




Utiliser les tâches associées à l’IA au profit d’autres domaines
À commencer par la littérature japonaise
Laura Ball, Mila
Les recherches sur l’intelligence artificielle (IA) s’appuient sur un ensemble de tâches communes qui permettent de comparer les modèles construits par différentes équipes. Comme les athlètes qui compétitionnent dans des conditions normalisées établies par les instances dirigeantes de leur sport, les chercheurs en IA du monde entier ont passé les 20 dernières années à entraîner leurs programmes à classer les 70 000 caractères manuscrits du MNIST, un ensemble de données créé avant que les réseaux de neurones puissent lire les numéros manuscrits sur les chèques bancaires. Cette tâche était difficile à accomplir lorsqu’elle a été introduite en 1998, mais aujourd’hui, pour reprendre les mots d’Alex Lamb, doctorant de Mila, elle a été « faite et refaite ». Étant donné qu’un grand nombre de programmes y parviennent avec une précision supérieure à 99 %, cette tâche ne permet plus de déterminer si un nouveau programme fait progresser ou non la science. En conséquence, les chercheurs ont commencé à créer des tâches dérivées plus complexes dans les mêmes conditions normalisées, comme l’EMNIST (un mélange de lettres majuscules et minuscules et de chiffres) et le FashionMNIST (des images de vêtements à classer dans les catégories chaussures, chemises, etc.). Alex veut ajouter un autre critère à ces tâches dérivées : au lieu de simplement produire de nouvelles versions du MNIST qui sont plus difficiles à résoudre, pourquoi ne pas créer d’autres qui soient utiles en dehors de notre propre communauté de recherche ?
En collaboration avec Tarin Clanuwat et Anasobu Kitamoto au Center for Open Data in the Humanities (CODH), Alex s’intéresse à un cas d’utilisation en particulier : la préservation de la littérature classique japonaise.

Le MNIST (à gauche) contient 70 000 images de caractères manuscrits réparties dans 10 catégories, toutes en noir et blanc et redimensionnées en 28×28 pixels. Le Fashion-MNIST (à droite) contient des images de 70 000 articles de vêtement réparties dans 10 catégories et formatées selon la taille et le style des images du MNIST.
Tout au long de la longue période d’isolement du Japon avant la campagne accélérée de l’empereur Meiji visant à moderniser le pays à la fin des années 1800, les livres japonais étaient produits selon un procédé de gravure sur bois avec une forme d’écriture cursive nommée kuzushiji. Le National Institute of Japanese Literature (NIJL) s’est fixé comme objectif de numériser au moins 300 000 des quelque 2 millions de livres de l’époque prémoderne inscrits au catalogue national. Le but est de s’assurer que leur contenu survive à la dégradation des copies papier. Toutefois, tirer de bonnes photos de toutes ces pages ne constitue que le premier élément du problème. Aujourd’hui, le système d’écriture kuzushiji n’est compris que par une petite fraction de la population japonaise qui possède un diplôme d’études supérieures en littérature classique. En 2016, des chercheurs de l’Université de Kyoto et de l’Université d’Osaka ont lancé KuLA, une application mobile qui utilise la base de données du NIJL pour enseigner le kuzushiji à l’aide de cartes-éclair et d’une jolie mascotte de bande dessinée. Cependant, il ne suffit pas de mémoriser et de catégoriser des caractères pour traduire le kuzushiji, car certains caractères peuvent être représentés de plusieurs façons et d’autres peuvent correspondre à différents sons selon le contexte.
Pour les chercheurs en apprentissage automatique, le kuzushiji pose également un problème intéressant en raison de la distribution « à queue lourde » des caractères : on dénombre plus de 4 000 caractères distincts dans le kuzushiji en raison de la fusion de 3 alphabets différents au cours du Moyen-Âge, et plusieurs de ces caractères apparaissent très peu souvent. Lire le kuzushiji à la perfection, sans erreurs, nécessiterait des percées dans l’apprentissage à partir de peu de données ou few-shot learning, l’expression utilisée par les informaticiens pour catégoriser correctement un nouveau type de données après l’avoir vu seulement quelques fois. Il s’agit d’un problème ouvert en IA qui fait l’objet de discussions fréquentes dans les ateliers de conférences d’envergure.

Le meilleur modèle de l’équipe d’Alex éprouve encore des difficultés avec les caractères rares. (Le vert montre l’équivalent en japonais moderne sélectionné par le modèle pour chaque caractère en kuzushiji. Le bleu indique l’équivalent exact, déterminé par les professeurs de littérature. Des X rouges marquent les endroits où le modèle s’est trompé.)
Au-delà de la quête du NIJL visant à préserver les livres en kuzushiji, l’idée de sauver les langues en danger en incitant les chercheurs en apprentissage automatique à s’en servir comme référence est porteuse pour des organisations comme l’UNESCO, qui maintient un atlas interactif des langues en danger, la société National Geographic, qui apporte son soutien au Living Tongues Institute for Endangered Languages et la U.S. Library of Congress, qui collabore avec Wikitongues. La première étape consiste à établir un ensemble de données des caractères de la langue en respectant le format du MNIST (70 000 images en noir et blanc de 28 x 28 pixels, réparties en 10 catégories, les caractères étant tous centrés et redimensionnés pour avoir la même taille) qui peut facilement être intégré aux structures des systèmes d’apprentissage existants. L’étape suivante consiste à afficher cet ensemble là où les chercheurs le verront. La version en kuzushiji du MNIST, appelée KMNIST, mise au point par Alex et ses collègues du CODH avec l’aide de Kazuaki Yamamoto du NIJL, de Mikel Bober-Irizar de la Royal Grammar School de Guilford, et de David Ha de Google AI, est maintenant comprise dans la liste officielle des ensembles de données de PyTorch, aux côtés du MNIST, de l’EMNIST, et du Fashion-MNIST.

