Note de la rédaction : Cet article a fait l’objet d’une présentation orale à NeurIPS 2023.
Le mystère des transformeurs et de l’apprentissage par renforcement


Un agent d’apprentissage par renforcement vise à maximiser la somme des récompenses en interagissant avec un environnement. À chaque pas de temps, l’agent entreprend une action fondée sur les renseignements observés, puis reçoit une récompense. Une caractéristique distincte des algorithmes d’apprentissage par renforcement, contrairement aux algorithmes d’apprentissage supervisé, est leur capacité à attribuer le mérite (temporellement), c’est-à-dire déterminer le moment où les actions qui ont conduit à une récompense actuelle se sont produites.
Généralement, dans la modélisation de scénarios utilisant des processus décisionnels de Markov, l’hypothèse selon laquelle le futur est indépendant du passé compte tenu du présent permet de prendre des décisions en fonction des observations actuelles (c’est-à-dire de l’état). Cependant, les situations du monde réel défient souvent cette hypothèse markovienne, introduisant une observabilité partielle. Dans les tâches partiellement observables (connues sous le nom de POMDP), les agents d’apprentissage par renforcement peuvent s’appuyer sur l’ensemble de l’historique (toutes les observations et actions précédentes) pour entreprendre des actions. La capacité à se rappeler les renseignements pertinents tirés de l’histoire est appelée « mémoire » (de travail).
Par conséquent, la résolution d’une tâche POMDP nécessite deux formes cruciales de raisonnement temporel : la mémoire et l’attribution du mérite. Ces deux concepts font partie des capacités essentielles des agents d’apprentissage par renforcement, malgré l’absence de définitions mathématiques claires (que ce travail abordera). Dans le domaine de l’apprentissage par renforcement profond, ces capacités peuvent être acquises simultanément par des algorithmes d’apprentissage par renforcement utilisant des modèles de séquences.
Au cours des dernières années, les transformeurs, une catégorie puissante de modèles de séquences, ont fait des remous dans divers domaines de l’apprentissage par renforcement, y compris l’apprentissage par renforcement sans modèle, l’apprentissage par renforcement fondé sur un modèle et l’apprentissage par renforcement hors ligne. Cependant, la grande question demeure : pourquoi les transformeurs sont-ils si efficaces dans l’apprentissage par renforcement, en particulier lorsqu’il s’agit de traiter des POMDP? Nous nous penchons sur cette énigme et explorons deux pistes qui pourraient changer la donne : est-ce parce que les transformeurs apprennent mieux les représentations historiques (mémoire), à l’instar de leur succès en matière d’apprentissage supervisé? Ou alors, est-ce parce que les transformeurs apprennent un meilleur algorithme d’attribution du mérite qui surpasse les algorithmes connus d’apprentissage par renforcement?
Contributions de cette étude
Pour percer les mystères des transformeurs dans l’apprentissage par renforcement, notre travail adopte une approche proactive. Tout d’abord, nous présentons des définitions mathématiques de la mémoire et de l’attribution du mérite. Ensuite, nous appliquons ces définitions pour décortiquer les tâches existantes, dont beaucoup mêlent la mémoire et l’attribution du mérite. Enfin, nous évaluons l’apprentissage par renforcement fondé sur les transformeurs dans des tâches qui exigent une mémoire et une attribution du mérite à long terme.
La réponse de notre article à cette question cruciale est la suivante : les transformeurs excellent dans les tâches qui font appel à la mémoire à long terme dans le cadre de l’apprentissage par renforcement, mais peinent lorsqu’il s’agit de procéder à l’attribution du mérite à long terme.
Mesure des dépendances temporelles dans l’apprentissage par renforcement
De manière formelle, dans les POMDP, à chaque pas de temps \(t\), un agent reçoit l’observation actuelle \(ot\) et entreprend une action \(at\) en fonction de l’historique \(ht=(o1:t,a1:t−1)\), selon sa politique \(π(at∣ht)\). L’environnement, quant à lui, fournit à l’agent un signal de récompense \(rt\) et la prochaine observation \(ot+1\), suivant la transition \(P(rt,ot+1∣ht,at)\). De plus, la valeur-Q définie par \(Qπ(ht,at)\) est largement utilisée dans l’apprentissage par renforcement pour aider à apprendre la politique \(π\) définie comme la somme attendue des récompenses futures suivant la politique et la transition.
