



Fairwashing: the risk of rationalization
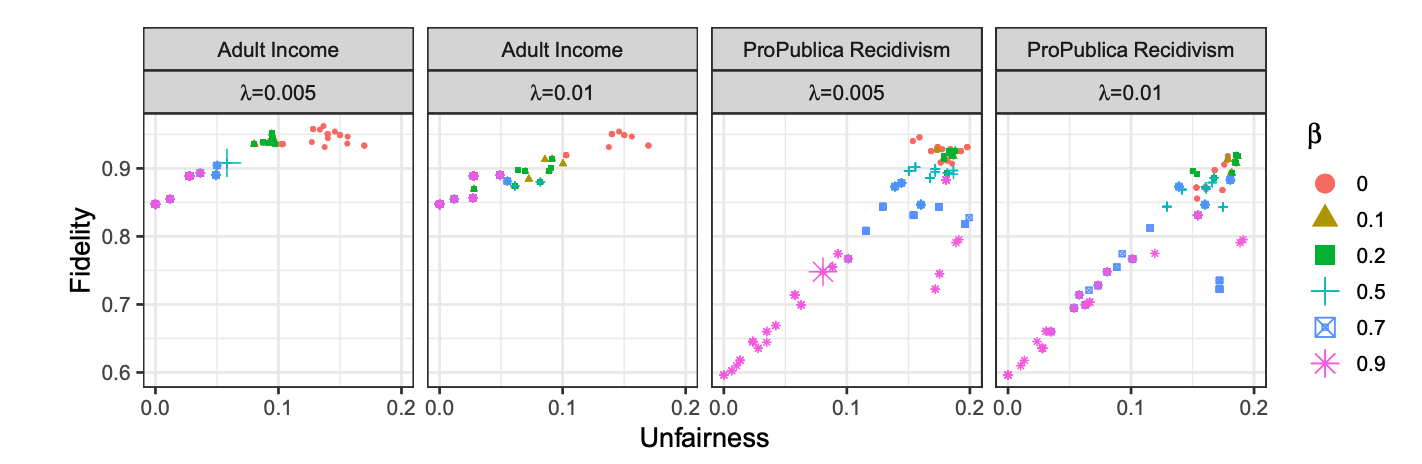
L’explication «Black-box» consiste à expliquer comment un modèle d’apprentissage automatique – dont la logique interne est cachée et généralement complexe pour l’auditeur – produit ses résultats. Les approches actuelles pour résoudre ce problème incluent l’explication du modèle, l’explication du résultat ainsi que l’inspection du modèle. Bien que ces techniques puissent être bénéfiques en fournissant une bonne interprétation, elles peuvent également être utilisées de manière négative pour effectuer du «fairwashing», un processus favorisant la fausse perception qu’un modèle d’apprentissage automatique respecte certaines valeurs éthiques. En particulier, nous démontrons qu’il est possible de rationaliser systématiquement les décisions prises par un modèle «Black-box» injuste en utilisant l’explication du modèle ainsi que les approches d’explication des résultats avec une métrique d’équité donnée. Notre solution, LaundryML, est basée sur un algorithme d’énumération de liste de règles régularisée dont l’objectif est de rechercher des listes de règles équitables se rapprochant d’un modèle injuste «Black-box». Nous évaluons de manière empirique notre technique de rationalisation sur des modèles «Black-box» formés à partir d’ensembles de données du monde réel et montrons qu’il est possible d’obtenir des listes de règles très fidèles au modèle «Black-box»tout en étant considérablement moins injustes.
