Editor’s Note: This article was originally published on Ubisoft Montréal’s Tech Blog on August 12, 2022, and is based on work first published at the International Conference on Machine Learning (ICML) 2022.
Paper: https://proceedings.mlr.press/v162/roy22a
Code: https://github.com/ubisoft/directbehaviorspecification
Reinforcement Learning is becoming an increasingly popular tool employed in the video game industry, often in the perspective of automatic testing such as verifying reachability, character balancing, etc. The wide applicability of Reinforcement Learning lies in the fact that it requires a lower level of supervision: it is often easier to specify what to do (RL) than how it should be done (supervised learning).
However, in complex video games, there are several requirements that an NPC (non-player character) should follow. Combining these requirements into a single reward function can lead to unforeseen behaviors. These requirements are especially important if these systems are to be used in front of real-life players. For example, in the video below, the agent successfully learns to navigate in a complex map but behaves somewhat un-naturally by jumping even when it is not necessary to or by frequently oscillating its view:

In this other example, an agent trained to play For Honor learns to run away in order to better ambush its adversary; a behavior that works in this particular case by finding a weak-point of the hardcoded AI but does not correspond to the intent of the designer:

The emergence of these unforeseen behaviors is not a bug in itself: the agent does successfully maximise the reward function that it has been given. The problem is that this reward function has been mis-specified i.e. it does not always correctly capture all of the requirements that the user cares about. In fact, the more complex the desired behavior is, the more difficult it becomes to design a good reward function that leads to that behavior.
A more direct approach to behavior specification
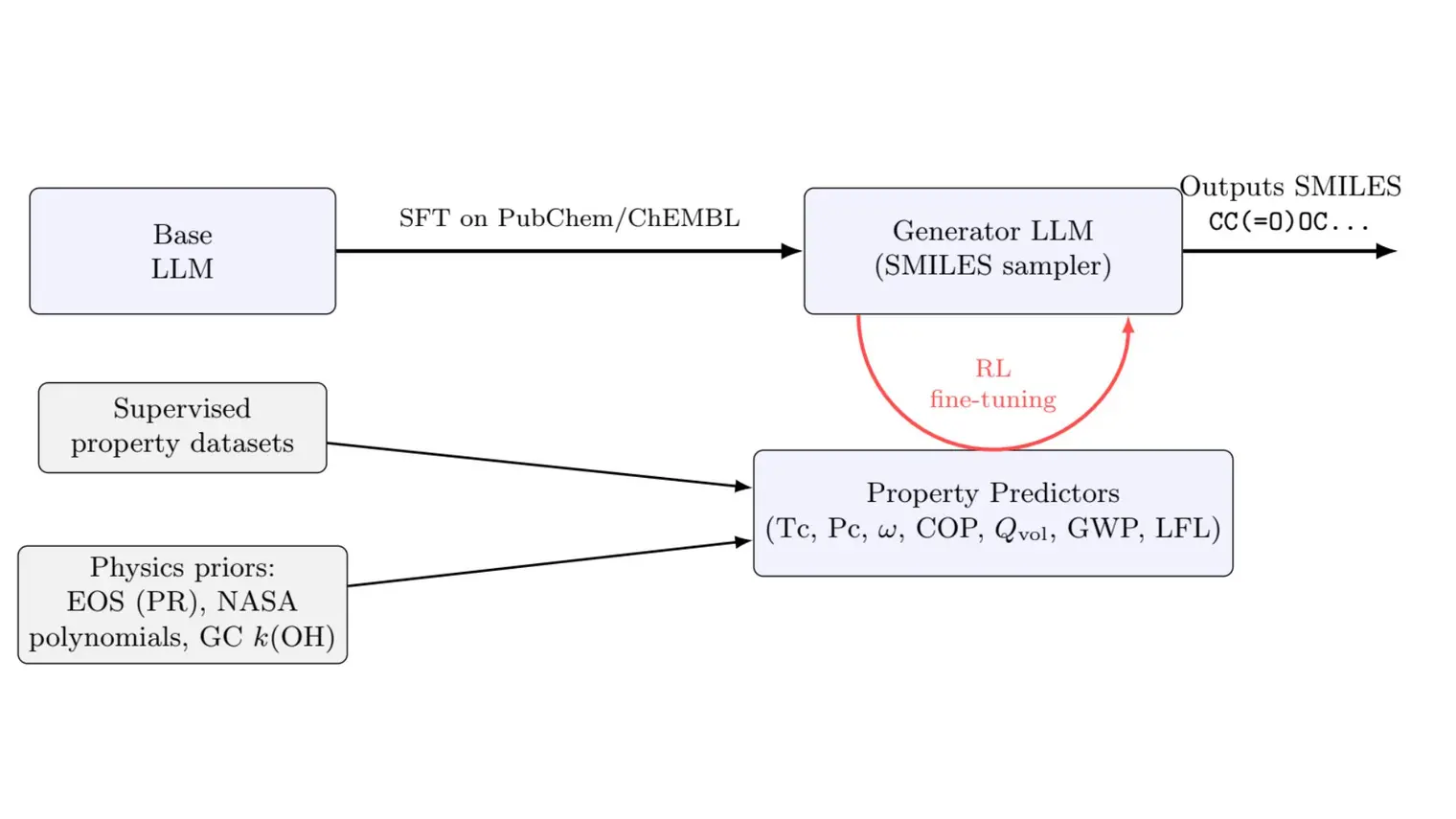
When designing a reward function, ML practitioners often sum together a number of behavioral components that are deemed important for their application case:
