



Describing Multimedia Content using Attention-based Encoder–Decoder Networks
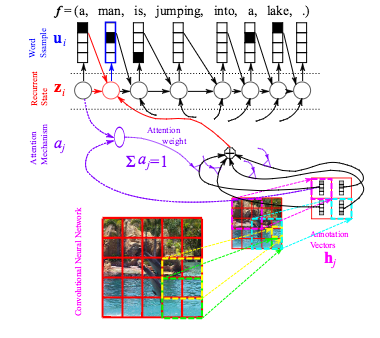
Alors que les réseaux de neurones profonds étaient principalement utilisés pour les tâches de classification, ils se développent rapidement dans le domaine des problèmes de production structurés, où la cible observée est composée de multiples variables aléatoires ayant une distribution conjointe riche, en fonction des entrées. Dans cet article, nous nous concentrons sur le cas où l’entrée a également une structure riche et où les structures d’entrée et de sortie sont en quelque sorte liées. Nous décrivons les systèmes qui apprennent à s’occuper de différents endroits dans l’entrée, pour chaque élément de la sortie, pour une variété de tâches: traduction automatique, génération de légendes d’images, description de clips vidéo et reconnaissance vocale. Tous ces systèmes reposent sur un ensemble de blocs de construction communs: des réseaux de neurones récurrents contrôlés et des réseaux de neurones de convolution, ainsi que des mécanismes d’attention formés. Nous rapportons des résultats expérimentaux avec ces systèmes, montrant une performance impressionnante et l’avantage du mécanisme d’attention.

Reference
Kyunghyun Cho, Aaron Courville and Yoshua Bengio, Describing Multimedia Content Using Attention-Based Encoder-Decoder Networks, in: IEEE Transactions on Multimedia, vol. 17, no. 11, pp. 1875-1886, 2015