Nous commençons par introduire les longueurs de mémoire dans les POMDP. Chaque composante (récompense, observation, action, valeur) peut dépendre de l’ensemble de l’historique. Nous définissons les longueurs de mémoire en fonction de notre intuition : quelle est la longueur minimale de l’historique nécessaire pour prédire ou générer la récompense, l’observation, l’action ou la valeur? Nous avons appelé ces longueurs d’historique minimales, respectivement, les longueurs de mémoire de récompense, de transition, de politique et de valeur.
Nous introduisons ensuite la longueur (en nombre de pas de temps) de l’attribution du mérite. Ici, nous posons la question suivante : Combien de pas de temps faut-il pour qu’une action optimale produise ses bénéfices par rapport à la somme des récompenses à n-pas? Par définition, une action optimale est la meilleure en ce qui concerne la somme des récompenses à pas infinis (c.-à-d. la valeur Q), mais nous sommes curieux de savoir quels sont les nombres de pas futurs minimaux.
Pour obtenir des définitions formelles, veuillez vous reporter à notre article. Nous présentons ci-dessous deux séries d’exemples pour mieux illustrer nos concepts.
Exemple (récompenses denses ou clairsemées). Considérons deux processus décisionnels de Markov qui ne diffèrent que par leur fonction de récompense. Le premier comporte des récompenses denses, représentées par une distance \(ℓ_2\) entre l’observation courante et le but. Inversement, le second processus décisionnel comporte des récompenses clairsemées, représentées par une fonction indicatrice du but. Étant donné qu’il s’agit de processus décisionnels de Markov, l’utilisation de l’observation courante permet de prédire chaque composante, ce qui se traduit par des longueurs de mémoire de 1.
Le processus décisionnel de Markov à récompenses denses a une longueur d’attribution du mérite courte (environ 1 pas de temps) parce que chaque action optimale \(a_t\) se démarque en fait de récompense immédiate \(r_t\). Le processus décisionnel de Markov à récompenses clairsemées a une grande longueur d’attribution du mérite (environ le nombre total de pas pour atteindre le but) parce que l’action optimale au premier pas ne se distingue pas jusqu’au dernier pas.
Exemple (ouvrir le coffre-fort)


Scénario 1 : Alice se souvient de son code d’accès défini un mois plus tôt et ouvre un coffre-fort rempli d’argent. La longueur de la mémoire de politique est d’un mois (ouvrir le coffre-fort en se rappelant le code d’accès défini un mois plus tôt), tandis que la longueur de l’attribution du mérite est courte.
Scénario 2 : Robert ramasse une clé (il peut alors toujours voir la clé) et, un mois plus tard, il ouvre un coffre-fort rempli d’argent. La longueur de la mémoire de politique est courte (car il peut toujours voir la clé), tandis que la longueur de l’attribution du mérite est grande (le fait de ramasser la clé n’est récompensé que lors de l’ouverture du coffre, un mois plus tard).
Ces deux scénarios constituent un exemple typique de découplage entre la mémoire et l’attribution du mérite. De façon semblable, en nous appuyant sur nos concepts, nous pouvons analyser les références en matière de mémoire préalable et d’attribution du mérite dans le cadre de l’apprentissage par renforcement. Veuillez consulter notre article pour en savoir plus.
Labyrinthes en T. Pour dissocier la mémoire de l’attribution du mérite, nous présentons deux tâches d’apprentissage par renforcement personnalisables impliquant des jouets, qui seront évaluées lors de nos expériences. Les deux tâches s’inspirent du labyrinthe en T, une tâche de mémoire classique utilisée en neurosciences. Les principales caractéristiques sont les suivantes :
L’objectif est d’atteindre le but G à partir du point de départ S.
Le but est randomisé entre G1 et G2 dans chaque épisode, accessible uniquement à l’oracle O.
L’agent optimal se dirige d’abord vers O pour obtenir les renseignements sur le but, puis se dirige vers la jonction J, et choisit enfin le but.
Il y a une pénalité dense pour encourager l’agent à se diriger vers J, une prime pour atteindre le but, mais aucune récompense pour atteindre O.
L’horizon de la tâche correspond à la longueur du corridor afin de s’assurer que l’agent ne peut choisir le but qu’une seule fois.
