Proceedings of the Neural Information Processing Systems
![[Figure 1: Additive decoders allow the generation of novel images never seen during training via Cartesian-product extrapolation. Purple regions correspond to latents/observations seen during training. The blue regions correspond to the Cartesian-product extension. The middle set is the manifold of images of circles. In this example, the learner never saw both circles high, but these can be generated nevertheless, thanks to the additive nature of the scene.]](/sites/default/files/inline-images/blogue%20additive%20decoders.jpeg)
Editor's note: This paper was accepted as an oral presentation at NeurIPS 2023.
Motivation
Object-centric representation learning (OCRL) [1, 2] aims to learn a representation where the information about different objects from a scene is encoded separately. This enables reasoning from low-level perceptual data like images, videos, etc., by learning structured representations that have the potential to improve the robustness and systematic generalization of vision systems. While several segmentation approaches utilize supervision, there is a growing interest in unsupervised learning of object-centric representations that utilize a vast amount of unlabeled image data.
![[Figure 2: Visualization of the slot renderings and how they bind to a particular object from Slot Attention.]](/sites/default/files/inline-images/GAmVi5PXcAAt0no-scaled-e1710169469858-1024x276.jpeg)
A prominent approach to achieve this is to train an encoder and decoder to reconstruct the images. For example, Slot Attention [2] learns a set of slots (representations) where each slot is expected to reconstruct a specific object, as shown in the image above. These approaches have shown impressive results empirically, but the exact reason why they disentangle objects without supervision needs to be better understood. In this work, we offer a theoretical explanation for this phenomenon by proving disentanglement and extrapolation guarantees of additive decoders, a simple architecture that is similar to object-centric decoders.
Provable Disentanglement and Extrapolation with Additive Decoders
![[Figure 3: Illustrating the main assumption of the additive decoder in our data generation process.]](/sites/default/files/inline-images/GAmWq-2WEAAAIw0-scaled-e1710168579912-1024x300.jpeg)
The model architecture consists of an encoder that outputs a compressed latent representation of the image, which is then partitioned into blocks. These latent blocks are then transformed back into the image space via a block-specific decoder. The resulting block-specific images are added together to obtain the final output image, which is used to compute the reconstruction loss for training. Additive decoders are well-suited for images that can be decomposed into a sum of images corresponding to different objects. Note that additive decoders are not expressive enough to model occlusion, i.e. when different objects overlap.
Disentanglement
![[Figure 4: Depicting the intuition behind block disentanglement, such that rendering each latent block leads to a unique object.]](/sites/default/files/inline-images/GAmYmtlWsAEOfLV.jpeg)
If, after training the additive decoder model, each latent block’s decoding corresponds to a unique object, then the model is said to have learned disentangled representations. Otherwise, we say the model has learned entangled representations, as shown in the image above. Our first contribution is to theoretically show that the additive decoders that achieve perfect reconstructions will have disentangled (object) representations if the ground-truth image generation process is also additive and sufficiently non-linear. More details regarding the assumptions and the proof are provided in the paper. Also, in contrast to several prior works on theoretical guarantees for disentanglement, we allow for dependencies between the latent blocks and they can have an almost arbitrarily shaped support as well.
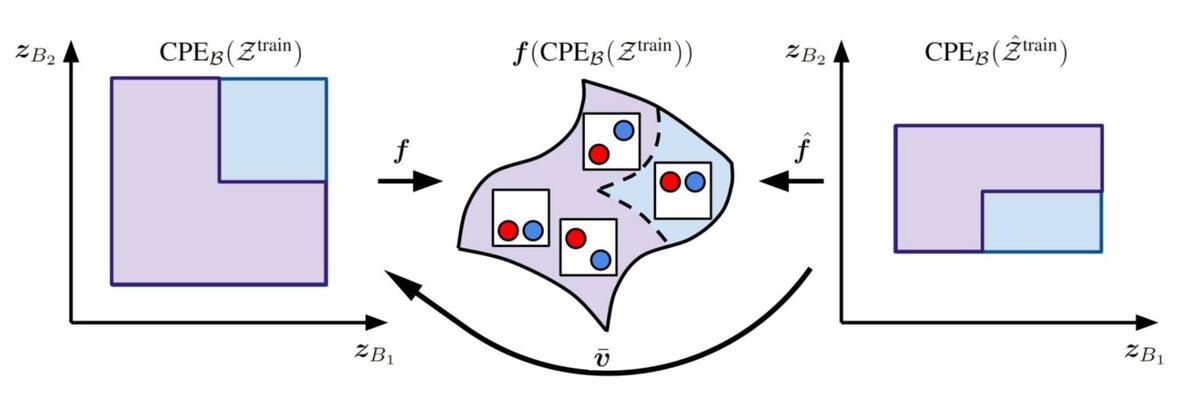
Cartesian-Product Extrapolation
![[Figure 5: Illustration of the cartesian product extrapolation, where the joint support changes while the marginal support remains the same.]](/sites/default/files/inline-images/Capture-decran-le-2024-03-11-a-10.55.09-1024x421.png)
Our second contribution is to prove that additive decoders can perform compositional generalization. Compositionality is an important aspect of human cognition that enables us to extrapolate our understanding to novel scenarios. For example, we can imagine what a blue apple would look like despite having seen only red apples. But to formally define this task from a learning perspective, we consider the setup as shown in the image above. Given the L-shaped support of the latent distribution of objects during training, can we extrapolate to the cartesian product (full square) of the support of the latent distribution of objects? We formally prove that the learned additive decoder not only disentangles objects on the training support but also on the missing extrapolated region!