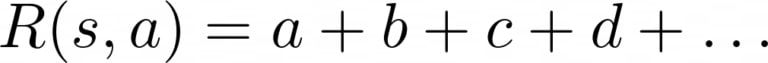
The problem with summing several behavioral components into a single reward function is that choosing the relative scale of these components is often counter-intuitive. For example, say we wanted our agent to be able to navigate without jumping excessively – how much of a penalty should we attribute to jumping?
On the other hand, automating the process by searching the space of reward coefficients is very inefficient as the space of possible combinations grows exponentially with the number of coefficients to tune.
One solution to automatically find the correct coefficient values is to formulate the additional behavioral preferences as hard constraints, and using Lagrangian methods to find a reasonable solution to this constrained optimisation problem. More formally, a Constrained Markov Decision Process consists of one main reward function R to maximise and K additional constraints to be enforced:
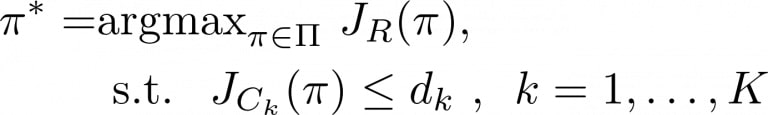
However, this CMDP formulation does not fully solve the problem as we still need to define the thresholds and cost-functions. Moreover, the regular Lagrangian method can become unstable and inefficient when enforcing several constraints. In this work we present a framework for Direct Behavior Specification that relies on the following modifications.
1. Restricting the family of CMDPs to indicator cost functions
An efficient design choice to ease the specification task is to only implement the cost functions for the constraints as indicator functions that some event has occurred in a given state-action pair:
Such a function is usually straightforward to implement. It only assumes that we can detect the behavior that we seek to enforce! Importantly, it comes with the very useful property that the expected discounted sum of an indicator function can be interpreted as the probability that the agent exhibits this behavior, rescaled by some normalisation constant Z:
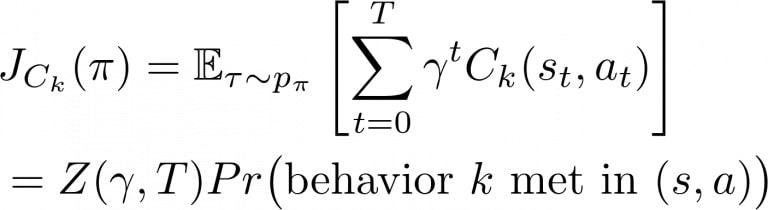
We can easily define the thresholds for such constraints by simply picking the desired probability of occurrence of that behavior (between 0 and 1).