Nous définissons les termes « labyrinthe en T passif » et « labyrinthe en T actif » comme suit :
Labyrinthe en T passif : l’oracle O coïncide avec le point de départ S. Ainsi, la longueur de la mémoire est l’horizon complet (en rappelant les renseignements sur le but connus au début, lors du choix du but en J), tandis que l’attribution du mérite est courte (en raison de la pénalité dense).
Labyrinthe en T actif : l’oracle O se trouve à un pas à gauche du point de départ S. La longueur de la mémoire reste un horizon complet, tandis que la longueur de l’attribution du mérite devient un horizon complet (l’action de se diriger vers O n’est pas récompensée tant que le but n’est pas atteint).


Évaluation de l’apprentissage par renforcement fondé sur les transformeurs en fonction de sa mémoire et de l’attribution du mérite
Nous allons maintenant nous pencher sur l’évaluation des agents d’apprentissage par renforcement fondés sur la mémoire qui tirent parti des transformeurs. Notre objectif principal consiste à répondre à la question centrale de cet article : dans quelle mesure les transformeurs améliorent-ils les capacités de raisonnement temporel en apprentissage par renforcement?
Nous adoptons les architectures d’apprentissage par renforcement sans modèle décrites ci-dessous, utilisant le transformateur (GPT-2) comme modèle de séquences. Le réseau à mémoire à long et court terme (réseau MLCT) sert de base de comparaison. Nous utilisons la durée totale de l’épisode comme longueur de séquence pour entraîner les agents d’apprentissage par renforcement à partir de zéro.
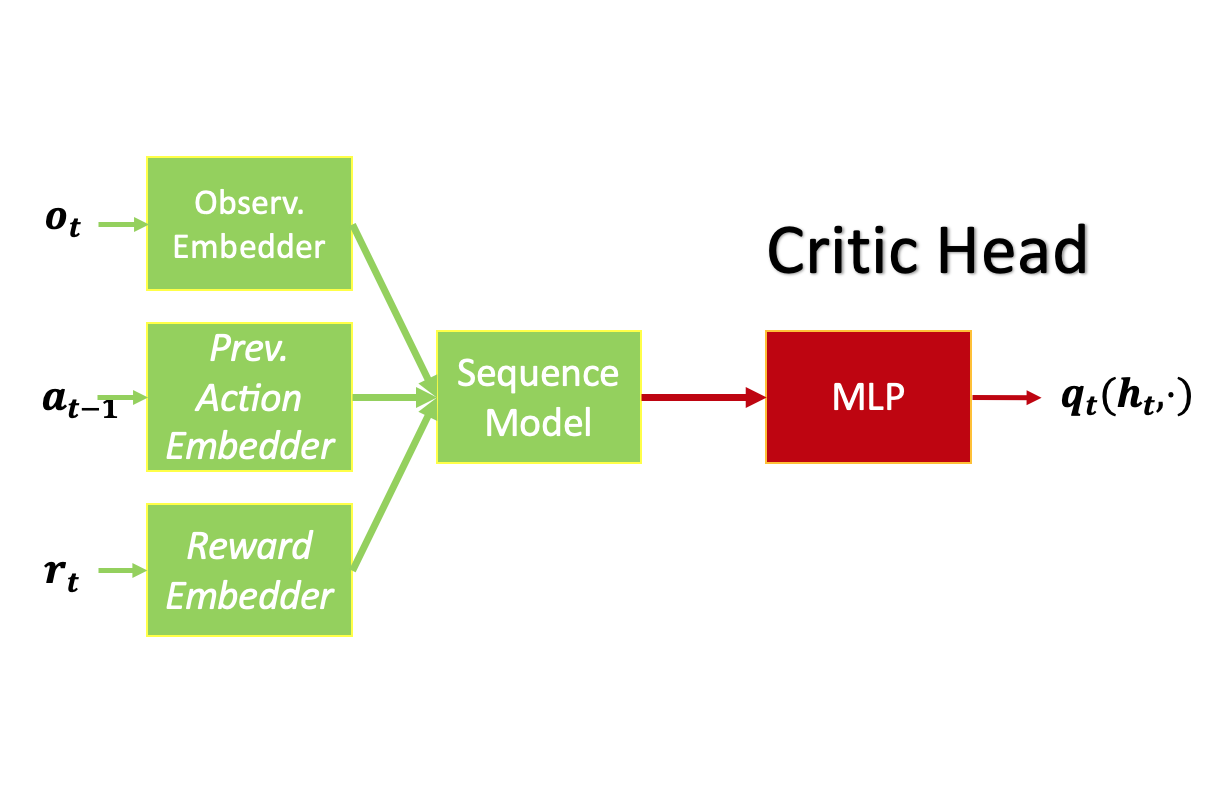
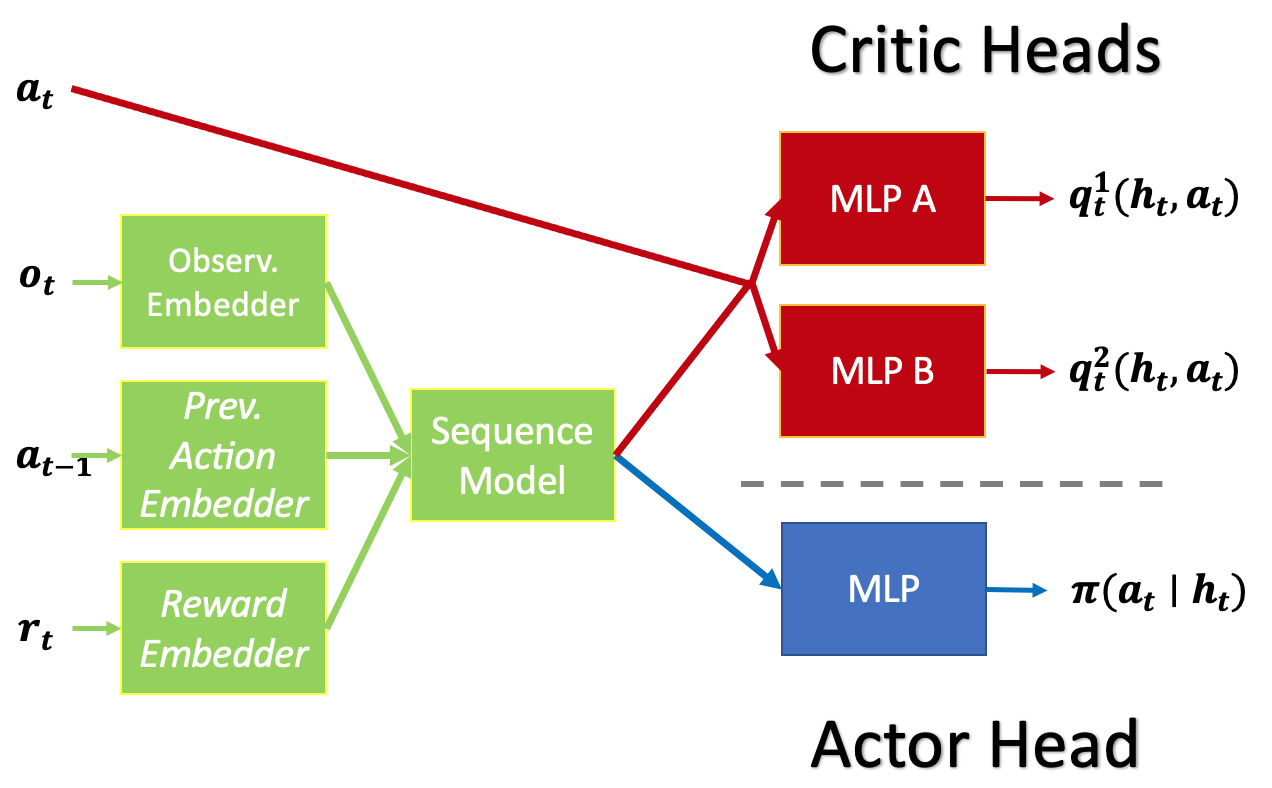
Agent d’apprentissage par renforcement pour les problèmes à action discrète (labyrinthes en T) utilisé dans nos expériences. Agent d’apprentissage par renforcement pour les problèmes à action continue (PyBullet) utilisé dans nos expériences.
