



Towards Non-saturating Recurrent Units for Modelling Long-term Dependencies
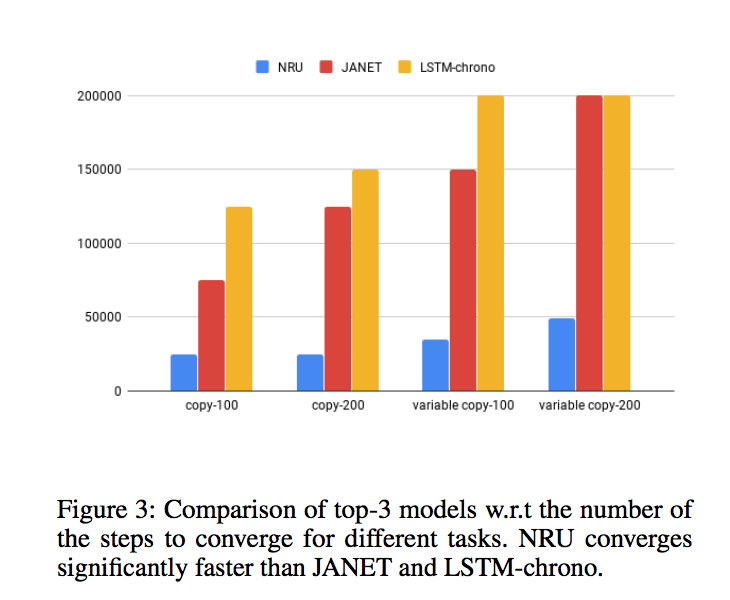
Modelling long-term dependencies is a challenge for recurrent neural networks. This is primarily due to the fact that gradients vanish during training, as the sequence length increases. Gradients can be attenuated by transition operators and are attenuated or dropped by activation functions. Canonical architectures like LSTM alleviate this issue by skipping information through a memory mechanism. We propose a new recurrent architecture (Non-saturating Recurrent Unit; NRU) that relies on a memory mechanism but forgoes both saturating activation functions and saturating gates, in order to further alleviate vanishing gradients. In a series of synthetic and real world tasks, we demonstrate that the proposed model is the only model that performs among the top 2 models across all tasks with and without long-term dependencies, when compared against a range of other architectures.




