



Variational State Encoding as Intrinsic Motivation in Reinforcement Learning
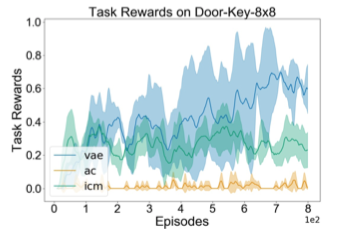
La découverte de stratégies d’exploration efficaces est l’un des principaux défis de l’apprentissage par renforcement, en particulier dans le contexte d’environnements de récompenses clairsemées. Nous posons que pour découvrir de telles stratégies, un agent RL devrait pouvoir identifier des états surprenants, et potentiellement utiles, dans lesquels l’agent rencontre des informations significatives qui s’écartent de ses croyances antérieures en matière d’environnement. Intuitivement, cette approche pourrait être comprise comme une mesure de la surprise d’un agent pour guider l’exploration. À cette fin, nous fournissons un mécanisme simple en formant un auto-encodeur variationnel pour extraire la structure latente de la tâche. Néanmoins, les auto-encodeurs variationnels maintiennent une distribution postérieure sur cette structure latente. En mesurant la différence entre cette distribution et les croyances antérieures de l’agent, nous sommes en mesure d’identifier des états pouvant contenir des informations utiles. En utilisant cette mesure comme mesure de la motivation intrinsèque, nous démontrons de manière empirique qu’un agent peut résoudre une série de tâches complexes de labyrinthe à récompenses rares, hautement stochastiques et partiellement observables. Nous effectuons également des expériences sur des tâches de contrôle continues avec des récompenses denses et affichons des performances améliorées dans la plupart des cas.
Reference
https://tarl2019.github.io/assets/papers/klissarov2019variational.pdf

