



Learning to Understand Goal Specifications by Modelling Reward
Des travaux récents ont montré que les agents d’apprentissage en renforcement profond peuvent apprendre à suivre des instructions semblables à celles d’une langue à partir de récompenses environnementales peu fréquentes. Cependant, cela impose aux concepteurs d’environnement le fardeau de concevoir des fonctions de récompenses conditionnelles pour le langage, qui peuvent ne pas être mises en œuvre facilement ou de manière flexible en raison de la complexité de l’environnement et des échelles de langage. Pour surmonter cette limitation, nous présentons un cadre dans lequel les agents RL conditionnés à l’instruction sont formés à l’aide de récompenses obtenues non pas de l’environnement, mais de modèles de récompenses formés conjointement à partir d’exemples d’experts. À mesure que les modèles de récompenses s’améliorent, ils apprennent à récompenser avec précision les agents qui effectuent des tâches pour les configurations d’environnement – et pour les instructions – qui ne figurent pas parmi les données expertes. Ce cadre sépare efficacement la représentation de ce que les instructions nécessitent de la manière dont elles peuvent être exécutées.
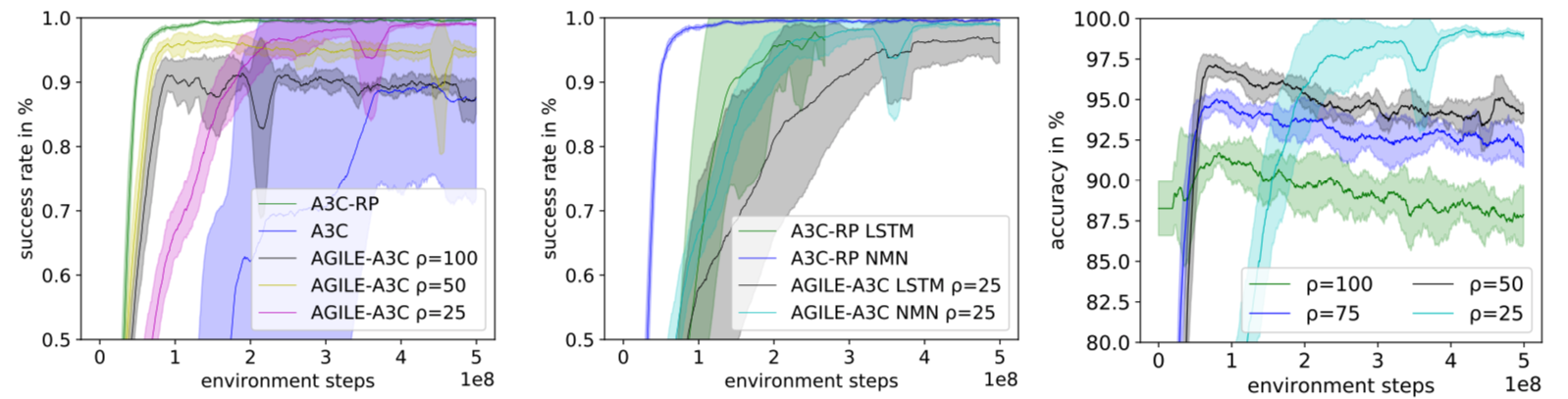
Dans un monde en grille simple, il permet à un agent d’apprendre une gamme de commandes nécessitant une interaction avec des blocs et une compréhension des relations spatiales et des arrangements abstraits sous-spécifiés. Nous montrons en outre que la méthode permet à notre agent de s’adapter aux changements de l’environnement sans nécessiter de nouveaux exemples d’experts.
Reference
https://openreview.net/forum?id=H1xsSjC9Ym