Recall that in our previous use-case we wanted to limit jumping while navigating. Using this framework, we could for example set our threshold to jumping to be 10% – which will allow the agent to jump when it absolutely needs to, but not to jump excessively.
2. Normalised Lagrange multipliers
One problem with the regular Lagrangian approach is that the multipliers of constraints that are unsatisfied will keep increasing until the agent finally finds a way keep them in check. It is important to maintain the ability of any of the Lagrange multiplier to become arbitrarily larger than the scale of the reward function to be guaranteed that the agent will eventually start focusing on satisfying these constraints. It does however lead to instabilities in the learning dynamics when these multipliers are allowed to increase for too long. This can occur in the case of constraints that are impossible to satisfy as we simulate here (more details in the paper):
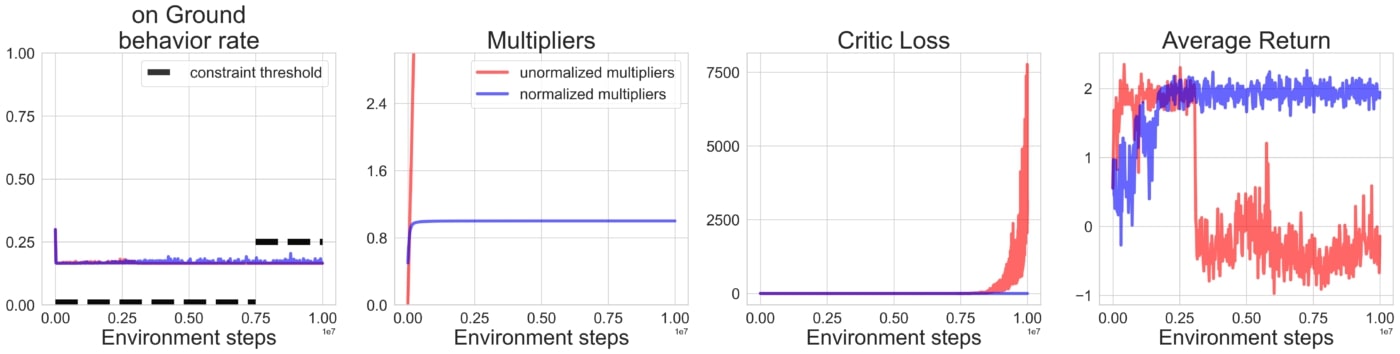
A simple solution is to normalise the multipliers by feeding them to a softmax layer before applying them to the Lagrangian function. In this way, the constraints can still end up dominating the policy updates while keeping the step size bounded.
3. Bootstrap constraint
Finally, in the presence of several constraints, the space of feasible policies can become very difficult to navigate and even contain completely disconnected feasible regions. This can prevent the agent from progressing on the main task and remaining stuck in low-performing local optima.
