



Bounding the Test Log-Likelihood of Generative Model
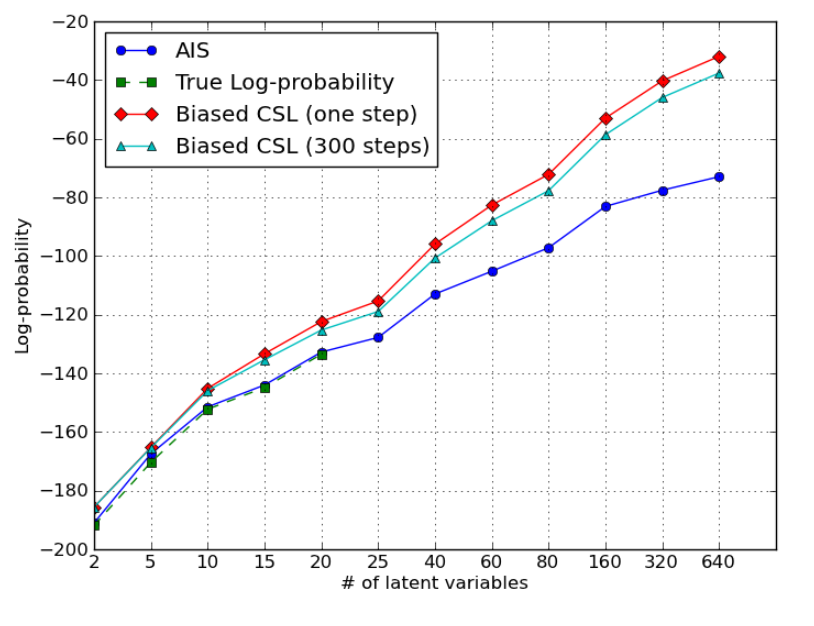
Several interesting generative learning algorithms involve a complex probability distribution over many random variables, involving intractable normalization constants or latent variable normalization. Some of them may even not have an analytic expression for the unnormalized probability function and no tractable approximation. This makes it difficult to estimate the quality of these models, once they have been trained, or to monitor their quality (e.g. for early stopping) while training. A previously proposed method is based on constructing a non-parametric density estimator of the model’s probability function from samples generated by the model. We revisit this idea, propose a more efficient estimator, and prove that it provides a lower bound on the true test log-likelihood, and an unbiased estimator as the number of generated samples goes to infinity, although one that incorporates the effect of poor mixing (making the estimated likelihood worse, i.e., more conservative).
Reference
Yoshua Bengio, Li Yao, Kyunghyun Cho, Bounding the Test Log-Likelihood of Generative Models, in: International Conference on Learning Representations (ICLR), 2014


