



Feb
2017
Char2Wav: End-to-End Speech Synthesis
Feb
2017
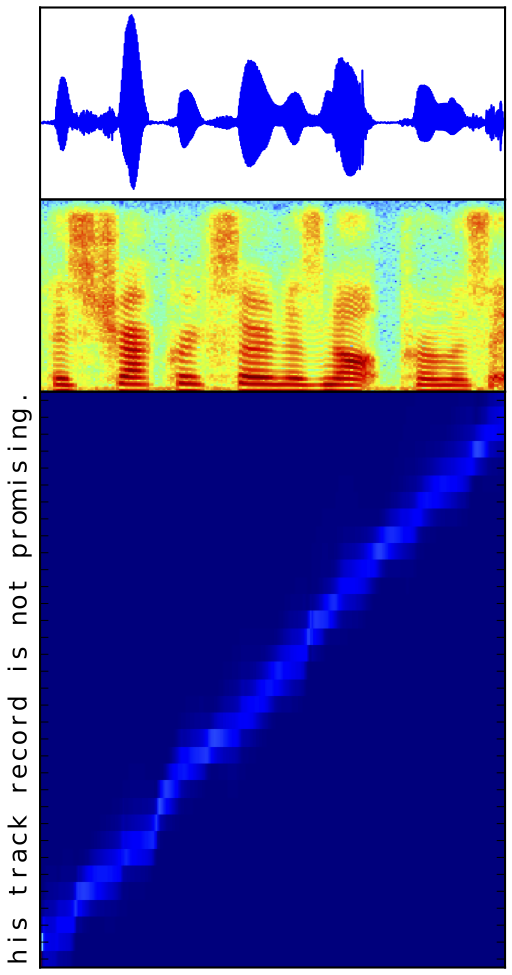
We present Char2Wav, an end-to-end model for speech synthesis. Char2Wav has two components: a reader and a neural vocoder. The reader is an encoder-decoder model with attention. The encoder is a bidirectional recurrent neural network that accepts text or phonemes as inputs, while the decoder is a recurrent neural network (RNN) with attention that produces vocoder acoustic features. Neural vocoder refers to a conditional extension of SampleRNN which generates raw waveform samples from intermediate representations. Unlike traditional models for speech synthesis, Char2Wav learns to produce audio directly from text.
Link to demo.