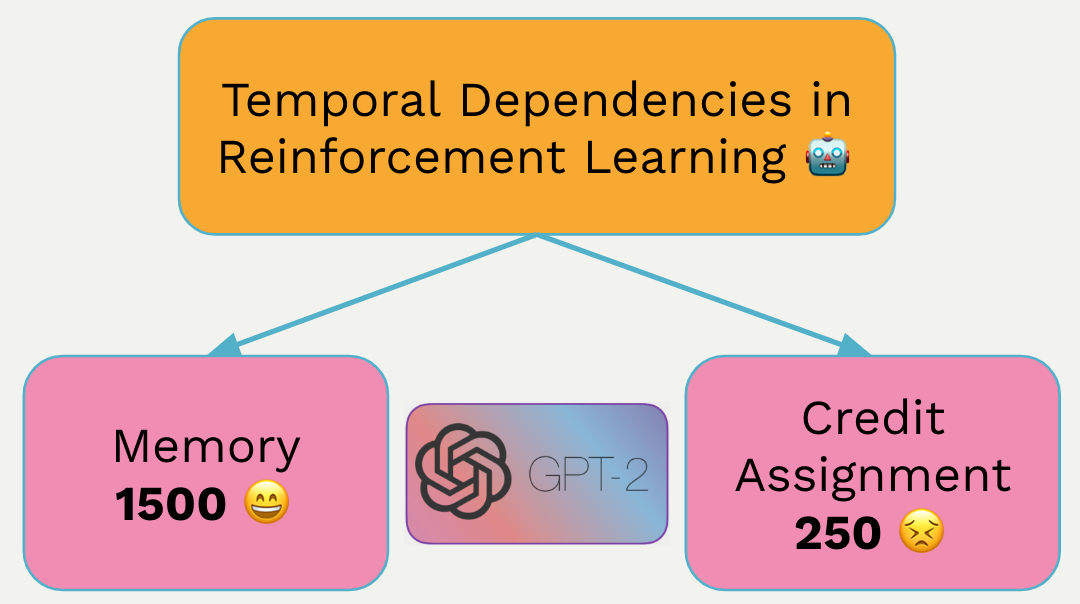
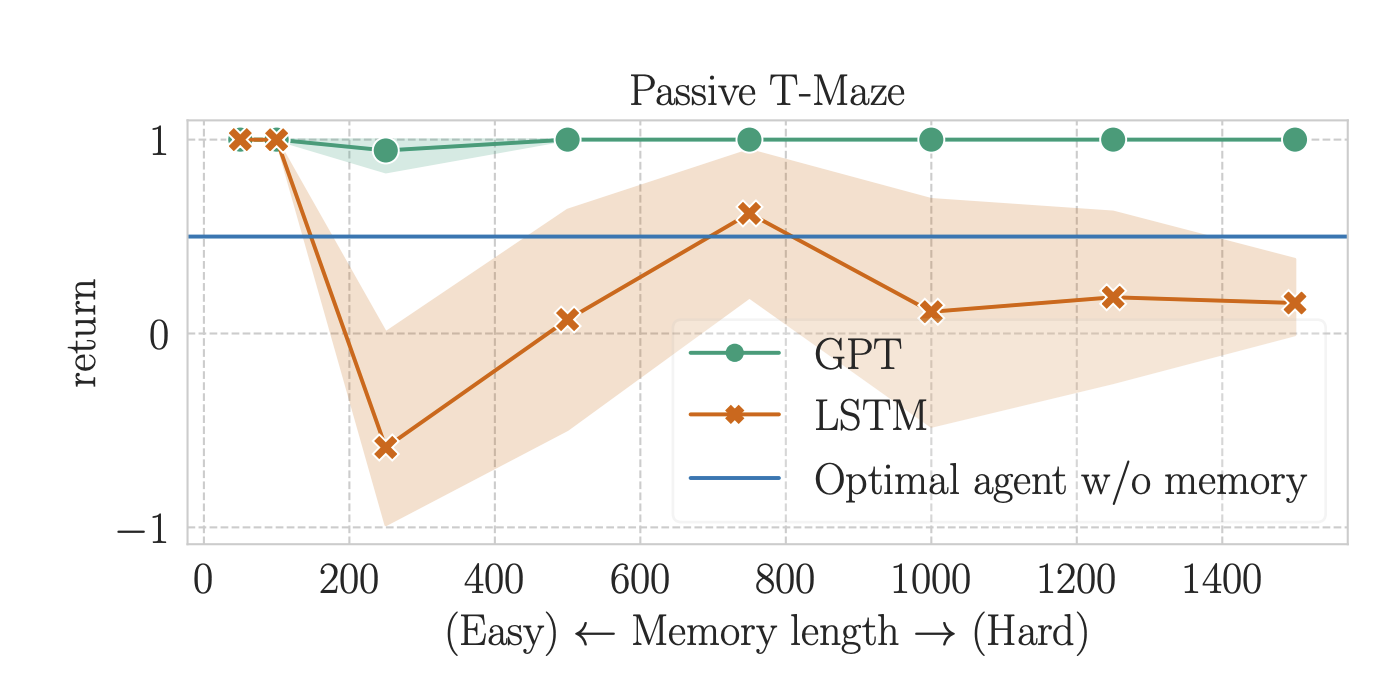
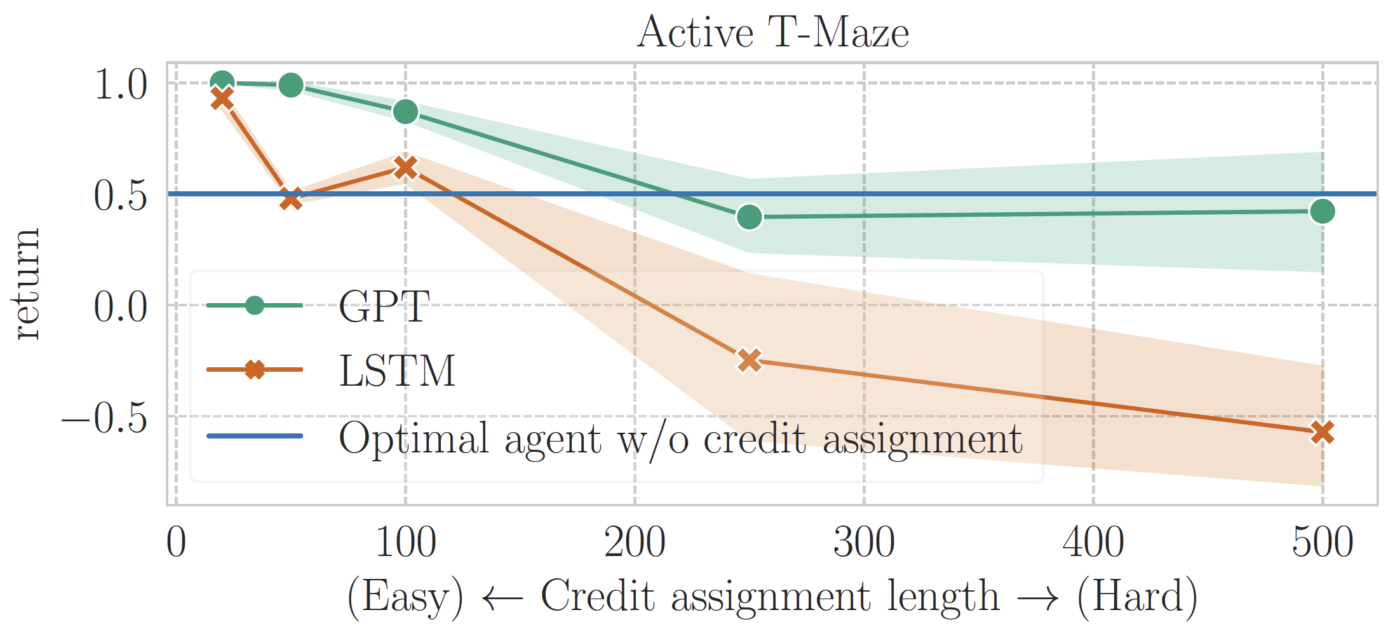
Tout d’abord, nous évaluons des agents d’apprentissage par renforcement fondés sur la mémoire sur des labyrinthes en T passifs et actifs. Pour chaque tâche, nous entraînons chaque algorithme jusqu’à la convergence à des longueurs variables, allant de 50 à 1 500 dans le labyrinthe en T passif (50 à 500 dans le labyrinthe en T actif).
Ces résultats, illustrés dans les figures ci-dessous, révèlent que l’apprentissage par renforcement fondé sur les transformeurs excelle dans la résolution du labyrinthe en T passif jusqu’à une longueur de mémoire de 1 500. En revanche, l’apprentissage par renforcement fondé sur le réseau MLCT peine à dépasser la ligne de référence sans mémoire, même avec une longueur de mémoire de 250, ce qui représente la plus grande longueur de mémoire que l’apprentissage par renforcement ait pu résoudre en juillet 2023. Des recherches ultérieures ont permis de repousser ces limites.