To circumvent this issue we propose to add to the constraint set a sparse description of the task to accomplish, which will bootstrap the learning of the main task while the agent is still looking for a feasible policy. The optimisation problem becomes:
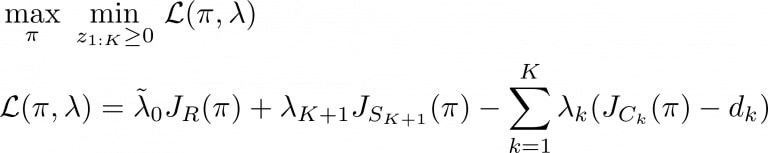
The multiplier of the main reward function is set to be the multiplier of the bootstrap constraint when the agent is still performing poorly on the task, and to the complementary of all of the constraint multipliers otherwise:
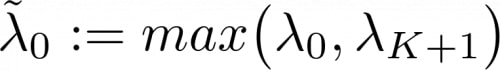
Results
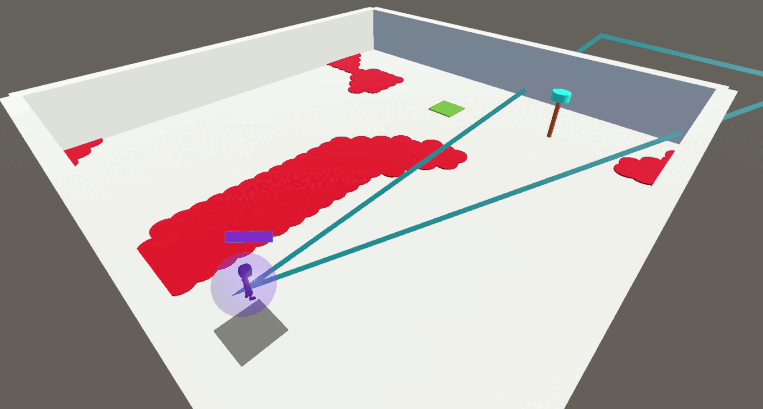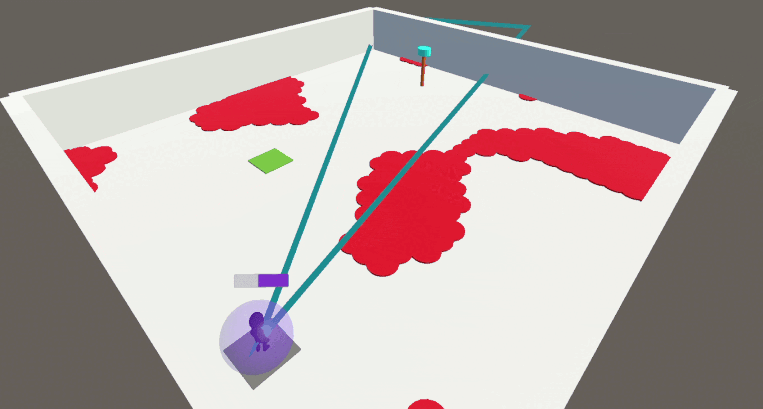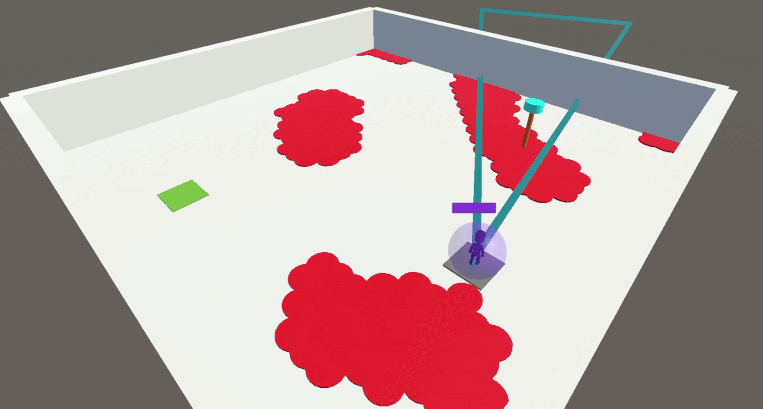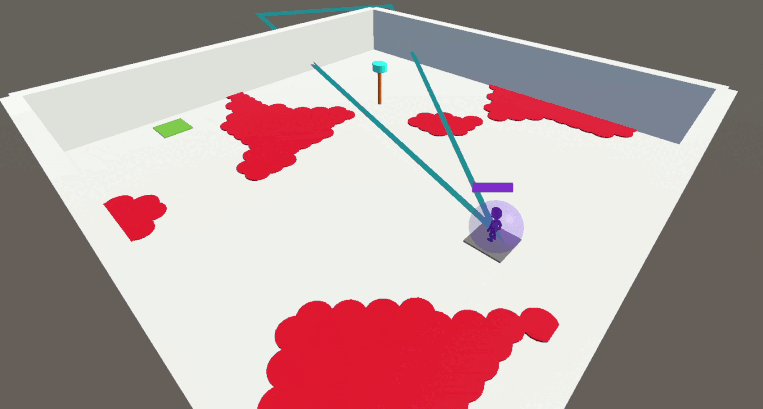
We first evaluate this framework in the Arena environment. In the Arena, the agent must learn to navigate to its goal while satisfying up to 5 behavioral constraints:
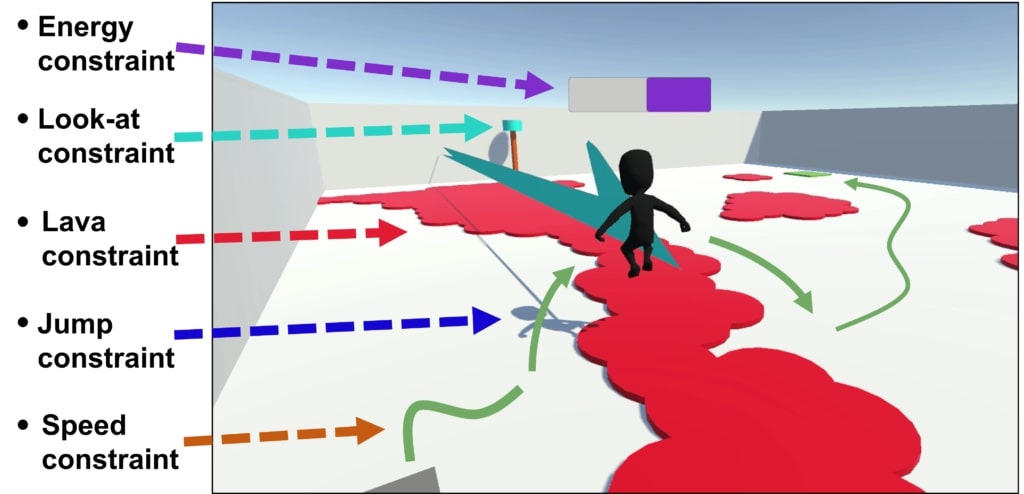
If we simply train an agent on the main task without enforcing any constraint, the problem becomes easy to solve but the agent completely disregards the designers preferences by stepping into lava, running out of energy and so on:

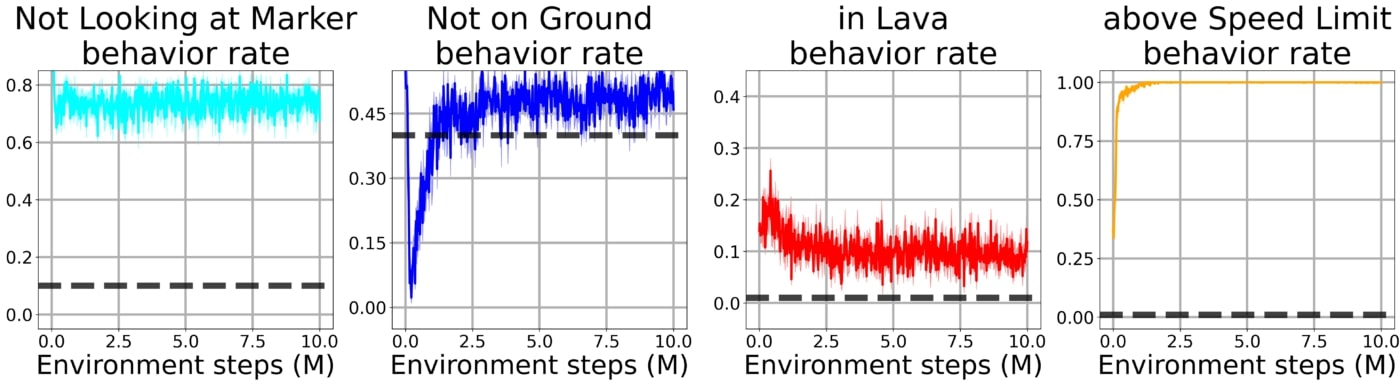
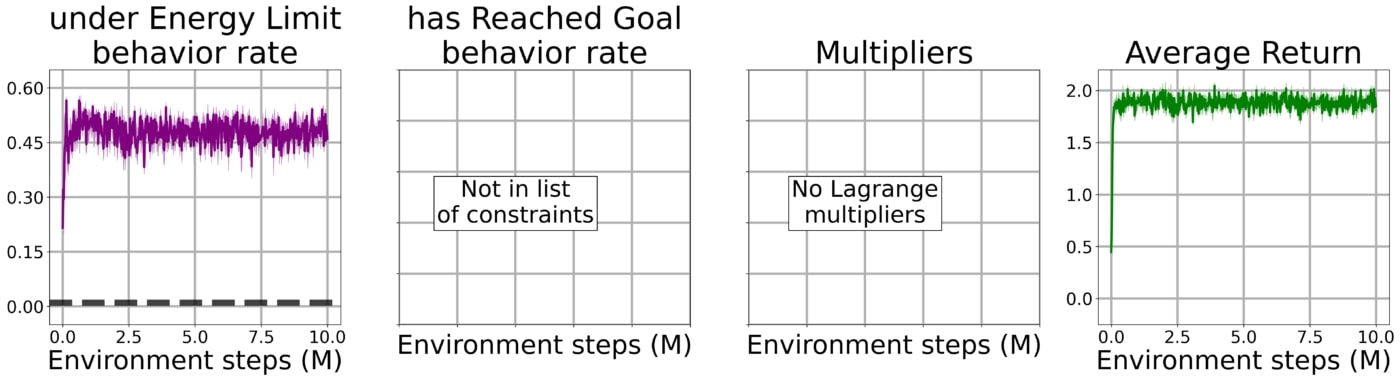
