



Learning Powerful Policies by Using Consistent Dynamics Model
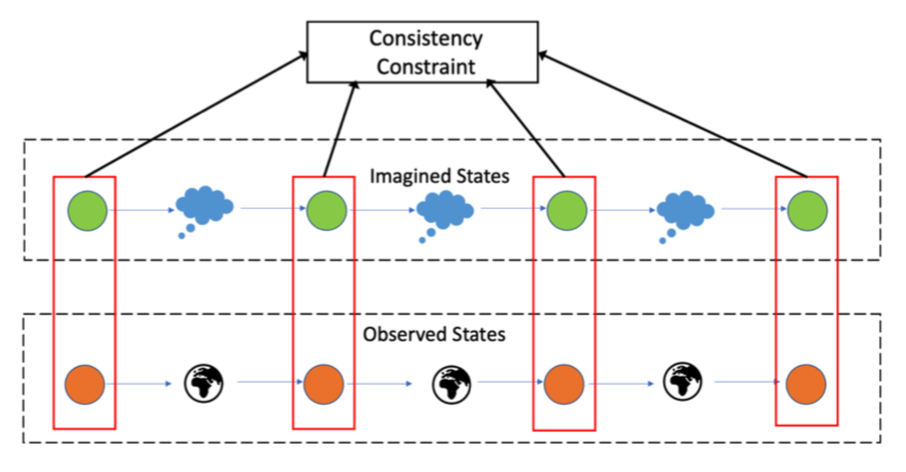
Les approches d’apprentissage par renforcement basées sur un modèle promettent d’être efficaces en échantillons. Une grande partie des progrès réalisés dans les modèles de dynamique d’apprentissage dans l’apprentissage par renforcement (RL) a été réalisée grâce aux modèles d’apprentissage via l’apprentissage supervisé. Mais les approches traditionnelles basées sur un modèle conduisent à des “erreurs de composition” lorsque le modèle est déroulé pas à pas. Essentiellement, les transitions d’état prédites par l’apprenant (en déroulant le modèle en plusieurs étapes) et les transitions d’état vécues par l’apprenant (en agissant dans l’environnement) peuvent ne pas être cohérentes. Il y a suffisamment de preuves que les humains construisent un modèle de l’environnement, non seulement en observant l’environnement, mais également en interagissant avec celui-ci. L’interaction avec l’environnement permet aux humains de mener des expériences: en prenant des mesures qui permettent de découvrir de vraies relations causales pouvant être utilisées pour construire de meilleurs modèles dynamiques. De manière analogue, nous nous attendrions à ce que de telles interactions soient utiles pour un agent d’apprentissage tout en apprenant à modéliser la dynamique de l’environnement. Dans cet article, nous nous appuyons sur cette intuition en utilisant une fonction de coût auxiliaire pour assurer la cohérence entre ce que l’agent observe (en agissant dans le monde réel) et ce qu’il imagine (en agissant dans le monde «appris»). Nous considérons plusieurs tâches – tâches de contrôle basées sur Mujoco et les jeux Atari – et montrons que l’approche proposée permet de former des politiques puissantes et de meilleurs modèles dynamiques.
Reference
https://arxiv.org/abs/1906.04355