Toutefois, une limite notable apparaît pour les transformeurs : ils s’avèrent inefficaces pour traiter l’attribution du mérite à long terme à partir d’une longueur de 250. Ce défaut de performance est partagé avec l’apprentissage par renforcement fondé sur le réseau MLCT, ce qui indique un défi commun aux deux architectures.
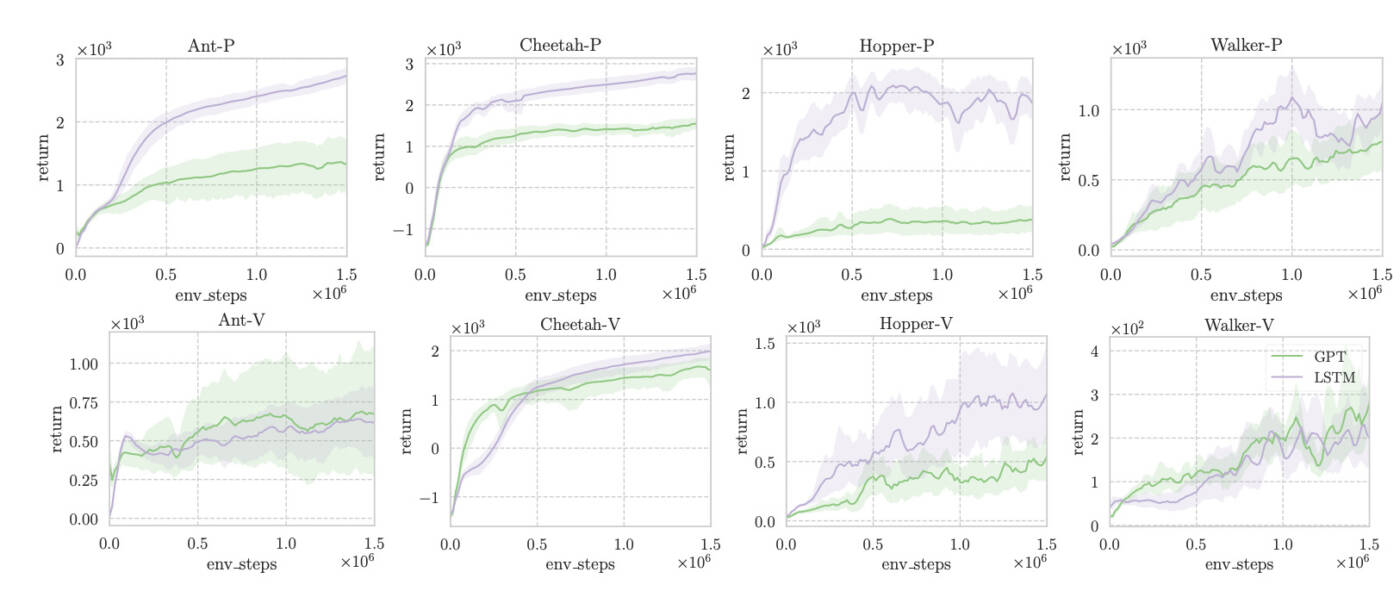
Pour conclure notre évaluation, nous comparons l’apprentissage par renforcement fondé sur la mémoire au modèle de référence PyBullet, le « POMDP standard » largement utilisé. Ce modèle de référence propose un contrôle continu avec des dépendances à court terme, révélant les positions (– P) ou les vitesses (– V) uniquement à l’agent. Conformément aux études antérieures, nous entraînons TD3 avec une longueur de contexte de 64, équipé de réseaux MLCT ou de GPT-2. Les résultats montrent que les transformeurs présentent une efficacité d’échantillonnage inférieure à celle des réseaux MLCT dans la plupart des tâches.
Liens
Si vous souhaitez vous plonger dans les détails de notre recherche, veuillez consulter la version arxiv et le code GitHub.
Remerciements
Cet article de blogue est le fruit d’un travail de collaboration avec Michel Ma, Ben Eysenbach et Pierre-Luc Bacon. Nous remercions tout particulièrement Jerry Huang et Glen Berseth pour leur aide précieuse dans la révision de cet article.