



Delving Deeper into Convolutional Networks for Learning Video Representations
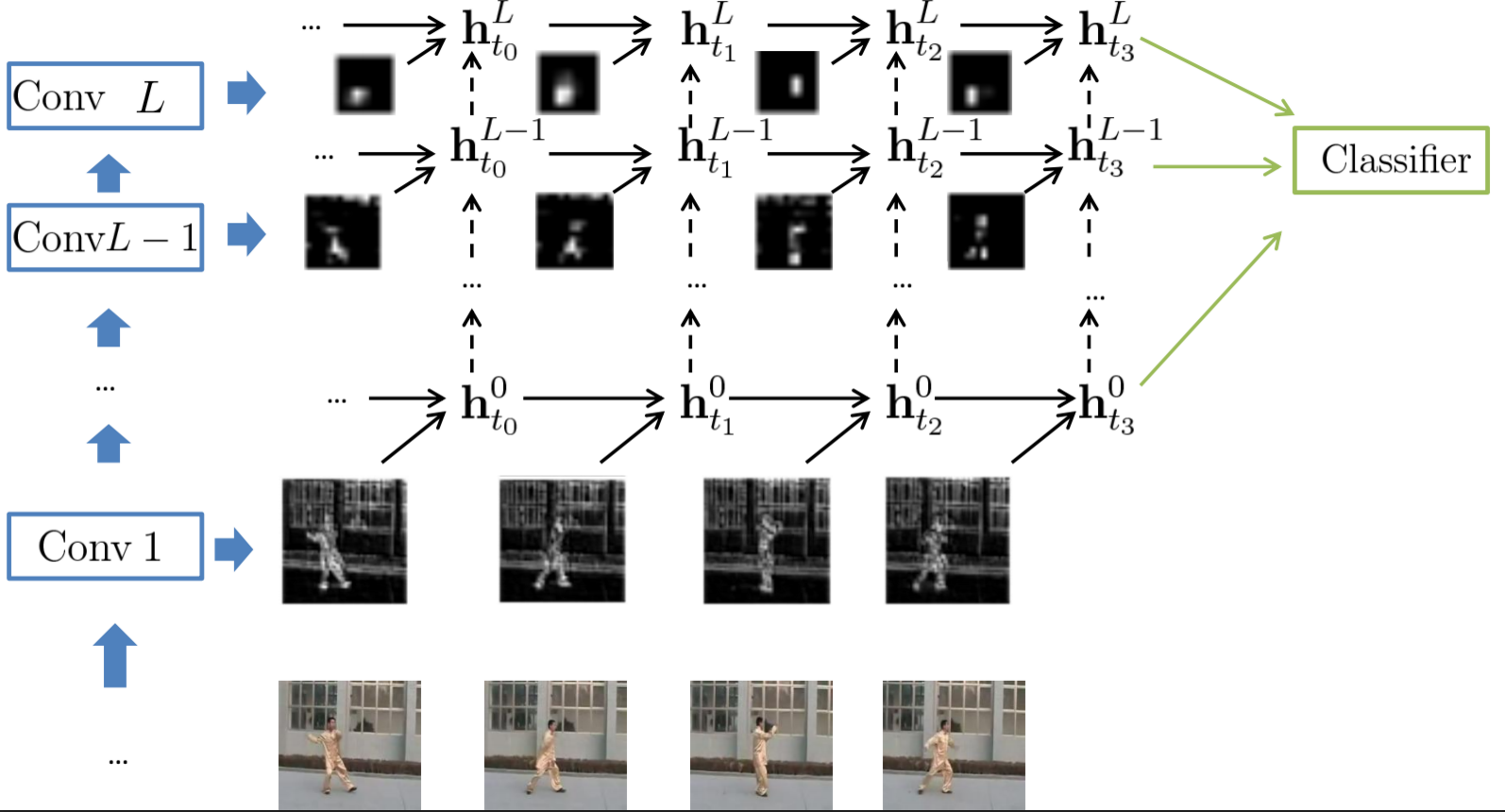
Nous proposons une approche qui vise à apprendre les caractéristiques spatio-temporelles dans les vidéos à partir de représentations visuelles intermédiaires appelées «percepts» à l’aide de réseaux récurrents Gated-Recurrent-Unit (GRU). Notre méthode repose sur des percepts extraits de tous les niveaux d’un réseau de convolution profonde formé sur le grand jeu de données ImageNet. Bien que les percepts de haut niveau contiennent des informations hautement discriminantes, ils ont tendance à avoir une résolution spatiale faible. Les percepts de bas niveau, en revanche, préservent une résolution spatiale plus élevée à partir de laquelle nous pouvons modéliser des modèles de mouvement plus fins. L’utilisation de percepts de bas niveau peut conduire à des représentations vidéo de haute dimensionnalité. Pour atténuer cet effet et contrôler le nombre de paramètres du modèle, nous introduisons une variante du modèle GRU qui exploite les opérations de convolution pour appliquer la connectivité fragmentée des unités du modèle et partager les paramètres entre les emplacements spatiaux en entrée.à
Nous validons de manière empirique notre approche pour les tâches de reconnaissance d’action humaine et de sous-titrage vidéo. En particulier, nous obtenons des résultats équivalents à l’état de la technique sur le jeu de données YouTube2Text en utilisant un modèle de décodeur de texte plus simple et sans fonctionnalités CNN 3D supplémentaires.
Reference
Aaron Courville, Christopher Pal, Nicolas Ballas, Yao Li, Delving Deeper into Convolutional Networks for Learning Video Representations, in: International Conference on Learning Representations (ICLR), 2016