When enforcing the constraints using a Lagrangian approach, the agent adopts an overly conservative policy to avoid violating any of the constraint and thus does not learn to reach its goal.
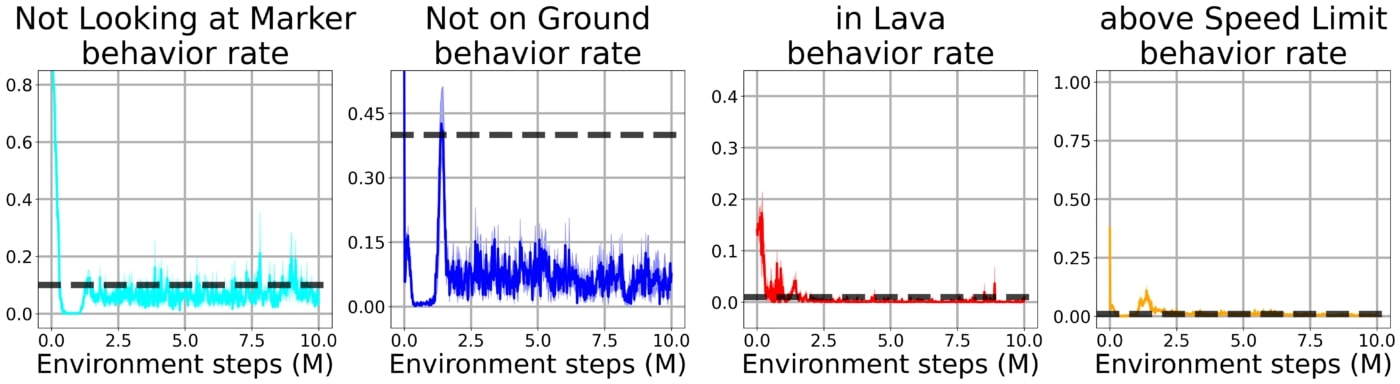
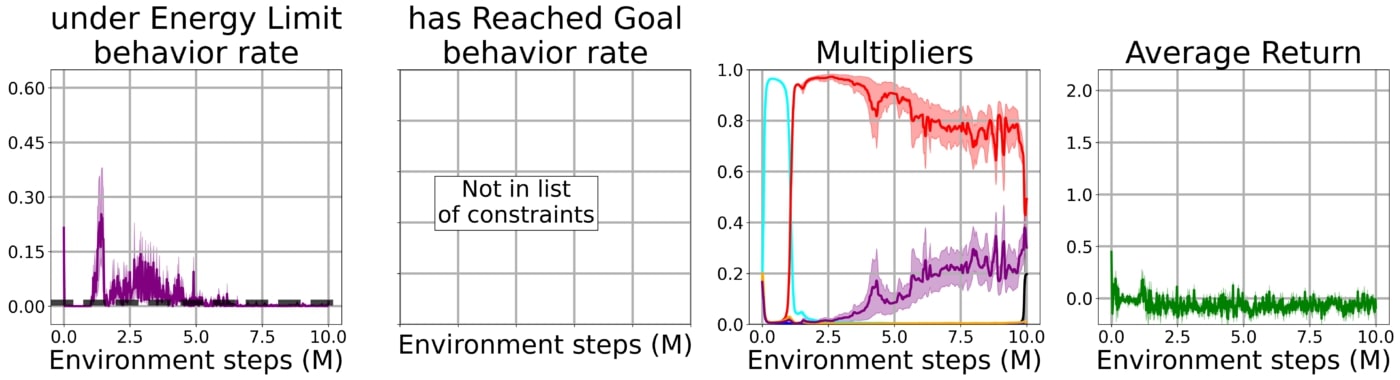
Using our method with the bootstrap constraint, the agent quickly learns to solve the task while being subject to all of the constraints simultaneously.

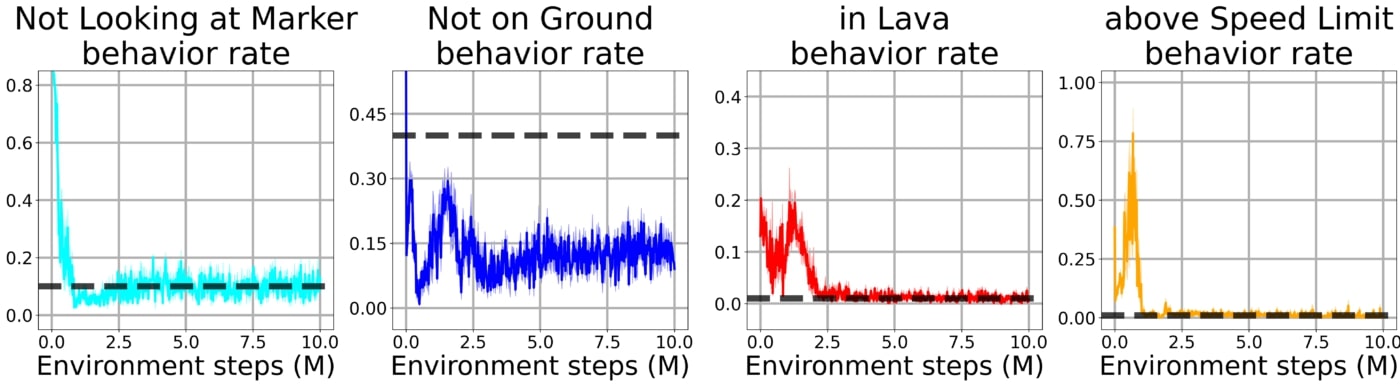
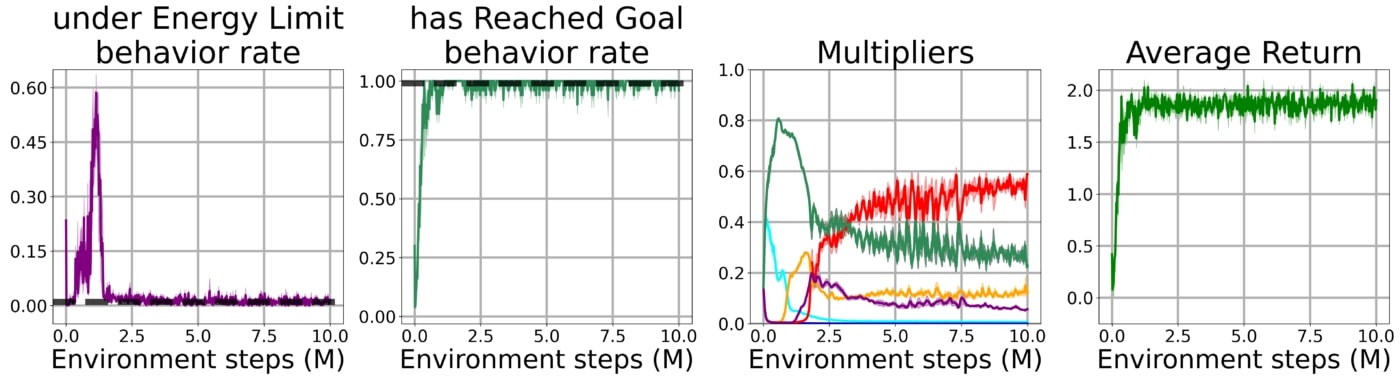
We also verify that this method scales to more complex problems by evaluating it in the OpenWorld