



Speech Model Pre-training for End-to-End Spoken Language Understanding
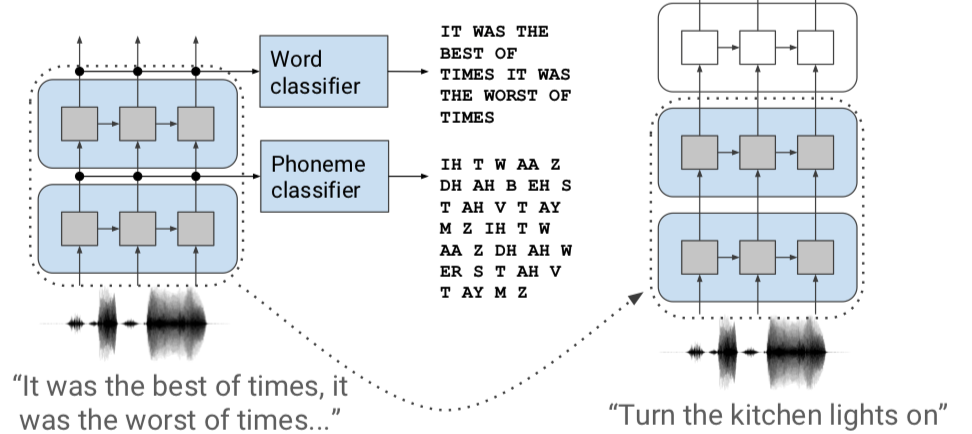
Alors que les systèmes de compréhension de la langue parlée (spoken language understanding : SLU) conventionnels associent la parole à un texte, puis le texte à l’intention, les systèmes de SLU de bout en bout associent directement la parole à l’intention au moyen d’un seul modèle pouvant être entraîné. Il est difficile d’obtenir une grande précision avec ces modèles de bout en bout sans beaucoup de données d’entraînement. Nous proposons une méthode pour réduire les besoins en données des systèmes de compréhension SLU de bout en bout, dans laquelle le modèle est d’abord entraîné pour la prédiction de mots et de phonèmes, permettant ainsi l’apprentissage de bonnes caractéristiques pour les systèmes SLU. Nous introduisons un nouvel ensemble de données SLU, les «Fluent Speech Commands», et montrons que notre méthode améliore les performances à la fois lorsque l’ensemble de données complet est utilisé pour la formation et lorsqu’un seul sous-ensemble est utilisé. Nous décrivons également des expériences préliminaires visant à évaluer la capacité du modèle à généraliser face à de nouvelles phrases non entendues lors de la formation.
Reference
https://arxiv.org/abs/1904.03670


