



The Knowref Coreference Corpus: Removing Gender and Number Cues for Difficult Pronominal Anaphora Resolution
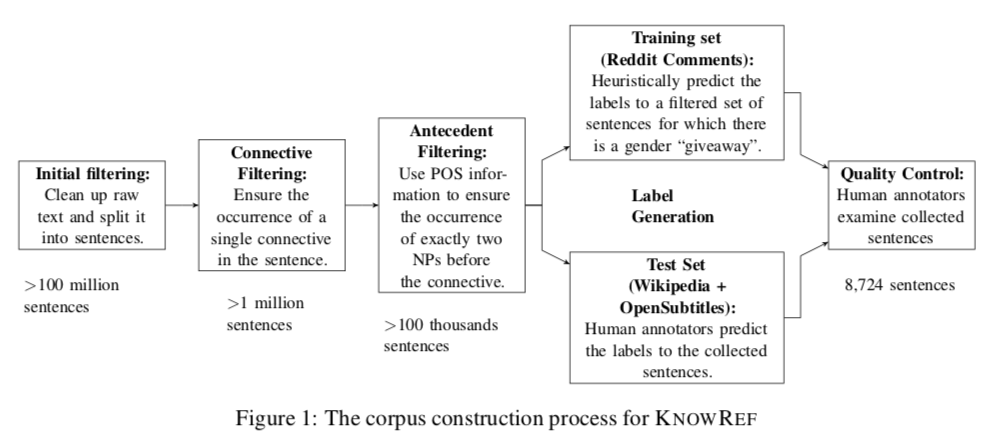
Nous introduisons un nouveau point de repère pour la résolution de la coréférence et l’INL, Knowref, qui cible la compréhension du sens commun et la connaissance du monde. Les tâches précédentes de résolution des coréférences peuvent être en grande partie résolues en exploitant le nombre et le sexe des antécédents, ou ont été créées à la main et ne reflètent pas la diversité du texte naturel. Nous présentons un corpus de plus de 8 000 passages de textes annotés avec une anaphore pronominale ambiguë. Ces cas sont à la fois difficiles et réalistes. Nous montrons que divers systèmes de coréférence, qu’ils soient basés sur des règles, riches en fonctionnalités ou neurales, ont des résultats bien moins bons que les humains, qui affichent un degré élevé d’accord entre les annotateurs. Pour expliquer cet écart de performance, nous montrons de manière empirique que les modèles les plus avancés échouent souvent à saisir le contexte, mais qu’ils s’appuient sur le sexe ou le nombre de candidats antérieur pour prendre une décision. Nous utilisons ensuite des informations spécifiques à un problème pour proposer une astuce d’augmentation des données appelée commutation antécédente afin d’atténuer cette tendance dans les modèles. Enfin, nous montrons que la commutation antécédente produit également des résultats prometteurs pour d’autres tâches: nous l’utilisons pour obtenir des résultats à la pointe de la technologie dans la tâche de gestion des liaisons GAP.
Reference
https://arxiv.org/abs/1811.01747