environment. Contrarily to the Arena environment, this world now represents a 3D navigation task incorporating features such as rough terrain, buildings and jump pads:
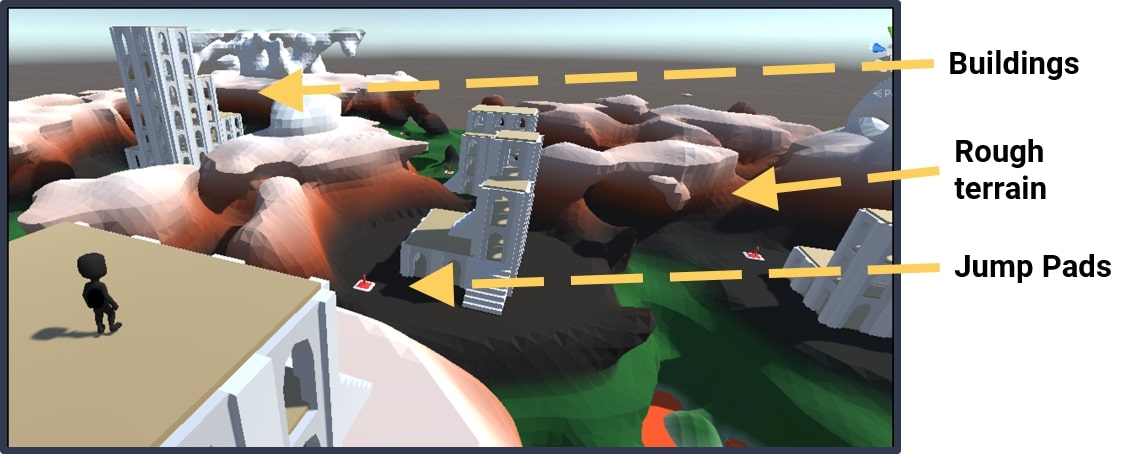
Without any modification to the Lagrangian wrapper hyperparameters, the agent is again able to learn to solve the task while respecting the constraints showing that this method can be used for very complex control tasks.

Conclusion
This work is a first step into building a better and faster development cycle for applying RL in modern video games. By allowing end users to more intuitively interact with the problem specification interface, and a specification framework that more reliably leads to the expected behavior, we can dramatically reduce the necessary amount of effort, compute and time to incorporate NPCs trained using reinforcement learning.
Bibtex
@InProceedings{pmlr-v162-roy22a,
title = {Direct Behavior Specification via Constrained Reinforcement Learning},
author = {Roy, Julien and Girgis, Roger and Romoff, Joshua and Bacon, Pierre-Luc and Pal, Chris J},
booktitle = {Proceedings of the 39th International Conference on Machine Learning},
pages = {18828–18843},
year = {2022},
volume = {162},
publisher = {PMLR}
}