



Char2Wav: End-to-End Speech Synthesis
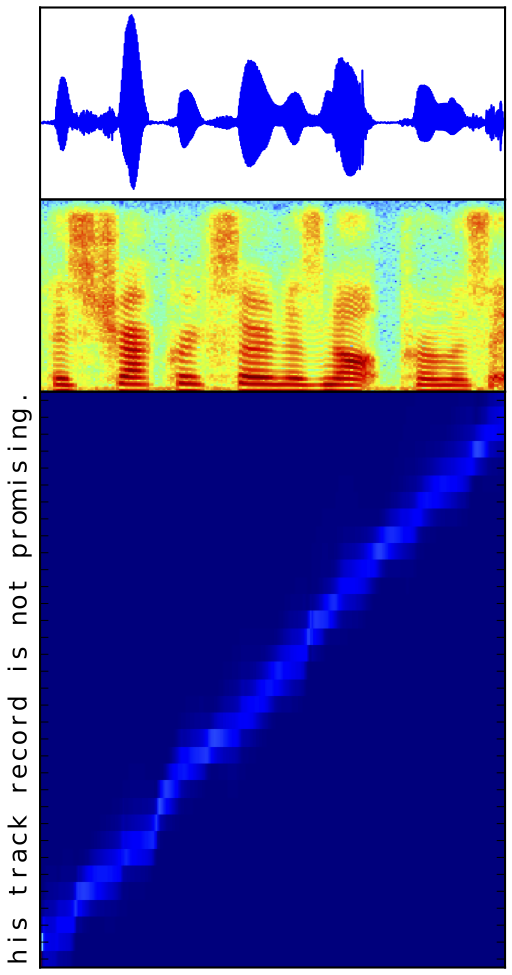
Nous présentons Char2Wav, un modèle de bout en bout pour la synthèse de la parole. Char2Wav a deux composants: un lecteur et un vocodeur neural. Le lecteur est un modèle de codeur-décodeur avec attention. Le codeur est un réseau neuronal récurrent bidirectionnel qui accepte du texte ou des phonèmes comme entrées, tandis que le décodeur est un réseau neuronal récurrent (RNN) avec une attention particulière qui produit des caractéristiques acoustiques de vocodeur. Le vocodeur neuronal fait référence à une extension conditionnelle de SampleRNN qui génère des échantillons de forme d’onde bruts à partir de représentations intermédiaires. Contrairement aux modèles traditionnels de synthèse vocale, Char2Wav apprend à produire de l’audio directement à partir de texte.
Lien pour le demo.






