




Leveraging exploration in off-policy algorithms via normalizing flows
Posted on24/10/2019
La capacité à découvrir des stratégies approximativement optimales dans des domaines à récompenses limitées est cruciale pour appliquer l’apprentissage par renforcement (LR)... En savoir plus
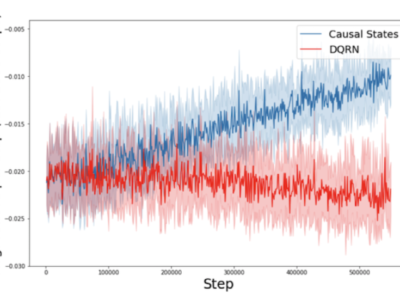
Learning Causal State Representations of Partially Observable Environments
Posted on25/06/2019
Les agents intelligents peuvent faire face à des environnements sensoriels très riches en apprenant des abstractions d’états non agnostiques. Dans cet article,... En savoir plus
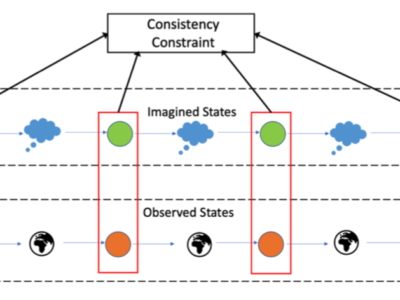
Learning Powerful Policies by Using Consistent Dynamics Model
Posted on11/06/2019
Les approches d’apprentissage par renforcement basées sur un modèle promettent d’être efficaces en échantillons. Une grande partie des progrès réalisés dans les... En savoir plus
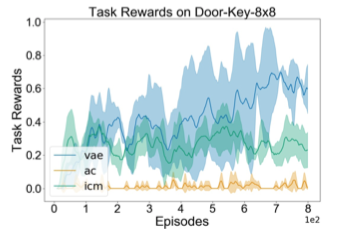
Variational State Encoding as Intrinsic Motivation in Reinforcement Learning
Posted on06/05/2019
La découverte de stratégies d’exploration efficaces est l’un des principaux défis de l’apprentissage par renforcement, en particulier dans le contexte d’environnements de... En savoir plus
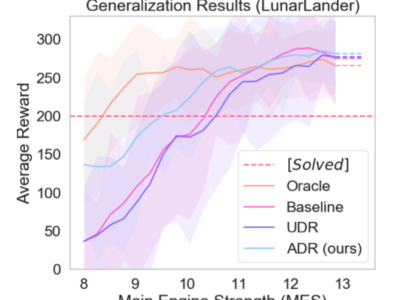
Active Domain Randomization
Posted on09/04/2019
La randomisation de domaines est une technique couramment utilisée pour améliorer le transfert de domaine. Elle est souvent utilisée dans un contexte... En savoir plus
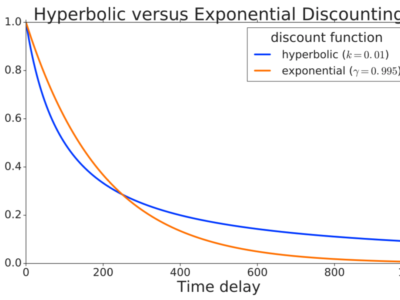
Hyperbolic Discounting and Learning over Multiple Horizons
Posted on19/02/2019
L’apprentissage par renforcement (RL) définit généralement un facteur de réduction dans le cadre du processus de décision de Markov. Le facteur d’escompte... En savoir plus
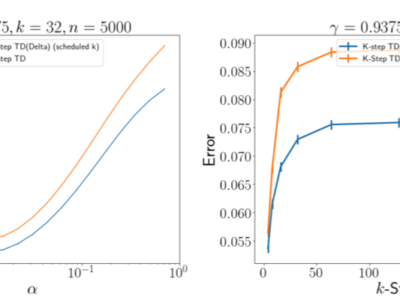
Separating value functions across time-scales
Posted on05/02/2019
Dans de nombreux paramètres d’apprentissage par renforcement épisodiques à horizon fini, il est souhaitable d’optimiser le retour non actualisé. Dans des paramètres... En savoir plus
Prioritizing Starting States for Reinforcement Learning
Posted on27/11/2018
Les approches d’apprentissage par renforcement basées sur un modèle promettent d’être efficaces en échantillons. Une grande partie des progrès réalisés dans les... En savoir plus
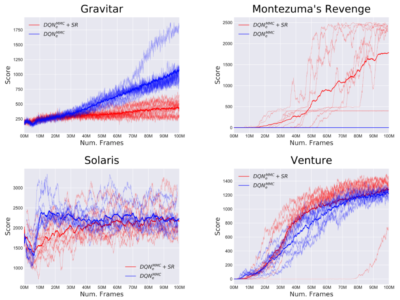
Count-Based Exploration with the Successor Representation
Posted on31/07/2018
Dans cet article, nous présentons une approche simple d’exploration dans l’apprentissage par renforcement (RL) qui nous permet de développer des algorithmes théoriquement... En savoir plus