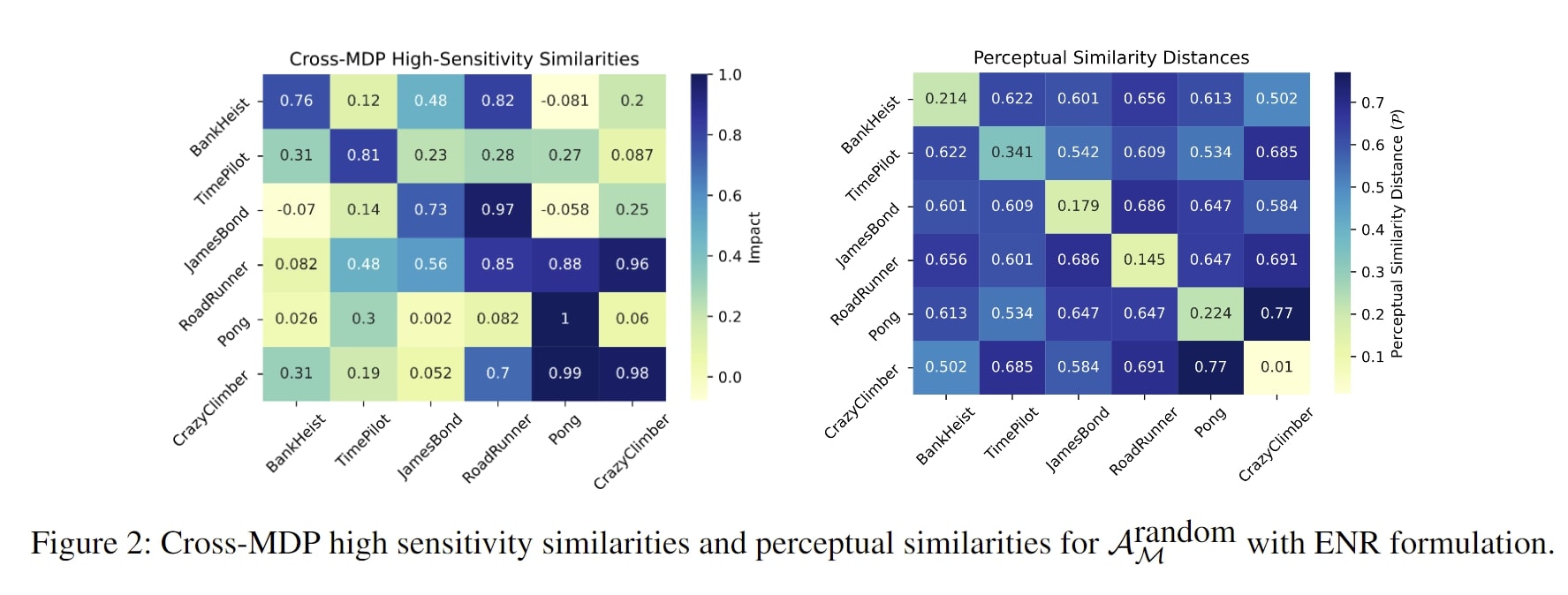
In particular, Figure 2, from one of the sections in our paper that is dedicated to investigating these underlying reasons, reports the impacts of the cross MDP high sensitivity directions and the perceptual similarity distances between different MDP state observations. These results demonstrate that the perceptual similarity of the state observations of a pair of MDPs are uncorrelated with the level of damage that adversarial directions that are specifically computed for a particular MDP can cause on the policy performance when transferred between MDPs.
Discussion
Our paper highlights that the vulnerabilities of reinforcement learning policies that have been discussed so far are just the tip of the iceberg. The power level of an adversary that can bring these vulnerabilities and non-robustness to the surface is substantially lower than what has been thus far conjectured and anticipated. More intriguingly, our paper reveals fundamental properties of the training dynamics and the environments used in deep reinforcement learning training, and poses straightforward questions that need to be answered on the path towards building robust and reliable deep reinforcement learning policies.
Further Interest
If you are interested in adversarial deep reinforcement learning see more in [1,2,3,4,5] for the further vulnerabilities of adversarial training and concrete methods to surface the non-robustness of deep reinforcement learning policies.
References
[1] Adversarial Robust Deep Reinforcement Learning Requires Redefining Robustness. AAAI Conference on Artificial Intelligence, 2023.
[2] Ezgi Korkmaz. Investigating Vulnerabilities of Deep Neural Policies. Conference on Uncertainty in Artificial Intelligence (UAI), Proceedings of Machine Learning Research (PMLR), 2021.
[3] Ezgi Korkmaz. Deep Reinforcement Learning Policies Learn Shared Adversarial Features Across MDPs. AAAI Conference on Artificial Intelligence, 2022.
[4] Ezgi Korkmaz. Inaccuracy of State-Action Value Function For Non-Optimal Actions in Adversarially Trained Deep Neural Policies. IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPR) 2021. [Oral Presentation]
[5] Ezgi Korkmaz. Nesterov Momentum Adversarial Perturbations in the Deep Reinforcement Learning Domain. International Conference on Machine Learning (ICML) Inductive Biases, Invariances and Generalization in Reinforcement Learning Workshop, 2020.
Website: https://adversarialreinforcementlearning.github.io/
Official Publication: https://ojs.aaai.org/index.php/AAAI/article/view/20684
Author Information: https://ezgikorkmaz.github.io/
Citation(BibTex)
@article{korkmaz22aaai,
title={Deep Reinforcement Learning Policies Learn Shared Adversarial Features Across MDPs},
author={Ezgi Korkmaz},
journal={AAAI Conference on Artificial Intelligence},
year={2022}
}