Experiments
![[Figure 6: Depicting the support of the ScalarLatents dataset, where the circles move along the y-axis and we remove all images where both the circles have high y-coordinate.]](/sites/default/files/inline-images/Capture-decran-le-2024-03-11-a-10.54.59-768x411.jpg)
For empirical validation of the disentanglement and extrapolation properties of additive decoders, we experiment with the moving circles dataset, as shown in Figure 6. Each image consists of two circles that are allowed to move only along the y-axis, hence we train an additive decoder model with the latent dimension of one per block. Further, we remove the images from the training dataset in which both circles appear in the upper half of the image, which results in the L-shape training support. We also compare with the baseline of the non-additive decoder, which is based on the standard auto-encoder architecture.
We provide a qualitative visualization of the performance of both the additive and the non-additive decoder approach in Figure 7. For more details regarding the quantitative results and other setups see the paper.
![[Figure 7: The figure in the top row shows latent representation outputted by the encoder over the training dataset and the corresponding reconstructed images of the additive decoder for the ScalarLatents dataset. The figure in the bottom row shows the same thing for the non-additive decoder. The color gradient corresponds to the value of one of the ground-truth factor, the red dots correspond to factors used to generate the images, and the yellow dashed square highlights extrapolated images.]](/sites/default/files/inline-images/GAmeQCJXgAAeGjf.jpeg)
In the left column of Figure 7, we plot the latent representations learned by the encoder across the training set and in the right column we show the corresponding generated images. The shaded region in the latent space plot denotes the examples seen during training. For the additive decoder, we find that changing the predicted latent 1 results only in the change of the blue circle, and analogously for the latent 2. Hence, each predicted latent corresponds to only a unique object, and we have disentanglement. Note that this results in an inverted L-shaped latent support over the training examples, as the order in which the predicted latents correspond to the objects can be different from the true order. However, we do not have disentanglement in the non-additive decoder, as changing one of the predicted latent leads to a change in both circles. Furthermore, the additive decoder approach can extrapolate beyond the training support and generate novel images where both the circles have a high y-coordinate, while the non-additive decoder approach is unable to do so.
Finally, we also visualize the block-specific decoder reconstructions of images generated by the additive decoder in the figure below. We indeed find that each block-specific decoder generates a unique object, hence the latent representations learned by the model are disentangled.
![[Figure 8: The first row is the original image, the second row is the reconstruction and the third and fourth rows are the output of the object-specific decoders.]](/sites/default/files/inline-images/GAmb2n9XAAAy6jd.jpeg)
Conclusion
Our work helps obtain insights into why object-centric methods work and how they can be used to generate novel compositions of objects. While the expressivity of additive decoders is limited, this is only a first step. Future work involves extending our results for provable latent identification & extrapolation for the case of masked addition such that the case with object occlusion is handled. A concurrent work [3] establishes provable compositionality/extrapolation for a more general class of functions that can handle masked addition, however, they assume access to the true latent variables and their analysis does not show how to achieve provable disentanglement along with compositionality for the proposed class of mixing functions. Hence, it is still an important open problem to prove such results for a more general class of mixing functions than additive decoders.
Further, our work provides guarantees only for the decoder extrapolation to the cartesian product extension of the training support, but not for the extrapolation of the encoder. An important future step would be to extend our analysis and method for guarantees on encoder extrapolation as well! A recent work [4] proposes encoder consistency loss achieving the same, and it would be interesting to develop further on this problem!
Finally, we are very excited to extend this strategy to understand creativity in deep generative models! Some recent works [5, 6] have made assumptions similar to additive decoders for the score functions of the data distribution and shown how this can be used for compositionality with diffusion models. Hence, this is an interesting and impactful direction to prove similar guarantees for disentanglement and extrapolation with diffusion models.
References
- Burgess, Christopher P., Loic Matthey, Nicholas Watters, Rishabh Kabra, Irina Higgins, Matt Botvinick, and Alexander Lerchner. "Monet: Unsupervised scene decomposition and representation." arXiv preprint arXiv:1901.11390 (2019).
- Locatello, Francesco, Dirk Weissenborn, Thomas Unterthiner, Aravindh Mahendran, Georg Heigold, Jakob Uszkoreit, Alexey Dosovitskiy, and Thomas Kipf. "Object-centric learning with slot attention." Advances in Neural Information Processing Systems 33 (2020): 11525-11538.
- Wiedemer, Thaddäus, Prasanna Mayilvahanan, Matthias Bethge, and Wieland Brendel. "Compositional generalization from first principles." Advances in Neural Information Processing Systems 36 (2024).
- Wiedemer, Thaddäus, Jack Brady, Alexander Panfilov, Attila Juhos, Matthias Bethge, and Wieland Brendel. "Provable Compositional Generalization for Object-Centric Learning." arXiv preprint arXiv:2310.05327 (2024).
- Wang, Zihao, Lin Gui, Jeffrey Negrea, and Victor Veitch. "Concept Algebra for (Score-Based) Text-Controlled Generative Models." Advances in Neural Information Processing Systems 36 (2024).
- Liu, Nan, Yilun Du, Shuang Li, Joshua B. Tenenbaum, and Antonio Torralba. "Unsupervised Compositional Concepts Discovery with Text-to-Image Generative Models." arXiv preprint arXiv:2306.05357 (2023).