



Learning Speaker Representations with Mutual Information
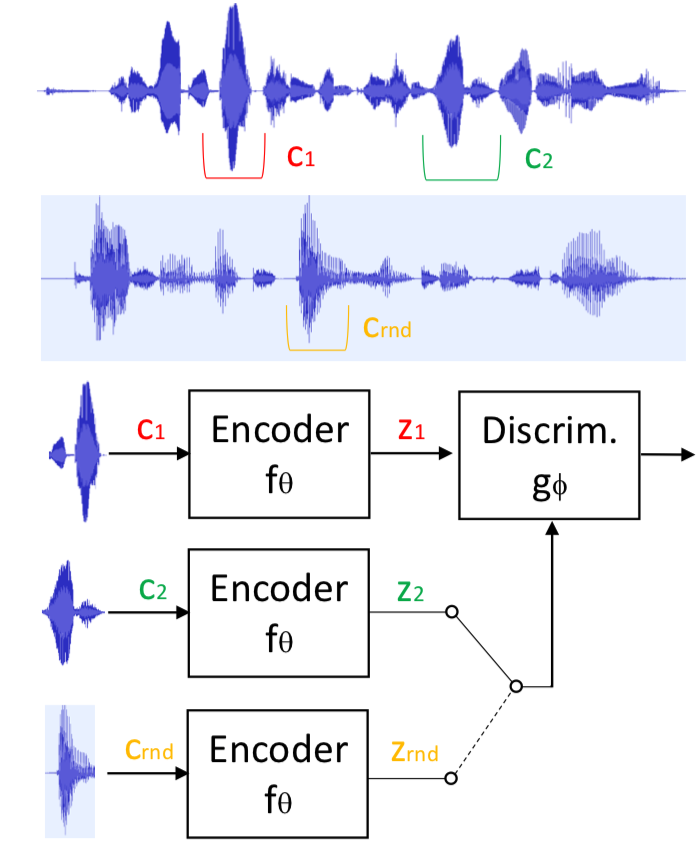
Apprendre de bonnes représentations est d’une importance cruciale dans l’apprentissage profond. Les informations mutuelles (MI) ou des mesures similaires de dépendance statistique sont des outils prometteurs pour l’apprentissage de ces représentations de manière non supervisée. Bien que les informations mutuelles entre deux variables aléatoires soient difficiles à mesurer directement dans des espaces de grandes dimensions, des études récentes ont montré qu’une optimisation implicite de MI pouvait être obtenue avec une architecture codeur-discriminateur similaire à celle des réseaux génératifs d’adversaire (GANs). Dans ce travail, nous apprenons des représentations qui capturent les identités des locuteurs en maximisant les informations mutuelles entre les représentations codées de morceaux de parole échantillonnés de manière aléatoire à partir de la même phrase. Le codeur proposé s’appuie sur l’architecture SincNet et transforme la forme d’onde brute de la parole en un vecteur de caractéristiques compact. Le discriminateur est alimenté soit par des échantillons positifs (de la distribution conjointe de morceaux codés), soit par des échantillons négatifs (du produit des marginaux) et est formé pour les séparer. Nous rapportons des expériences montrant que cette approche apprend efficacement des représentations utiles du locuteur, conduisant à des résultats prometteurs pour les tâches d’identification et de vérification du locuteur. Nos expériences prennent en compte les paramètres non supervisés et semi-supervisés et comparent les performances obtenues avec différentes fonctions objectives.
Reference
https://arxiv.org/abs/1812.00271

