



Regularizing RNNs by Stabilizing Activations
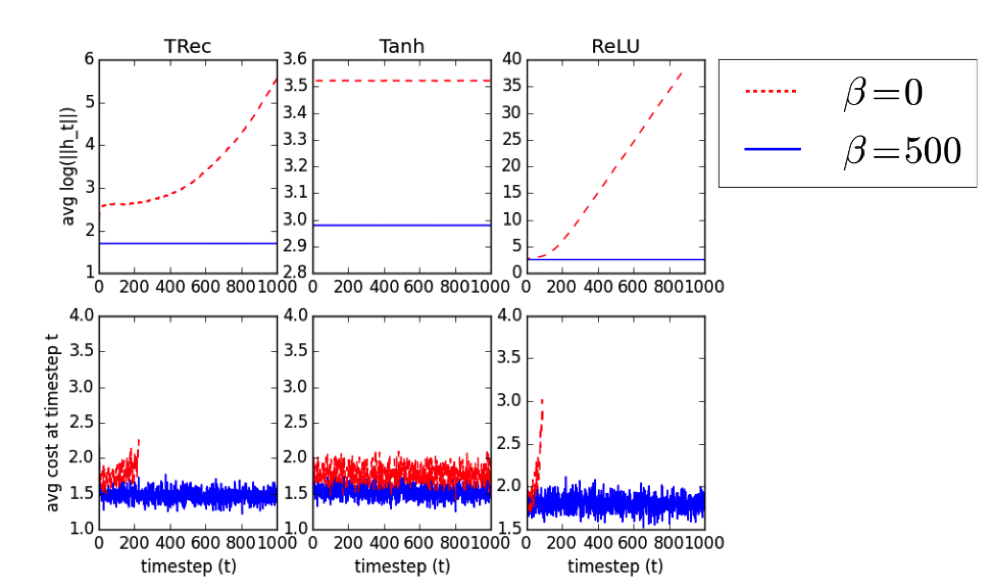
Nous stabilisons les activations des réseaux de neurones récurrents (RNN) en pénalisant la distance au carré entre les normes d’états cachés successifs. Ce terme de pénalité est un régularisateur efficace pour les RNN, y compris les LSTM et les IRNN, améliorant les performances en matière de modélisation du langage au niveau des caractères et de reconnaissance des phonèmes, et surpassant le bruit de fond et les abandons. Nous définissons l’état de l’art (17,5% PER) pour un RNN sur la tâche de reconnaissance de phonème TIMIT, sans utiliser la recherche de faisceau. Avec ce terme de pénalité, IRNN peut atteindre des performances similaires à celles de LSTM en ce qui concerne la modélisation du langage, bien que l’ajout du terme de pénalité au LSTM entraîne des performances supérieures. Notre terme de pénalité empêche également la croissance exponentielle des activations d’IRNN en dehors de leur horizon d’entraînement, leur permettant de se généraliser à des séquences beaucoup plus longues.
Reference
David Krueger, Roland Memisevic, Regularizing RNNs by Stabilizing Activations, in: International Conference on Learning Representations, 2016