Les 10 catégories de caractères du KMNIST, avec leurs équivalents japonais modernes à gauche.
Alex admet que les systèmes d’apprentissage automatique qui ne peuvent lire que les 10 types de caractères compris dans le KMNIST seraient peu utiles aux spécialistes de la littérature, mais il appelle cette tâche « une drogue passerelle », en espérant que les modèles (et les chercheurs) formés au KMNIST seront qualifiés pour passer aux autres ensembles de données colligés par son équipe, comme Kuzushiji-49, qui contient les 49 caractères les plus courants, et Kuzushiji-Kanji, qui comprend 3 832 caractères rares et pourrait remplacer le populaire ensemble de données Omniglot, introduit dès 2015 pour l’apprentissage à partir de peu de données et qui commence à être surutilisé comme le MNIST. L’étape finale consiste à lire des pages brutes de ces livres de l’époque prémoderne, ce qui pose des défis supplémentaires, comme de distinguer les textes des illustrations et de se déplacer entre les colonnes de texte dans le bon ordre.

Jusqu’à présent, le modèle de l’équipe d’Alex semble fonctionner assez bien avec des mises en page irrégulières. Dans cette image, le rouge montre les prédictions du modèle, dont la plupart sont exactes.
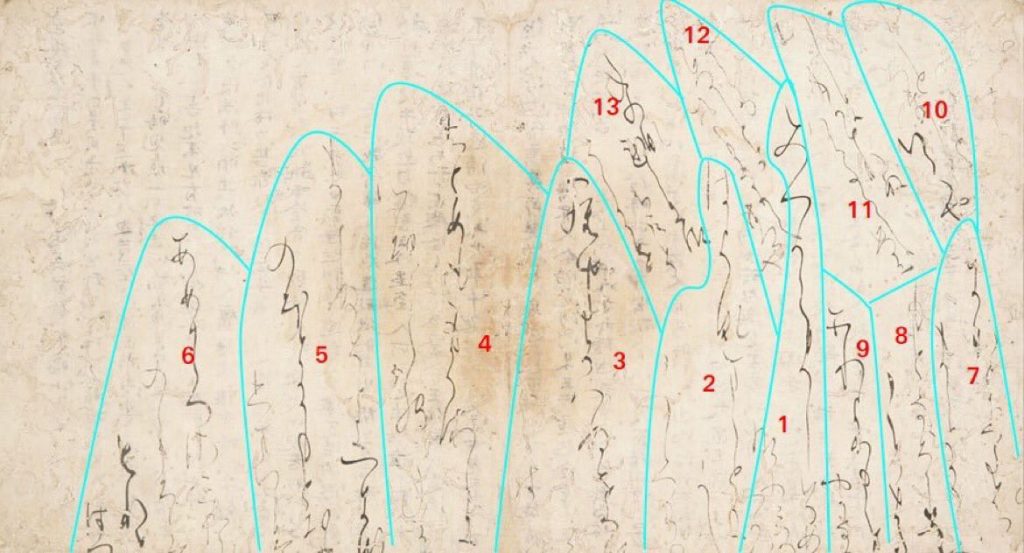
Les colonnes de texte en kuzushiji doivent être lues de droite à gauche, en commençant par la colonne dont les traits sont les plus foncés. Les autres colonnes ajoutées par la suite se lisent de droite à gauche dans l’espace restant.
Pour faire progresser le milieu de la recherche et accélérer ses progrès dans la réalisation des tâches, les parties intéressées pourraient utiliser une plateforme comme Kaggle ou InnoCentive pour lancer un concours qui récompenserait la première équipe à construire un système dont les performances dépasseraient un seuil donné. Les collègues d’Alex au CODH sont tentés de procéder ainsi pour les livres en kuzushiji, mais ne sont pas en mesure de formuler d’autres commentaires pour le moment.
Entre-temps, pour les chercheurs en IA qui mettent à l’essai des approches pour résoudre les problèmes fondamentaux de la reconnaissance des formes, la nature de leurs tâches dérivées liées au MNIST importe peu, pourvu que le format soit normalisé et que les données soient publiques afin que d’autres équipes puissent comparer leurs résultats. Utiliser cette marge de manœuvre afin que d’autres domaines en profitent semble être la chose intelligente à faire.
Voir l’article en anglais sur Medium.